Оптимальное (транслируемое) матричное деление в numpy. Избегать временных массивов или нет?
Numpy позволяет добавлять/умножать/делить матрицы разных размеров при условии, что определенные правила вещания есть. Кроме того, создание временные массивы является основным препятствием скорости для numpy.
следующие результаты timit удивляют меня...что происходит?
In [41]: def f_no_dot(mat,arr):
....: return mat/arr
In [42]: def f_dot(mat,arr):
....: denominator = scipy.dot(arr, scipy.ones((1,2)))
....: return mat/denominator
In [43]: mat = scipy.rand(360000,2)
In [44]: arr = scipy.rand(360000,1)
In [45]: timeit temp = f_no_dot(mat,arr)
10 loops, best of 3: 44.7 ms per loop
In [46]: timeit temp = f_dot(mat,arr)
100 loops, best of 3: 10.1 ms per loop
Я думал, что f_dot будет медленнее, так как он должен был создать временный знаменатель массива, и я предположил, что этот шаг был пропущен f_no_dot. Я следует отметить, что эти времена масштабируются линейно (с размером массива, до длины 1 млрд) для f_no_dot и немного хуже, чем линейные для f_dot.
2 ответов
то, что вы видите, скорее всего, итерация накладных расходов над небольшим (2,) измерение. Numpy (версии прилежащей массивы (той же формы). Эффект исчезает по мере увеличения размера последнего измерения.
чтобы увидеть эффект примыкания:
Однако ситуация значительно улучшилась в Numpy >= 1.6.0:
(Все тайминги выше, вероятно, только с точностью до 1 ms.)
Обратите также внимание, что временные не являются это дорого:
In [82]: %timeit arr_cont1.copy()
1000 loops, best of 3: 778 us per loop
редактировать: обратите внимание, что кроме arr_noncont является своего рода смежным с шагом 2*itemsize, так что внутренний цикл может быть распутан --- Numpy может сделать его примерно так же быстро, как смежный массив. С вещанием (или с действительно несмежным массивом, таким как numpy.random.rand(360000*2, 2)[::2,:], внутренний цикл не может быть распутан, и эти случаи немного медленнее. Улучшение все равно будет возможно, если Numpy испускает индивидуальный машинный код на лету для каждого цикла, но он этого не делает (по крайней мере, пока :)
я думал, что f_dot будет медленнее, так как он должен был создать временный знаменатель массива, и я предположил, что этот шаг был пропущен f_no_dot.
для чего это стоит, создание временного массива is пропущено, вот почему f_no_dot медленнее (но использует меньше памяти).
элементарные операции с массивами одинакового размера быстрее, потому что numpy не нужно беспокоиться о шагах (размерах, размере и т. д.) матрица.
операции, которые используют вещание, как правило, будут немного медленнее, чем операции, которые не должны.
если у вас есть память, чтобы сэкономить, создавая временную копию может дать вам ускорение, но будет использовать больше памяти.
например, сравнивая эти три функции:
import numpy as np
import timeit
def f_no_dot(x, y):
return x / y
def f_dot(x, y):
denom = np.dot(y, np.ones((1,2)))
return x / denom
def f_in_place(x, y):
x /= y
return x
num = 3600000
x = np.ones((num, 2))
y = np.ones((num, 1))
for func in ['f_dot', 'f_no_dot', 'f_in_place']:
t = timeit.timeit('%s(x,y)' % func, number=100,
setup='from __main__ import x,y,f_dot, f_no_dot, f_in_place')
print func, 'time...'
print t / 100.0
это дает аналогичные тайминги для ваших результатов:
f_dot time...
0.184361531734
f_no_dot time...
0.619203259945
f_in_place time...
0.585789341927
однако, если мы сравним использование памяти, вещи становятся немного более ясный...
общий размер наш!--3--> и y arrays составляет около 27,5 + 55 Мб, или 82 МБ (для 64-битных ints). Существует дополнительный ~ 11 Мб накладных расходов в импорте numpy и т. д.
возвращение x / y как новый массив (т. е. не делать x /= y) потребуется еще 55 МБ массива.
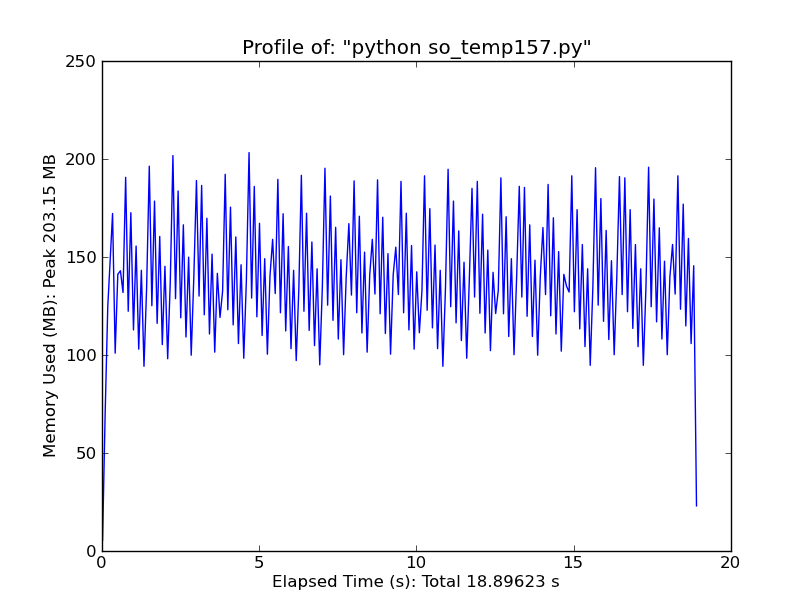
100 запусков f_dot:
Мы создаем здесь временный массив, поэтому мы ожидаем увидеть 11 + 82 + 55 + 55 Мб или ~203 МБ использования памяти. И, вот что мы видим...
100 запусков f_no_dot:
Если временный массив не создается, мы ожидаем пиковое использование памяти 11 + 82 + 55 Мб, или 148 МБ...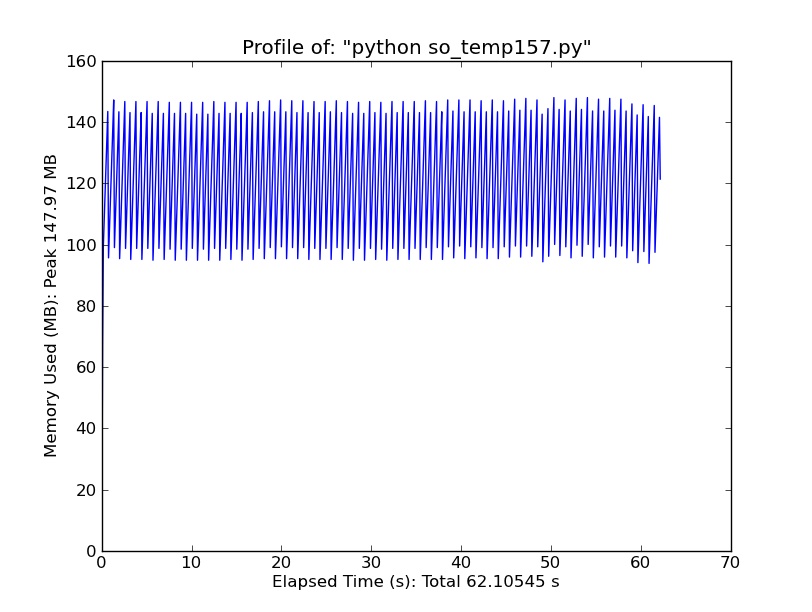 ...именно это мы и видим.
...именно это мы и видим.
и x / y is не создание дополнительного num x 2 временный массив для разделения.
таким образом, разделение занимает немного больше времени, чем если бы оно работало на двух массивах одного и того же размер.
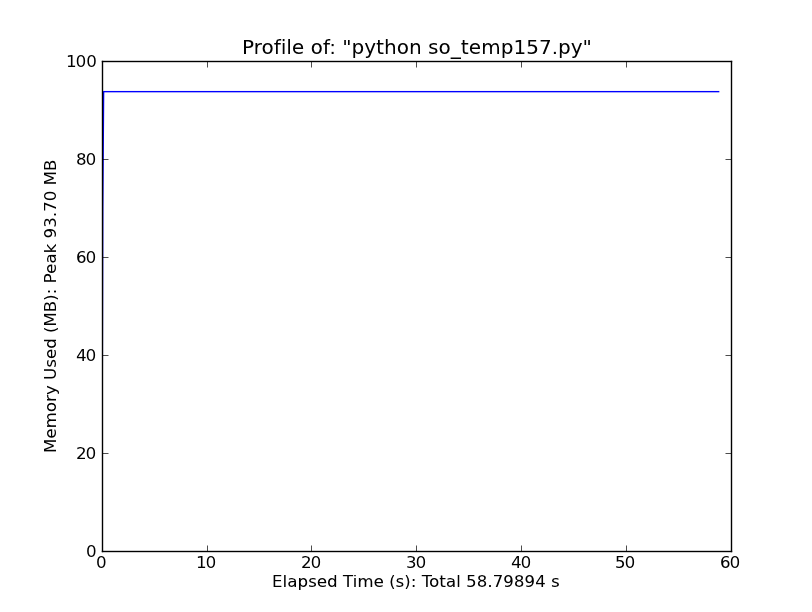
100 запусков f_in_place:
Если мы можем изменить x на месте, мы можем сохранить даже больше памяти, если это главная забота.
в основном, numpy пытается сохранить память за счет скорости, в некоторых случаях.