Оптимальное количество нитей на ядро
предположим, у меня есть 4-ядерный процессор, и я хочу запустить некоторый процесс за минимальное количество времени. Процесс идеально распараллеливается, поэтому я могу запускать его куски на бесконечном количестве потоков, и каждый поток занимает одинаковое количество времени.
поскольку у меня есть 4 ядра, я не ожидаю ускорения, запустив больше потоков, чем ядра, так как одно ядро способно запускать только один поток в данный момент. Я не много знаю об оборудовании, так это только догадка.
есть ли польза от запуска распараллеливаемого процесса на большем количестве потоков, чем ядер? Другими словами, завершится ли мой процесс быстрее, медленнее или примерно за то же время, если я запущу его с использованием 4000 потоков, а не 4 потоков?
13 ответов
Если ваши потоки не делают ввод-вывод, синхронизацию и т. д., и больше ничего не работает, 1 поток на ядро даст вам лучшую производительность. Однако это, скорее всего, не так. Добавление большего количества потоков обычно помогает, Но через некоторое время они вызывают некоторое снижение производительности.
Не так давно я проводил тестирование производительности на четырехъядерной машине 2 под управлением ASP.NET приложение на Mono под довольно приличной нагрузкой. Мы играли с минимальным и максимальным количеством потоков и в конце концов мы выяснили, что для этого конкретного приложения в этой конкретной конфигурации лучшая пропускная способность была где-то между 36 и 40 потоками. Все, что находилось за пределами этих границ, действовало хуже. Урок? На вашем месте я бы тестировал с разным количеством потоков, пока вы не найдете правильный номер для своего приложения.
одно можно сказать наверняка: потоки 4k займут больше времени. Это много контекстных переключателей.
Я согласен с ответом @Гонсало. У меня есть процесс, который не делает ввода-вывода, и вот что я нашел:
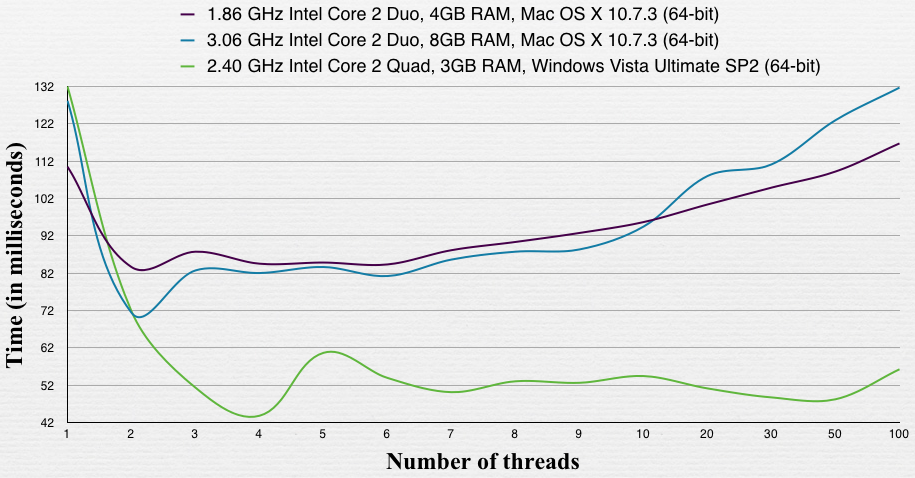
обратите внимание, что все потоки работают на одном массиве, но разные диапазоны (два потока не имеют доступа к одному индексу), поэтому результаты могут отличаться, если они работали на разных массивах.
машина 1.86-это macbook air с SSD. Другой mac-это iMac с обычным HDD (я думаю, что это 7200 rpm). Машина windows также имеет 7200 rpm ВИНЧЕСТЕР.
в этом тесте оптимальное число было равно количеству ядер в машине.
Я знаю, что этот вопрос довольно старый, но все изменилось с 2009 года.
теперь нужно учитывать две вещи: Количество ядер и количество потоков, которые могут работать внутри каждого ядра.
с процессорами Intel количество потоков определяется гиперпоточностью, которая составляет всего 2 (Когда доступна). Но Hyperthreading сокращает время выполнения на два, даже если не использует 2 потока! (т. е. трубопровод 1 разделен между двумя процессами-это хорошо когда у вас больше процессов, не так хорошо иначе. Больше ядер определенно лучше!)
на других процессорах у вас может быть 2, 4 или даже 8 потоков. Поэтому, если у вас есть 8 ядер, каждое из которых поддерживает 8 потоков, вы можете иметь 64 процесса, работающих параллельно без переключения контекста.
" нет переключения контекста", очевидно, не верно, если вы работаете со стандартной операционной системой, которая будет делать переключение контекста для всех видов других вещей из-под вашего контроля. Но это основная идея. Некоторые ОС позволяют выделять процессоры, поэтому только ваше приложение имеет доступ / использование указанного процессора!
из моего собственного опыта, если у вас много ввода/вывода, несколько потоков хорошо. Если у вас очень тяжелая работа с памятью (источник чтения 1, Источник чтения 2, быстрые вычисления, запись), то наличие большего количества потоков не помогает. Опять же, это зависит от того, сколько данных Вы читаете/пишете одновременно (т. е. если вы используете SSE 4.2 и читаете 256-битные значения, это останавливает все потоки в их шаг... другими словами, 1 поток, вероятно, намного проще реализовать и, вероятно, почти так же быстро,если не быстрее. Это будет зависеть от вашей архитектуры процесса и памяти, некоторые продвинутые серверы управляют отдельными диапазонами памяти для отдельных ядер, поэтому отдельные потоки будут быстрее, если ваши данные правильно поданы... вот почему на некоторых архитектурах 4 процесса будут работать быстрее, чем 1 процесс с 4 потоками.)
фактическая производительность будет зависеть от того, сколько добровольной отдачи будет делать каждый поток. Например, если потоки не делают ввода-вывода вообще и не используют системные службы (т. е. они связаны с 100% cpu), то 1 поток на ядро является оптимальным. Если потоки делают что-то, что требует ожидания, вам придется поэкспериментировать, чтобы определить оптимальное количество потоков. 4000 потоков потребуют значительных затрат на планирование, так что это, вероятно, тоже не оптимально.
ответ зависит от сложности алгоритмов, используемых в программе. Я придумал метод расчета оптимального количества потоков, сделав два измерения времени обработки Tn и Tm для двух произвольных чисел потоков " n " и "m". Для линейных алгоритмов оптимальным числом потоков будет N = sqrt ((mn(Tm*(n-1)-Tn*(m-1)))/(nTn-mTm) ) .
пожалуйста, прочитайте мою статью о расчетах оптимального числа для различные алгоритмы: pavelkazenin.wordpress.com
4000 потоков в одно время довольно высоки.
ответ да и нет. Если вы делаете много блокировок ввода-вывода в каждом потоке, то да, вы можете показать значительные ускорения, возможно, до 3 или 4 потоков на логическое ядро.
Если вы не делаете много блокирующих вещей, то дополнительные накладные расходы с потоковой передачей просто замедлятся. Поэтому используйте профилировщик и посмотрите, где узкие места находятся в каждой возможной параллельной части. Если вы делаете тяжелый вычисления, то более 1 потока на процессор не поможет. Если вы делаете много передачи памяти, это тоже не поможет. Если вы делаете много ввода-вывода, хотя, например, для доступа к диску или интернету, то да, несколько потоков помогут в определенной степени или, по крайней мере, сделают приложение более отзывчивым.
Я думал, что добавлю здесь еще одну перспективу. Ответ зависит от того, предполагает ли вопрос слабое масштабирование или сильное масштабирование.
с Википедия:
слабое масштабирование: как время решения зависит от количества процессоров для фиксированного размера проблемы на процессор.
сильное масштабирование: как время решения зависит от количества процессоров для фиксированного общего размера проблемы.
Если вопрос предполагает слабое масштабирование, тогда ответа @Gonzalo достаточно. Однако, если вопрос предполагает сильное масштабирование, есть что-то еще добавить. При сильном масштабировании вы предполагаете фиксированный размер рабочей нагрузки, поэтому при увеличении количества потоков размер данных, над которыми должен работать каждый поток, уменьшается. На современных процессорах доступ к памяти дорог и предпочтительнее поддерживать локальность, сохраняя данные в кэшах. Таким образом, вероятное оптимальное количество потоков может быть найдено когда набор данных каждого потока помещается в кэш каждого ядра (Я не буду вдаваться в детали обсуждения того, является ли это кэш (ы) L1/L2/L3 системы).
Это справедливо, даже если количество потоков превышает количество ядер. Например, предположим, что в программе есть 8 произвольных единиц (или AU) работы, которые будут выполняться на 4-ядерном компьютере.
Пример 1: run с четырьмя потоками, где каждый поток должен полное 2AU. Каждый поток занимает 10s для завершения (много промахов кэша). С четырьмя ядрами общее количество времени будет 10С (10С * 4 потока / 4 ядра).
Пример 2: run с восемью потоками, где каждый поток должен завершить 1AU. Каждый поток принимает только 2s (вместо 5s из-за уменьшенное количество пропусков кэша). С восемью ядрами общее количество времени будет 4s (2S * 8 потоков / 4 начинка.)
я упростил проблему и проигнорировал накладные расходы, упомянутые в других ответах (например, контекстные переключатели), но надеюсь, что вы поймете, что может быть полезно иметь больше потоков, чем доступное количество ядер, в зависимости от размера данных, с которыми вы имеете дело.
Benchmark.
Я бы начал наращивать количество потоков для приложения, начиная с 1, а затем перейти к чему-то вроде 100, запустить три-пять испытаний для каждого количества потоков и построить себе график скорости работы против количества потоков.
вы должны, Чтобы случай четырех потоков был оптимальным, с небольшими повышениями во время выполнения после этого, но, возможно, нет. Возможно, ваше приложение ограничено пропускной способностью, т. е. набор данных, который вы загружаете в память, огромен, вы получаете много пропусков кэша и т. д., Так что 2 потока являются оптимальными.
вы не можете знать, пока вы не проверить.
вы найдете, сколько потоков вы можете запустить на своем компьютере, запустив htop или ps команду, которая возвращает количество процессов на вашем компьютере.
вы можете использовать man-страницу о команде "ps".
man ps
если вы хотите рассчитать количество всех пользователей процесса, вы можете использовать одну из следующих команд:
-
ps -aux| wc -l ps -eLf | wc -l
вычисление номера пользователя процесс:
ps --User root | wc -l
кроме того, вы можете использовать "htop" [ссылка]:
установка на Ubuntu или Debian:
sudo apt-get install htop
установка на Redhat или CentOS:
yum install htop
dnf install htop [On Fedora 22+ releases]
если вы хотите скомпилировать htop из исходного кода, Вы найдете его здесь.
идеал-1 поток на ядро, если ни один из потоков не будет блокировать.
один случай, когда это может быть неверно: на ядре работают другие потоки, и в этом случае больше потоков может дать вашей программе больший кусок времени выполнения.
одним из примеров множества потоков ("пул потоков") против одного на ядро является реализация веб-сервера в Linux или в Windows.
поскольку сокеты опрашиваются в Linux, многие потоки могут увеличить вероятность того, что один из них опросит правильный сокет в нужное время, но общая стоимость обработки будет очень высокой.
в Windows сервер будет реализован с использованием портов завершения ввода-вывода-IOCPs - что сделает приложение управляемым событием: если ввод-вывод завершает ОС запускает резервный поток для его обработки. Когда обработка завершена (обычно с другой операцией ввода-вывода, Как в паре запрос-ответ), поток возвращается к порту IOCP (очереди), чтобы дождаться следующего завершения.
Если ввод-вывод не завершен, обработка не выполняется и поток не запускается.
действительно, Microsoft рекомендует не более одного потока на ядро в реализациях IOCP. Любой I / O может быть прикреплен к механизму IOCP. МОК может также будет размещено приложение, если это необходимо.
говоря с точки зрения вычислений и памяти (научные вычисления) 4000 потоков заставят приложение работать очень медленно. Частью проблемы является очень высокие накладные расходы на переключение контекста и, скорее всего, очень плохая локальность памяти.
но это также зависит от вашей архитектуры. Откуда я слышал, что процессоры Niagara предположительно могут обрабатывать несколько потоков на одном ядре, используя какую-то передовую технику конвейеризации. Однако у меня нет опыта с этими процессорами.
надеюсь, что это имеет смысл, Проверьте использование процессора и памяти и поместите некоторое пороговое значение. Если пороговое значение пересечено, не разрешайте создавать новый поток else allow...