Oracle не использует индекс при присоединении
Я очень новичок в индексировании и объяснении планов, поэтому, пожалуйста, потерпите со мной! Я пытаюсь настроить запрос, но у меня проблемы.
у меня есть две таблицы:
SKU
------
SKUIDX (Unique index)
CLRIDX (Index)
..
..
IMPCOST_CLR
-----------
ICCIDX (Unique index)
CLRIDX (Index)
...
..
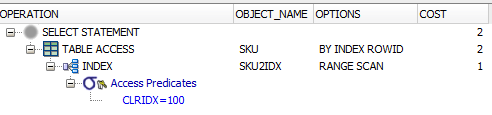
когда я делаю select * from SKU where clridx = 122, Я вижу, что он использует индекс в плане объяснения (он говорит доступ к таблице.. Индекс, он говорит имя индекса под OBJECT_NAME, а параметры-сканирование диапазона).
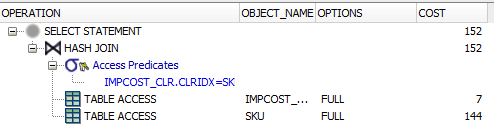
теперь, когда я пытаюсь присоединиться к тому же полю, он, похоже, не использует индекс (он говорит доступ к таблице.. Хэш-соединение и под параметрами, он говорит FULL).
что я должен искать, чтобы попытаться понять, почему он не использует индекс? Извините, я не уверен, какие команды ввести, чтобы показать это, поэтому, пожалуйста, дайте мне знать, если вам нужна дополнительная информация.
примеры:
1-й запрос:
SELECT
*
FROM
AP21.SKU
WHERE
CLRIDX = 100
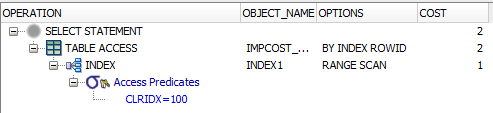
2-й запрос:
SELECT
*
FROM
AP21.IMPCOST_CLR
WHERE
CLRIDX = 100
3-й запрос:
SELECT
*
FROM
AP21.SKU
INNER JOIN
AP21.IMPCOST_CLR ON
IMPCOST_CLR.CLRIDX = SKU.CLRIDX
2 ответов
смотреть на этот запрос:
SELECT
*
FROM
AP21.SKU
INNER JOIN
AP21.IMPCOST_CLR ON
IMPCOST_CLR.CLRIDX = SKU.CLRIDX
он не имеет дополнительных предикатов. Таким образом, вы соединяете все строки в SKU со всеми строками в IMPCOST_CLR. Кроме того, вы выбираете все столбцы из обеих таблиц.
Это означает, что Oracle должен прочитать всю обе таблицы. Самый эффективный способ сделать это-использовать полное сканирование таблицы, собрать все строки в многоблочных считываниях и использовать хэширование для соответствия значениям объединения.
в основном, это операция набора, что SQL делает очень хорошо, тогда как индексированные чтения больше в стиле rbar. Теперь, если вы изменили третий запрос, чтобы включить дополнительный предикат, такой как
WHERE SKU.CLRIDX = 100
вы, скорее всего, увидите, что путь доступа вернется к сканированию диапазона индексов . Поскольку вы выбираете только сравнительную горстку строк, индексированное чтение снова является более эффективным путем.
" запрос im пытается настроить сотни много дольше, но ломается его и принимая его шаг за шагом! "
это хорошая техника, но вам нужно понять, как работает Oracle optimzer. В плане объяснений много информации. узнать больше. обратите внимание на значение
теперь, когда я пытаюсь присоединиться к тому же полю, он не появляется чтобы использовать индекс(он говорит доступ к таблице.. Хэш-соединение и под варианты, он говорит полный).
это потому, что хэш-соединение не использует (необходимые) индексы для предикатов соединения:
http://use-the-index-luke.com/sql/join/hash-join-partial-objects