Отладка PDF для ошибок
Я создаю PDF-файлы с помощью библиотеки java PDFClown.
иногда при открытии этих файлов с помощью Adobe Acrobat Reader я получаю известное сообщение об ошибке:
" на этой странице существует ошибка. Acrobat может отображать страницу неправильно. Пожалуйста, свяжитесь с человеком, который создал документ PDF, чтобы исправить проблему."
ошибка отображается при чтении (с помощью Adobe) прикрепленного файла только при прокрутке вниз до 8-й страницы, потом прокручивая обратно до 3 страницы стальтд. Кроме того, масштабирование до 33,3% также приведет к появлению сообщения.
просто для записи Foxit reader читает файл безупречно, а также другие читатели PDF, такие как браузеры.
мои вопросы:
Что случилось с моим файлом?? (привязан)
Как я могу найти, что с ним не так? есть ли инструмент, который говорит вам здесь тут ошибка лжи?
спасибо!
3 ответов
ладно, это было нелегко -
из-за ошибки в PDFClown мой основной поток информации на странице PDF был поврежден. После его окончания у него была копия прошлого экземпляра. Это вызвало частичный текстовый раздел без стартовой команды " BT "- который оставил один" ET "без" BT " в конце потока.
Как только я исправил это, он побежал отлично.
спасибо всем за помощь. Мне было бы намного сложнее отлаживать его без инструмент, который предложил @Bruno.
edit:
ошибка была в буфере.java: clone () (строка 217)
вместо строки:
клон.добавить(данные);
должно быть:
клон.добавить (data, 0, this.длина);
без этой коррекции он клонирует весь буфер данных и устанавливает длину клонированного буфера в data[].длина. Это очень проблематично, если буфер.длина меньше, чем данные.][длина. В результате в моем случае в конце потока оказался мусор.
ошибка отображается при чтении (с помощью Adobe) прикрепленного файла только при прокрутке вниз до 8-й страницы, а затем прокрутке до 3-й страницы. Кроме того, масштабирование до 33,3% также приведет к появлению сообщения.
Ну, я получаю это проще, я просто открываю PDF и прокручиваю вниз с помощью клавиш курсора. Как только появится верхний 2 см страницы 3, появится сообщение.
что случилось с моим файлом??
содержание страницы 1 и 2 выглядят нормально, поэтому давайте посмотрим на содержание страницы 3.
мое первоначальное приписывание проблемы использованию текстовых операций (особенно Tf и Tw) вне текстового объекта было неправильно, как отметил Стефано Чиззолини: некоторые операции, связанные с текстом действительно разрешены внешние текстовые объекты, а именно операции состояния текста, см. Рисунок 9 из спецификации PDF:
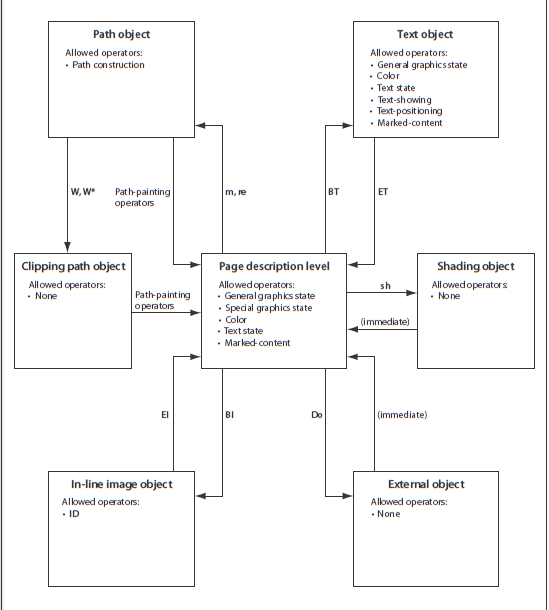
так будучи менее распространенными, операции состояния текста на уровне описания страницы полностью в порядке.
после моей неправильной попытки объяснить проблему, собственный ответ OP указал, что
основной поток информации на странице PDF был поврежден. После его окончания у него была копия прошлого экземпляра. Это вызвало частичный текстовый раздел без стартовой команды " BT "- который оставил один " ET " без "BT" в конце поток.
An ET до BT действительно будет ошибкой, и вполне вероятно, что это будет сопровождаться операциями на неправильном уровне... Однако, проверяя содержимое потока этой третьей страницы (сфокусированная страница этой проблемы), я не смог найти непревзойденного ET. Однако в ходе этого осмотра я обнаружил, что поток содержимого содержит более 2000 байт с хвостом 0! Adobe Reader похоже, не в состоянии справиться с этими 0 байт.
ошибка, обнаруженная OP, может объяснить проблему:
в буфере.java:
clone()(строка 217)вместо строки:
clone.append(data);должно быть:
clone.append(data, 0, this.length);без этой коррекции он клонирует весь буфер данных и устанавливает клонированный
Buffer' slengthдоdata[].length. Это очень проблематично, если буфер.длина` меньшеdata[].length.
трейлинг 0 байт может быть следствием такой ошибки копирования буфера.
кроме того, симптомы, обнаруженные OP (после его окончания у него была копия его прошлого экземпляра) также может быть следствием такой ошибки. Поэтому я предполагаю, что ОП нашел эти симптомы на другой странице, а не на странице 3, но исправление ошибки исцелило все симптомы.
как я могу найти, что с ним не так? есть ли инструмент, который говорит вам, где ошибка лжи?
существуют проверки синтаксиса PDF, например, инструмент предполетного запуска, включенный в Adobe Acrobat. но даже это не вписывается в твое досье.
таким образом, по существу, вы должны извлечь содержимое страницы (используя браузер PDF, например RUPS) и проверьте вручную со спецификацией PDF на другом экране.
общий пост об отладке pdf может быть также полезен, поскольку там упоминается rups / pdfstreamdump и т. д. Как вы отлаживаете PDF-файлы?