Очистка изображения для OCR с помощью ImageMagick и textcleaner
у меня есть следующее изображение, которое я хотел бы подготовить для OCR с tesseract:
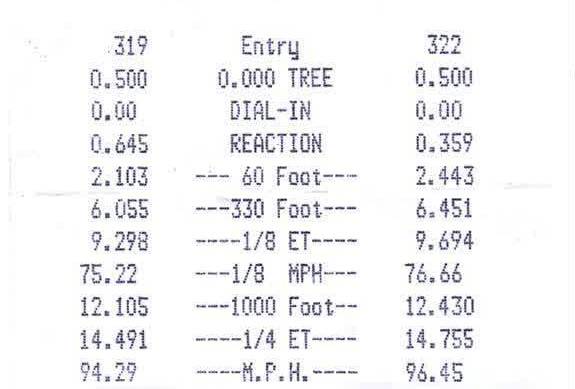
цель состоит в том, чтобы очистить изображение и удалить весь шум.
Я использую textcleaner скрипт, использующий ImageMagick со следующими параметрами:
./textcleaner -g -e normalize -f 30 -o 12 -s 2 original.jpg output.jpg
выход все еще не настолько чист:
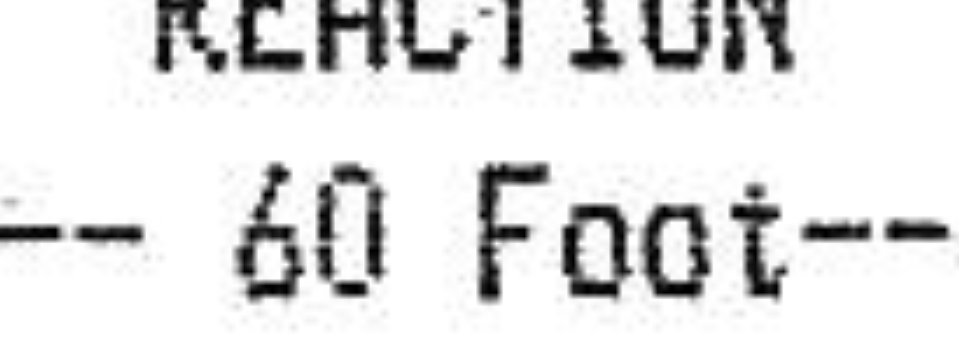
Я пробовал все виды вариаций для параметров, но не повезло. У кого-нибудь есть идея?
1 ответов
если преобразовать в в формате JPEG, вы всегда есть тип артефактов, которые вы видите.
Это типичная "особенность" сжатия JPEG. Jpeg никогда не хороши для изображений, показывающих резкие линии, контрасты с равномерными цветами между различными областями изображения, используя только очень мало цветов. Это верно для черно-белых текстов. JPEG только "хорош" для типичных фотографий, с большим количеством разных цветов и затенение...
ваша проблема, скорее всего, будет полностью решена, если вы используете PNG в качестве выходного формата. Следующее изображение демонстрирует это. Я сгенерировал его с теми же параметрами, что и ваша последняя команда примера, но с PNG в качестве выходного формата:
textcleaner -g -e normalize -f 30 -o 12 -s 2 \
http://i.stack.imgur.com/ficx7.jpg \
out.png
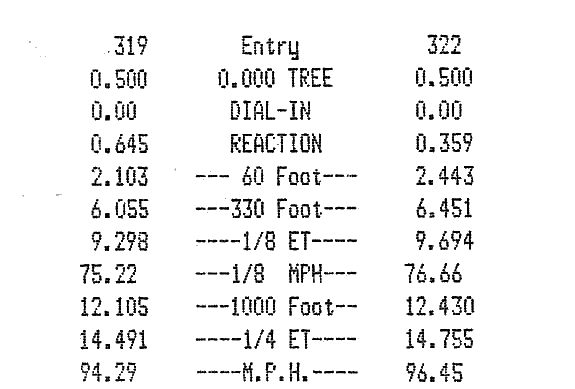
вот аналогичное увеличение выходного сигнала:
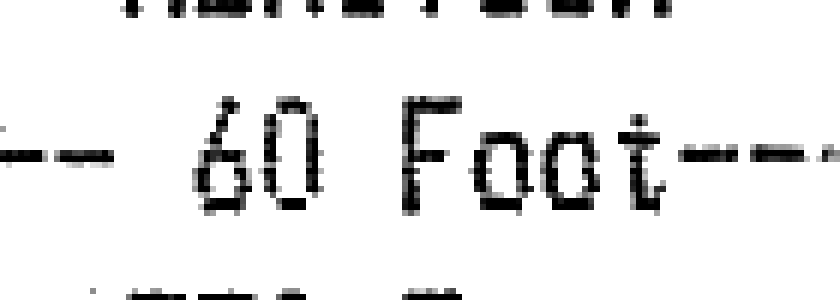
вы можете очень вероятно улучшить результат еще больше, если вы играете с параметры скрипта textcleaner. Но это код работа... :-)