Оценки количества нейронов и количества слоев искусственной нейронной сети [закрыт]
Я ищу способ, как рассчитать количество слоев и количество нейронов в слое. В качестве входных данных у меня есть только размер входного вектора, размер выходного вектора и размер набора учебные.
обычно лучшая сеть определяется путем попытки различных сетевых топологий и выбора одной с наименьшей ошибкой. К сожалению, я не могу этого сделать.
3 ответов
Это действительно сложная проблема.
чем больше внутренняя структура сети, тем лучше сеть будет представлять сложные решения. С другой стороны, слишком большая внутренняя структура медленнее, может привести к расхождениям в обучении или к переоснащению, что помешает вашей сети хорошо обобщать новые данные.
люди традиционно подходили к этой проблеме по-разному:
попробовать различные конфигурации, посмотрите, что работает лучше всего. вы можете разделить свой учебный набор на две части-один для обучения, один для оценки-а затем тренироваться и оценивать различные подходы. К сожалению, похоже, что в вашем случае этот экспериментальный подход недоступен.
используйте эмпирическое правило. многие люди придумали много догадок о том, что работает лучше всего. О количестве нейронов в скрытом слое, люди предположил, что (например) он должен (a) быть между размером входного и выходного слоев, (b) установить что-то около (входы+выходы) * 2/3 или (c) никогда не больше, чем в два раза больше размера входного слоя.
проблема с правилами заключается в том, что они не всегда принимать во внимание жизненно важные части информации, как "трудная" проблема, какой размер наборов тренировки и тестирования are, etc. Следовательно, эти правила часто используются как грубые отправные точки для подхода" давайте-попробуем-кучу-вещей-и-посмотрим-что-работает-лучше".используйте алгоритм, который динамически настраивает конфигурацию сети. алгоритмы, такие как Каскадной Корреляции начать с минимальной сети, затем добавьте скрытые узлы во время тренировки. Это может сделать вашу экспериментальную установку немного проще, и (в теории) может привести к лучшей производительности (потому что вы случайно не будете использовать неуместный количество скрытых узлов).
есть много исследований на эту тему - так что если вы действительно заинтересованы, есть много, чтобы прочитать. Проверьте ссылки на этот резюме в частности:
Лоуренс, С. Гиля, С. Л., Цой, А. С. (1996), "какой размер нейронной сети дает оптимальное обобщение? Свойства сходимости backpropagation". технический отчет UMIACS - TR-96-22 и CS-TR-3617, Институт перспективных компьютерных исследований, Мэрилендский университет, Колледж-Парк.
Elisseeff, A., and Paugam-Moisy, H. (1997), "размер многослойных сетей для точного обучения: аналитический подход". достижения в нейронных системах обработки информации 9, Cambridge, MA: The MIT Press, PP.162-168.
на практике это не сложно (на основе кодирования и обучения десятков MLPs).
в смысле учебника, получить архитектуру "правильно" трудно-т. е. настроить сетевую архитектуру так, чтобы производительность (разрешение) не могла быть улучшена путем дальнейшей оптимизации архитектуры, я согласен. Но только в редких случаях требуется такая степень оптимизации.
на практике, чтобы удовлетворить или превысить точность прогнозирования от нейронной сети требуемая вашей спецификацией, вам почти никогда не нужно тратить много времени на сетевую архитектуру-три причины, почему это так:
большинство параметров требуется указать сетевую архитектуру являются fixed как только вы решите на вашей модели данных (количество объекты во входном векторе, будь то желаемая переменная ответа является числовым или категориальным, и если последнее, то сколько уникальных классов ярлыки ты избранные);
несколько оставшихся параметров архитектуры, которые фактически настраиваются, почти всегда (100% времени в моем опыте) крайне ограниченном по тем фиксированной архитектуры параметры-т. е. значения этих параметров жестко ограничены значением max и min; и
оптимальная архитектура не должна быть определена раньше обучение начинается, действительно, очень часто для кода нейронной сети включать небольшой модуль для программной настройки сети архитектура во время обучения (путем удаления узлов, вес которых равен приближаются к нулю ... обычно называют "подрезка.")
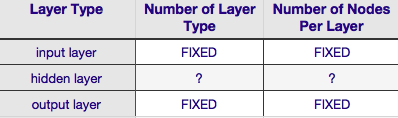
согласно приведенной выше таблице, архитектура нейронной сети полностью определяется шесть параметры (шесть ячеек во внутренней сетке). Два из них (количество типов слоев для ввода и выходные слои) всегда один и один--нейронные сети имеют один входной слой и один выходной слой. Ваш NN должен иметь по крайней мере один входной слой и один выходной слой-не больше и не меньше. Во-вторых, количество узлов, составляющих каждый из этих двух слоев, фиксировано-входной слой, по размеру входного вектора, т. е. количество узлов во входном слое равно длине входного вектора (фактически еще один нейрон почти всегда добавляется к входному слою как уклон узел).
аналогично, размер выходного слоя фиксируется переменной ответа (один узел для числовой переменной ответа и (предполагая, что используется softmax, если переменная ответа является меткой класса, число узлов в выходном слое просто равно числу уникальных меток класса).
оставляет всего два параметры, для которых существует любое усмотрение-количество скрытых слоев и количество узлов, содержащих каждый из них слои.
количество скрытых слоев
Если ваши данные линейно разделяемы (что вы часто знаете к моменту начала кодирования NN), то вам вообще не нужны скрытые слои. (Если это действительно так, я бы не использовал NN для этой проблемы-выберите более простой линейный классификатор). Первый из них-количество скрытых слоев-почти всегда один. Существует много эмпирического веса за этой презумпцией-на практике очень мало проблем это невозможно решить с помощью одного скрытого слоя, который можно решить, добавив другой скрытый слой. Аналогичным образом, существует консенсус в том, что производительность отличается от добавления дополнительных скрытых слоев: ситуации, в которых производительность улучшается со вторым (или третьим и т. д.) скрытый слой очень мал. Для большинства проблем достаточно одного скрытого слоя.
в вашем вопросе вы упомянули, что по какой-либо причине вы не можете найти оптимальную сетевую архитектуру методом проб и ошибок. Другой способ настроить конфигурацию NN (без использования проб и ошибок) -"подрезка'. Суть этого метода заключается в удалении узлов из сети во время обучения путем определения тех узлов, которые, если их удалить из сети, не будут заметно влиять на производительность сети (т. е. разрешение данных). (Даже без использования формальной техники обрезки вы можете получить приблизительное представление о том, какие узлы не важны, посмотрев на свою матрицу веса после тренировки; ищите веса, очень близкие к нулю-это узлы на обоих концах этих весов, которые часто удаляются во время обрезки.) Очевидно, что если вы используете алгоритм обрезки во время обучения, начните с конфигурации сети, которая с большей вероятностью будет иметь избыточные (т. е. "обрезаемые") узлы-другими словами, при принятии решения о сетевой архитектуре, ошибитесь на стороне большего количества нейронов, если вы добавите шаг обрезки.
другими словами, применяя алгоритм обрезки к вашей сети во время обучения, вы можете гораздо ближе к оптимизированной конфигурации сети, чем любая априорная теория когда-либо может дать вам.
количество узлов, составляющих скрытый слой
а насчет количества узлов, составляющих скрытый слой? Допустим, это значение более или менее неограниченно,т. е. оно может быть меньше или больше размера входного слоя. Помимо этого, как вы, вероятно, знаете, есть гора комментариев по вопросу о скрытом слое конфигурация в NNs (см. знаменитый NN FAQ за отличное резюме этого комментария). Есть много эмпирически выведенных эмпирических правил, но из них наиболее часто полагаются на размер скрытого слоя между входным и выходным слоями. Джефф Хитон, автор книги"введение в нейронные сети в Java " предлагает еще несколько, которые читаются на странице, которую я только что связал. Аналогично, сканирование прикладная нейросетевая литература почти наверняка покажет, что размер скрытого слоя обычно между размеры входного и выходного слоев. Но!--9-->между не означает посередине; на самом деле, обычно лучше установить размер скрытого слоя ближе к размеру входного вектора. Причина в том, что если скрытый слой слишком мал, сеть может быть трудно сближаются. Для начальной конфигурации, err на большем размере--большем скрытый слой дает Сети большую емкость, которая помогает ей сходиться, по сравнению с меньшим скрытым слоем. Действительно, это обоснование часто используется для рекомендации скрытого размера слоя больше, чем (больше узлов) входной слой--т. е. начните с начальной архитектуры, которая будет стимулировать быструю конвергенцию, после чего вы можете обрезать "лишние" узлы (определите узлы в скрытом слое с очень низкими значениями веса и устраните их из вашей пересчитанной сети).
Я использовал MLP для коммерческого программного обеспечения, которое имеет только один скрытый слой, который имеет только один узел. Поскольку входные и выходные узлы фиксированы, мне только когда-либо приходилось изменять количество скрытых слоев и играть с достигнутым обобщением. Я никогда не получал большой разницы в том, что я достигал только с одним скрытым слоем и одним узлом, изменяя количество скрытых слоев. Я просто использовал один скрытый слой с одним узлом. Он работал довольно хорошо, а также уменьшенные вычисления были очень заманчиво в моем программном обеспечении.