Ошибки (стирания+ошибки) Berlekamp-Massey для декодирования Рида-Соломона
Я пытаюсь реализовать кодер-декодер Рида-Соломона в Python, поддерживающий декодирование как стираний, так и ошибок, и это сводит меня с ума.
реализация в настоящее время поддерживает декодирование только ошибок или только стираний, но не обоих одновременно (даже если это ниже теоретической границы 2*ошибок+стираний
из бумаги Блейхута (здесь и здесь), похоже, нам нужно только инициализировать ошибку полином локатора с полиномом локатора стирания для неявного вычисления полинома локатора ошибок внутри Берлекампа-Масси.
этот подход частично работает для меня: когда у меня 2*ошибки+подчисток
однако, когда мы идем выше (n-k)/2, например, если n = 20 и k = 11, таким образом, у нас есть (n-k)=9 стираемых символов, которые мы можем исправить, если мы подаем в 5 стираний, то BM просто идет неправильно. Если мы подаем в 4 стирания + 1 ошибка (мы все еще значительно ниже границы, так как у нас есть 2 * ошибки+стирания = 2+4 = 6
точный алгоритм Berlekamp-Massey я реализовал можно найти в презентации (стр. 15-17), но очень похожее описание можно найти здесь и здесь, а вот прилагаю копию математического описания:

Теперь у меня есть почти точное воспроизведение этого математического алгоритма в код Python. Я хотел бы расширить его для поддержки стираний, которые я попытался инициализировать Сигма локатора ошибок с помощью локатор стирания:
def _berlekamp_massey(self, s, k=None, erasures_loc=None):
'''Computes and returns the error locator polynomial (sigma) and the
error evaluator polynomial (omega).
If the erasures locator is specified, we will return an errors-and-erasures locator polynomial and an errors-and-erasures evaluator polynomial.
The parameter s is the syndrome polynomial (syndromes encoded in a
generator function) as returned by _syndromes. Don't be confused with
the other s = (n-k)/2
Notes:
The error polynomial:
E(x) = E_0 + E_1 x + ... + E_(n-1) x^(n-1)
j_1, j_2, ..., j_s are the error positions. (There are at most s
errors)
Error location X_i is defined: X_i = a^(j_i)
that is, the power of a corresponding to the error location
Error magnitude Y_i is defined: E_(j_i)
that is, the coefficient in the error polynomial at position j_i
Error locator polynomial:
sigma(z) = Product( 1 - X_i * z, i=1..s )
roots are the reciprocals of the error locations
( 1/X_1, 1/X_2, ...)
Error evaluator polynomial omega(z) is here computed at the same time as sigma, but it can also be constructed afterwards using the syndrome and sigma (see _find_error_evaluator() method).
'''
# For errors-and-erasures decoding, see: Blahut, Richard E. "Transform techniques for error control codes." IBM Journal of Research and development 23.3 (1979): 299-315. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.92.600&rep=rep1&type=pdf and also a MatLab implementation here: http://www.mathworks.com/matlabcentral/fileexchange/23567-reed-solomon-errors-and-erasures-decoder/content//RS_E_E_DEC.m
# also see: Blahut, Richard E. "A universal Reed-Solomon decoder." IBM Journal of Research and Development 28.2 (1984): 150-158. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.84.2084&rep=rep1&type=pdf
# or alternatively see the reference book by Blahut: Blahut, Richard E. Theory and practice of error control codes. Addison-Wesley, 1983.
# and another good alternative book with concrete programming examples: Jiang, Yuan. A practical guide to error-control coding using Matlab. Artech House, 2010.
n = self.n
if not k: k = self.k
# Initialize:
if erasures_loc:
sigma = [ Polynomial(erasures_loc.coefficients) ] # copy erasures_loc by creating a new Polynomial
B = [ Polynomial(erasures_loc.coefficients) ]
else:
sigma = [ Polynomial([GF256int(1)]) ] # error locator polynomial. Also called Lambda in other notations.
B = [ Polynomial([GF256int(1)]) ] # this is the error locator support/secondary polynomial, which is a funky way to say that it's just a temporary variable that will help us construct sigma, the error locator polynomial
omega = [ Polynomial([GF256int(1)]) ] # error evaluator polynomial. We don't need to initialize it with erasures_loc, it will still work, because Delta is computed using sigma, which itself is correctly initialized with erasures if needed.
A = [ Polynomial([GF256int(0)]) ] # this is the error evaluator support/secondary polynomial, to help us construct omega
L = [ 0 ] # necessary variable to check bounds (to avoid wrongly eliminating the higher order terms). For more infos, see https://www.cs.duke.edu/courses/spring11/cps296.3/decoding_rs.pdf
M = [ 0 ] # optional variable to check bounds (so that we do not mistakenly overwrite the higher order terms). This is not necessary, it's only an additional safe check. For more infos, see the presentation decoding_rs.pdf by Andrew Brown in the doc folder.
# Polynomial constants:
ONE = Polynomial(z0=GF256int(1))
ZERO = Polynomial(z0=GF256int(0))
Z = Polynomial(z1=GF256int(1)) # used to shift polynomials, simply multiply your poly * Z to shift
s2 = ONE + s
# Iteratively compute the polynomials 2s times. The last ones will be
# correct
for l in xrange(0, n-k):
K = l+1
# Goal for each iteration: Compute sigma[K] and omega[K] such that
# (1 + s)*sigma[l] == omega[l] in mod z^(K)
# For this particular loop iteration, we have sigma[l] and omega[l],
# and are computing sigma[K] and omega[K]
# First find Delta, the non-zero coefficient of z^(K) in
# (1 + s) * sigma[l]
# This delta is valid for l (this iteration) only
Delta = ( s2 * sigma[l] ).get_coefficient(l+1) # Delta is also known as the Discrepancy, and is always a scalar (not a polynomial).
# Make it a polynomial of degree 0, just for ease of computation with polynomials sigma and omega.
Delta = Polynomial(x0=Delta)
# Can now compute sigma[K] and omega[K] from
# sigma[l], omega[l], B[l], A[l], and Delta
sigma.append( sigma[l] - Delta * Z * B[l] )
omega.append( omega[l] - Delta * Z * A[l] )
# Now compute the next B and A
# There are two ways to do this
# This is based on a messy case analysis on the degrees of the four polynomials sigma, omega, A and B in order to minimize the degrees of A and B. For more infos, see https://www.cs.duke.edu/courses/spring10/cps296.3/decoding_rs_scribe.pdf
# In fact it ensures that the degree of the final polynomials aren't too large.
if Delta == ZERO or 2*L[l] > K
or (2*L[l] == K and M[l] == 0):
# Rule A
B.append( Z * B[l] )
A.append( Z * A[l] )
L.append( L[l] )
M.append( M[l] )
elif (Delta != ZERO and 2*L[l] < K)
or (2*L[l] == K and M[l] != 0):
# Rule B
B.append( sigma[l] // Delta )
A.append( omega[l] // Delta )
L.append( K - L[l] )
M.append( 1 - M[l] )
else:
raise Exception("Code shouldn't have gotten here")
return sigma[-1], omega[-1]
полиномы и GF256int являются общей реализацией, соответственно, полиномов и полей Галуа над 2^8. Эти классы проходят модульное тестирование и, как правило, являются доказательством ошибок. То же самое касается остальных методов кодирования/декодирования для Рида-Соломона, таких как Forney и Chien search. Полный код с быстрого теста для вопроса, я говорю, можно найти здесь: http://codepad.org/l2Qi0y8o
вот пример вывод:
Encoded message:
hello world�ꐙ�Ī`>
-------
Erasures decoding:
Erasure locator: 189x^5 + 88x^4 + 222x^3 + 33x^2 + 251x + 1
Syndrome: 149x^9 + 113x^8 + 29x^7 + 231x^6 + 210x^5 + 150x^4 + 192x^3 + 11x^2 + 41x
Sigma: 189x^5 + 88x^4 + 222x^3 + 33x^2 + 251x + 1
Symbols positions that were corrected: [19, 18, 17, 16, 15]
('Decoded message: ', 'hello world', 'xcexeax90x99x8dxc4xaa`>')
Correctly decoded: True
-------
Errors+Erasures decoding for the message with only erasures:
Erasure locator: 189x^5 + 88x^4 + 222x^3 + 33x^2 + 251x + 1
Syndrome: 149x^9 + 113x^8 + 29x^7 + 231x^6 + 210x^5 + 150x^4 + 192x^3 + 11x^2 + 41x
Sigma: 101x^10 + 139x^9 + 5x^8 + 14x^7 + 180x^6 + 148x^5 + 126x^4 + 135x^3 + 68x^2 + 155x + 1
Symbols positions that were corrected: [187, 141, 90, 19, 18, 17, 16, 15]
('Decoded message: ', 'xf4x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00.x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00Px00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00x00xe3xe6xffO> world', 'xcexeax90x99x8dxc4xaa`>')
Correctly decoded: False
-------
Errors+Erasures decoding for the message with erasures and one error:
Erasure locator: 77x^4 + 96x^3 + 6x^2 + 206x + 1
Syndrome: 49x^9 + 107x^8 + x^7 + 109x^6 + 236x^5 + 15x^4 + 8x^3 + 133x^2 + 243x
Sigma: 38x^9 + 98x^8 + 239x^7 + 85x^6 + 32x^5 + 168x^4 + 92x^3 + 225x^2 + 22x + 1
Symbols positions that were corrected: [19, 18, 17, 16]
('Decoded message: ', "xdaxe1'xccA world", 'xcexeax90x99x8dxc4xaa`>')
Correctly decoded: False
здесь декодирование стирания всегда правильно, так как оно вообще не использует BM для вычисления локатора стирания. Обычно два других тестовых случая должны выводить одну и ту же Сигму, но они просто этого не делают.
тот факт, что проблема исходит от BM, очевиден здесь, когда вы сравниваете первые два тестовых случая: синдром и локатор стирания одинаковы, но результирующая Сигма совершенно другая (во втором тесте используется BM, в то время как в первом тестовый случай со стираниями только БМ не называется).
большое спасибо за любую помощь или идеи о том, как я могу отлаживать это. Обратите внимание, что ваши ответы могут быть математическими или кодовыми, но, пожалуйста, объясните, что пошло не так с моим подходом.
/ EDIT: все еще не нашел, как правильно реализовать декодер ошибок BM (см. Мой ответ ниже). Щедрость предлагается всем, кто может исправить проблему (или, по крайней мере, направить меня к решение.)
/EDIT2: глупый я, извините, я просто перечитал схему и обнаружил, что пропустил изменение в задании L = r - L - erasures_count... Я обновил код, чтобы исправить это и вновь принял мой ответ.
2 ответов
после прочтения многих и многих исследовательских работ и книг, единственное место, где я нашел ответ в книге (читаемый онлайн в Google книгах, но не доступен в формате PDF):
"алгебраические коды для передачи данных", Blahut, Richard E., 2003, Cambridge university press.
вот некоторые выдержки из этой книги, детали которой являются точными (за исключением матричного / векторизованного представления полинома операции) описание алгоритма Берлекэмпа-Масси, который я реализовал:
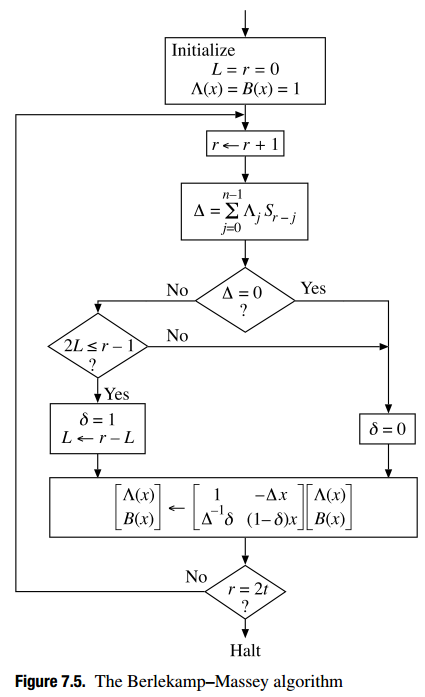
и вот ошибки (ошибки и стирания) алгоритм Берлекэмпа-Масси для Рида-Соломона:
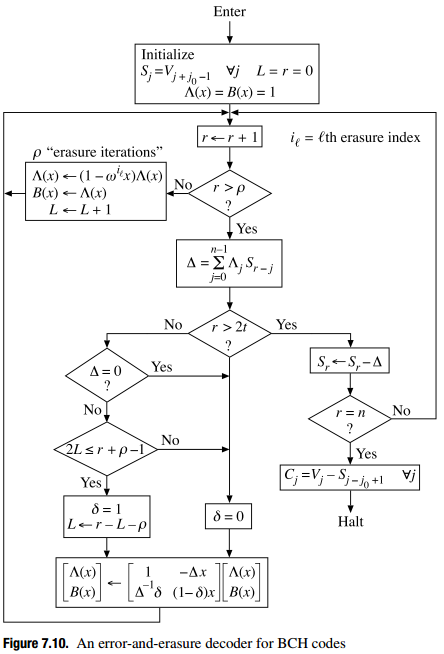
как вы видите, вопреки обычному описанию, что вы только необходимо инициализировать лямбда, полином локатора ошибок, со значением ранее вычисленного полинома локатора стираний -- вам также нужно пропустить первые V итераций, где v-число стираний. Обратите внимание, что это не эквивалентно пропуска последних итераций в: вам нужно пропустить первые V итераций, потому что r (счетчик итераций, K в моей реализации) используется не только для подсчета итераций, но и для генерации правильного Дельта фактора несоответствия.
вот результирующий код с изменениями для поддержки стираний, а также ошибок до v+2*e <= (n-k):
def _berlekamp_massey(self, s, k=None, erasures_loc=None, erasures_eval=None, erasures_count=0):
'''Computes and returns the errata (errors+erasures) locator polynomial (sigma) and the
error evaluator polynomial (omega) at the same time.
If the erasures locator is specified, we will return an errors-and-erasures locator polynomial and an errors-and-erasures evaluator polynomial, else it will compute only errors. With erasures in addition to errors, it can simultaneously decode up to v+2e <= (n-k) where v is the number of erasures and e the number of errors.
Mathematically speaking, this is equivalent to a spectral analysis (see Blahut, "Algebraic Codes for Data Transmission", 2003, chapter 7.6 Decoding in Time Domain).
The parameter s is the syndrome polynomial (syndromes encoded in a
generator function) as returned by _syndromes.
Notes:
The error polynomial:
E(x) = E_0 + E_1 x + ... + E_(n-1) x^(n-1)
j_1, j_2, ..., j_s are the error positions. (There are at most s
errors)
Error location X_i is defined: X_i = α^(j_i)
that is, the power of α (alpha) corresponding to the error location
Error magnitude Y_i is defined: E_(j_i)
that is, the coefficient in the error polynomial at position j_i
Error locator polynomial:
sigma(z) = Product( 1 - X_i * z, i=1..s )
roots are the reciprocals of the error locations
( 1/X_1, 1/X_2, ...)
Error evaluator polynomial omega(z) is here computed at the same time as sigma, but it can also be constructed afterwards using the syndrome and sigma (see _find_error_evaluator() method).
It can be seen that the algorithm tries to iteratively solve for the error locator polynomial by
solving one equation after another and updating the error locator polynomial. If it turns out that it
cannot solve the equation at some step, then it computes the error and weights it by the last
non-zero discriminant found, and delays the weighted result to increase the polynomial degree
by 1. Ref: "Reed Solomon Decoder: TMS320C64x Implementation" by Jagadeesh Sankaran, December 2000, Application Report SPRA686
The best paper I found describing the BM algorithm for errata (errors-and-erasures) evaluator computation is in "Algebraic Codes for Data Transmission", Richard E. Blahut, 2003.
'''
# For errors-and-erasures decoding, see: "Algebraic Codes for Data Transmission", Richard E. Blahut, 2003 and (but it's less complete): Blahut, Richard E. "Transform techniques for error control codes." IBM Journal of Research and development 23.3 (1979): 299-315. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.92.600&rep=rep1&type=pdf and also a MatLab implementation here: http://www.mathworks.com/matlabcentral/fileexchange/23567-reed-solomon-errors-and-erasures-decoder/content//RS_E_E_DEC.m
# also see: Blahut, Richard E. "A universal Reed-Solomon decoder." IBM Journal of Research and Development 28.2 (1984): 150-158. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.84.2084&rep=rep1&type=pdf
# and another good alternative book with concrete programming examples: Jiang, Yuan. A practical guide to error-control coding using Matlab. Artech House, 2010.
n = self.n
if not k: k = self.k
# Initialize, depending on if we include erasures or not:
if erasures_loc:
sigma = [ Polynomial(erasures_loc.coefficients) ] # copy erasures_loc by creating a new Polynomial, so that we initialize the errata locator polynomial with the erasures locator polynomial.
B = [ Polynomial(erasures_loc.coefficients) ]
omega = [ Polynomial(erasures_eval.coefficients) ] # to compute omega (the evaluator polynomial) at the same time, we also need to initialize it with the partial erasures evaluator polynomial
A = [ Polynomial(erasures_eval.coefficients) ] # TODO: fix the initial value of the evaluator support polynomial, because currently the final omega is not correct (it contains higher order terms that should be removed by the end of BM)
else:
sigma = [ Polynomial([GF256int(1)]) ] # error locator polynomial. Also called Lambda in other notations.
B = [ Polynomial([GF256int(1)]) ] # this is the error locator support/secondary polynomial, which is a funky way to say that it's just a temporary variable that will help us construct sigma, the error locator polynomial
omega = [ Polynomial([GF256int(1)]) ] # error evaluator polynomial. We don't need to initialize it with erasures_loc, it will still work, because Delta is computed using sigma, which itself is correctly initialized with erasures if needed.
A = [ Polynomial([GF256int(0)]) ] # this is the error evaluator support/secondary polynomial, to help us construct omega
L = [ 0 ] # update flag: necessary variable to check when updating is necessary and to check bounds (to avoid wrongly eliminating the higher order terms). For more infos, see https://www.cs.duke.edu/courses/spring11/cps296.3/decoding_rs.pdf
M = [ 0 ] # optional variable to check bounds (so that we do not mistakenly overwrite the higher order terms). This is not necessary, it's only an additional safe check. For more infos, see the presentation decoding_rs.pdf by Andrew Brown in the doc folder.
# Fix the syndrome shifting: when computing the syndrome, some implementations may prepend a 0 coefficient for the lowest degree term (the constant). This is a case of syndrome shifting, thus the syndrome will be bigger than the number of ecc symbols (I don't know what purpose serves this shifting). If that's the case, then we need to account for the syndrome shifting when we use the syndrome such as inside BM, by skipping those prepended coefficients.
# Another way to detect the shifting is to detect the 0 coefficients: by definition, a syndrome does not contain any 0 coefficient (except if there are no errors/erasures, in this case they are all 0). This however doesn't work with the modified Forney syndrome (that we do not use in this lib but it may be implemented in the future), which set to 0 the coefficients corresponding to erasures, leaving only the coefficients corresponding to errors.
synd_shift = 0
if len(s) > (n-k): synd_shift = len(s) - (n-k)
# Polynomial constants:
ONE = Polynomial(z0=GF256int(1))
ZERO = Polynomial(z0=GF256int(0))
Z = Polynomial(z1=GF256int(1)) # used to shift polynomials, simply multiply your poly * Z to shift
# Precaching
s2 = ONE + s
# Iteratively compute the polynomials n-k-erasures_count times. The last ones will be correct (since the algorithm refines the error/errata locator polynomial iteratively depending on the discrepancy, which is kind of a difference-from-correctness measure).
for l in xrange(0, n-k-erasures_count): # skip the first erasures_count iterations because we already computed the partial errata locator polynomial (by initializing with the erasures locator polynomial)
K = erasures_count+l+synd_shift # skip the FIRST erasures_count iterations (not the last iterations, that's very important!)
# Goal for each iteration: Compute sigma[l+1] and omega[l+1] such that
# (1 + s)*sigma[l] == omega[l] in mod z^(K)
# For this particular loop iteration, we have sigma[l] and omega[l],
# and are computing sigma[l+1] and omega[l+1]
# First find Delta, the non-zero coefficient of z^(K) in
# (1 + s) * sigma[l]
# Note that adding 1 to the syndrome s is not really necessary, you can do as well without.
# This delta is valid for l (this iteration) only
Delta = ( s2 * sigma[l] ).get_coefficient(K) # Delta is also known as the Discrepancy, and is always a scalar (not a polynomial).
# Make it a polynomial of degree 0, just for ease of computation with polynomials sigma and omega.
Delta = Polynomial(x0=Delta)
# Can now compute sigma[l+1] and omega[l+1] from
# sigma[l], omega[l], B[l], A[l], and Delta
sigma.append( sigma[l] - Delta * Z * B[l] )
omega.append( omega[l] - Delta * Z * A[l] )
# Now compute the next support polynomials B and A
# There are two ways to do this
# This is based on a messy case analysis on the degrees of the four polynomials sigma, omega, A and B in order to minimize the degrees of A and B. For more infos, see https://www.cs.duke.edu/courses/spring10/cps296.3/decoding_rs_scribe.pdf
# In fact it ensures that the degree of the final polynomials aren't too large.
if Delta == ZERO or 2*L[l] > K+erasures_count \
or (2*L[l] == K+erasures_count and M[l] == 0):
#if Delta == ZERO or len(sigma[l+1]) <= len(sigma[l]): # another way to compute when to update, and it doesn't require to maintain the update flag L
# Rule A
B.append( Z * B[l] )
A.append( Z * A[l] )
L.append( L[l] )
M.append( M[l] )
elif (Delta != ZERO and 2*L[l] < K+erasures_count) \
or (2*L[l] == K+erasures_count and M[l] != 0):
# elif Delta != ZERO and len(sigma[l+1]) > len(sigma[l]): # another way to compute when to update, and it doesn't require to maintain the update flag L
# Rule B
B.append( sigma[l] // Delta )
A.append( omega[l] // Delta )
L.append( K - L[l] ) # the update flag L is tricky: in Blahut's schema, it's mandatory to use `L = K - L - erasures_count` (and indeed in a previous draft of this function, if you forgot to do `- erasures_count` it would lead to correcting only 2*(errors+erasures) <= (n-k) instead of 2*errors+erasures <= (n-k)), but in this latest draft, this will lead to a wrong decoding in some cases where it should correctly decode! Thus you should try with and without `- erasures_count` to update L on your own implementation and see which one works OK without producing wrong decoding failures.
M.append( 1 - M[l] )
else:
raise Exception("Code shouldn't have gotten here")
# Hack to fix the simultaneous computation of omega, the errata evaluator polynomial: because A (the errata evaluator support polynomial) is not correctly initialized (I could not find any info in academic papers). So at the end, we get the correct errata evaluator polynomial omega + some higher order terms that should not be present, but since we know that sigma is always correct and the maximum degree should be the same as omega, we can fix omega by truncating too high order terms.
if omega[-1].degree > sigma[-1].degree: omega[-1] = Polynomial(omega[-1].coefficients[-(sigma[-1].degree+1):])
# Return the last result of the iterations (since BM compute iteratively, the last iteration being correct - it may already be before, but we're not sure)
return sigma[-1], omega[-1]
def _find_erasures_locator(self, erasures_pos):
'''Compute the erasures locator polynomial from the erasures positions (the positions must be relative to the x coefficient, eg: "hello worldxxxxxxxxx" is tampered to "h_ll_ worldxxxxxxxxx" with xxxxxxxxx being the ecc of length n-k=9, here the string positions are [1, 4], but the coefficients are reversed since the ecc characters are placed as the first coefficients of the polynomial, thus the coefficients of the erased characters are n-1 - [1, 4] = [18, 15] = erasures_loc to be specified as an argument.'''
# See: http://ocw.usu.edu/Electrical_and_Computer_Engineering/Error_Control_Coding/lecture7.pdf and Blahut, Richard E. "Transform techniques for error control codes." IBM Journal of Research and development 23.3 (1979): 299-315. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.92.600&rep=rep1&type=pdf and also a MatLab implementation here: http://www.mathworks.com/matlabcentral/fileexchange/23567-reed-solomon-errors-and-erasures-decoder/content//RS_E_E_DEC.m
erasures_loc = Polynomial([GF256int(1)]) # just to init because we will multiply, so it must be 1 so that the multiplication starts correctly without nulling any term
# erasures_loc is very simple to compute: erasures_loc = prod(1 - x*alpha[j]**i) for i in erasures_pos and where alpha is the alpha chosen to evaluate polynomials (here in this library it's gf(3)). To generate c*x where c is a constant, we simply generate a Polynomial([c, 0]) where 0 is the constant and c is positionned to be the coefficient for x^1. See https://en.wikipedia.org/wiki/Forney_algorithm#Erasures
for i in erasures_pos:
erasures_loc = erasures_loc * (Polynomial([GF256int(1)]) - Polynomial([GF256int(self.generator)**i, 0]))
return erasures_loc
Примечание: Сигма, Омега, A, B, L и M-все списки многочленов (поэтому мы сохраняем всю историю всех промежуточных многочленов, вычисленных на каждой итерации). Это, конечно, можно оптимизировать, потому что нам действительно нужно только Sigma[l], Sigma[l-1], Omega[l], Omega[l-1], A[l], B[l], L[l] и M[l] (так что это просто Сигма и Омега, которые должны держать предыдущую итерацию в памяти, другие переменные не потребность.)
примечание 2: флаг обновления L сложен: в некоторых реализациях выполнение так же, как в схеме Блахута, приведет к неправильным сбоям при декодировании. В моей прошлой реализации было обязательно использовать L = K - L - erasures_count чтобы правильно декодировать обе ошибки и стирания до одноэлементной границы, но в моей последней реализации мне пришлось использовать L = K - L (даже если есть стирания), чтобы избежать неправильных сбоев декодирования. Вы должны просто попробовать как на своей собственной реализации, так и посмотрите, какой из них не вызывает ошибок декодирования. Смотри ниже в вопросах для получения дополнительной информации.
единственная проблема с этим алгоритмом заключается в том, что он не описывает, как одновременно вычислять Omega, полином оценщика ошибок (в книге описывается, как инициализировать Omega только для ошибок, но не при декодировании ошибок и стираний). Я попробовал несколько вариаций и вышеуказанные работы, но не полностью: в конце Omega будет включать термины более высокого порядка, которые должны были быть отмененный. Вероятно, Omega или A полином поддержки оценщика ошибок, не инициализируется с хорошим значением.
однако вы можете исправить это, либо обрезав многочлен Omega слишком высоких членов порядка (так как он должен иметь ту же степень, что и лямбда / Сигма):
if omega[-1].degree > sigma[-1].degree: omega[-1] = Polynomial(omega[-1].coefficients[-(sigma[-1].degree+1):])
или вы можете полностью вычислить Omega с нуля после BM, используя локатор ошибок Lambda / Sigma, который всегда правильно вычисляется:
def _find_error_evaluator(self, synd, sigma, k=None):
'''Compute the error (or erasures if you supply sigma=erasures locator polynomial) evaluator polynomial Omega from the syndrome and the error/erasures/errata locator Sigma. Omega is already computed at the same time as Sigma inside the Berlekamp-Massey implemented above, but in case you modify Sigma, you can recompute Omega afterwards using this method, or just ensure that Omega computed by BM is correct given Sigma (as long as syndrome and sigma are correct, omega will be correct).'''
n = self.n
if not k: k = self.k
# Omega(x) = [ Synd(x) * Error_loc(x) ] mod x^(n-k+1) -- From Blahut, Algebraic codes for data transmission, 2003
return (synd * sigma) % Polynomial([GF256int(1)] + [GF256int(0)] * (n-k+1)) # Note that you should NOT do (1+Synd(x)) as can be seen in some books because this won't work with all primitive generators.
я ищу лучшего решение в следующий вопрос по CSTheory.
/ EDIT: я опишу некоторые проблемы у меня были и как их исправить:
- не забудьте ввести полином локатора ошибок с полиномом локатора стираний (который вы можете легко вычислить из синдромов и позиций стираний).
- если вы можете декодировать только ошибки и стирает только безупречно, но ограничивается
2*errors + erasures <= (n-k)/2, тогда вы забыли пропустить первый V итераций. - если вы можете декодировать как стирания и ошибки, но до
2*(errors+erasures) <= (n-k), то вы забыли обновить назначение L:L = i+1 - L - erasures_countвместоL = i+1 - L. Но это может привести к сбою декодера в некоторых случаях в зависимости от того, как вы реализовали декодер, см. Следующий пункт. - мой первый декодер был ограничен только одним генератором / простым полиномом/fcr, но когда я обновил его, чтобы быть универсальным и добавил строгие модульные тесты, декодер не удался, когда он не должен. Кажется, схема Блахута выше неверна о L (флаг обновления): она должна быть обновлена с помощью
L = K - L, а неL = K - L - erasures_count, потому что это приведет к сбою декодера иногда даже через Мы находимся под одноэлементной границей (и, таким образом, мы должны декодировать правильно!). Это, кажется, подтверждается тем фактом, что computingL = K - Lне только исправит эти проблемы декодирования, но и даст тот же результат, что и альтернативный способ обновления без использования флага обновления L (т. е. условиеif Delta == ZERO or len(sigma[l+1]) <= len(sigma[l]):). Но это странно: в моей прошлой реализации,L = K - L - erasures_countбыл обязательным для ошибок и стираний декодирования, но теперь, похоже, он производит неправильные сбои. Поэтому вы должны просто попробовать с вашей собственной реализацией и без нее и независимо от того, приводит ли тот или другой к неправильным неудачам для вас. - обратите внимание, что условие
2*L[l] > Kзаменить на2*L[l] > K+erasures_count. Вы можете не заметить никакого побочного эффекта без добавления условия+erasures_countсначала, но в некоторых случаях декодирование потерпит неудачу, когда не должно. - если вы можете исправить только одну ошибку или стирание, проверьте, что ваше состояние
2*L[l] > K+erasures_count, а не2*L[l] >= K+erasures_count(уведомление>вместо>=). - если вы не можете исправить
2*errors + erasures <= (n-k-2)(чуть ниже предела, например, если у вас есть 10 символов ecc, вы можете исправить только 4 ошибки вместо 5 обычно), затем проверьте свой синдром и свою петлю внутри BM algo: если синдром начинается с коэффициента 0 для постоянного члена x^0 (который иногда рекомендуется в книгах), то ваш синдром смещается, а затем ваша петля внутри BM должна начинаться с1и заканчивается наn-k+1вместо0:(n-k)если не сдвинут. - если вы можете исправить каждый символ, кроме последнего (последний символ ecc), то проверьте свои диапазоны, особенно в вашем поиске Цзянь: вы не должны оценивать полином локатора ошибок от alpha^0 до alpha^255, но от alpha^1 до alpha^256.
Я сослался на ваш код python и переписал C++.
это работает, ваша информация и пример кода действительно полезны.
и я обнаружил, что неправильные сбои могут быть вызваны M значение.
согласно "алгебраическим кодам для передачи данных",
Mзначение не должно быть членомif-elseслучае.
Я не получил никаких неправильных сбоев после M удалены.(или просто не провалиться пока)
большое спасибо за ваш обмен знаниями.
// calculate C
Ref<ModulusPoly> T = C;
// M just for shift x
ArrayRef<int> m_temp(2);
m_temp[0]=1;
m_poly = new ModulusPoly(field_, m_temp);
// C = C - d*B*x
ArrayRef<int> d_temp(1);
d_temp[0] = d;
Ref<ModulusPoly> d_poly (new ModulusPoly(field_, d_temp));
d_poly = d_poly->multiply(m_poly);
d_poly = d_poly->multiply(B);
C = C->subtract(d_poly);
if(2*L<=n+e_size-1 && d!=0)
{
// b = d^-1
ArrayRef<int> b_temp(1);
b_temp[0] = field_.inverse(d);
b_poly = new ModulusPoly(field_, b_temp);
L = n-L-e_size;
// B = B*b = B*d^-1
B = T->multiply(b_poly);
}
else
{
// B = B*x
B = B->multiply(m_poly);
}