отображение списка строк в иерархическую структуру объектов
это не проблема домашнего задания. Этот вопрос был задан одному из моих друзей в тесте интервью.
у меня есть list строк, считываемых из файла в качестве входных данных. Каждая строка имеет идентификатор (A,B,NN,C, DD) в начале строки. В зависимости от идентификатора мне нужно сопоставить список записей в один объект A который содержит иерархическую структуру объектов.
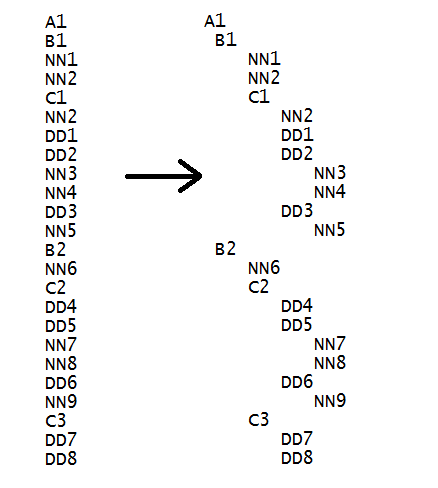
описание иерархии :
Каждый A может иметь ноль или больше B типы.
Каждый B идентификатор может иметь ноль или больше NN и C как ребенок. Точно так же каждый C сегмент может иметь ноль или больше NN и DD ребенок. Абд друг DD может иметь ноль или больше NN как ребенок.
классы отображения и их иерархия:
весь класс будет иметь value провести String значение из текущей строки.
**A - will have list of B**
class A {
List<B> bList;
String value;
public A(String value) {
this.value = value;
}
public void addB(B b) {
if (bList == null) {
bList = new ArrayList<B>();
}
bList.add(b);
}
}
**B - will have list of NN and list of C**
class B {
List<C> cList;
List<NN> nnList;
String value;
public B(String value) {
this.value = value;
}
public void addNN(NN nn) {
if (nnList == null) {
nnList = new ArrayList<NN>();
}
nnList.add(nn);
}
public void addC(C c) {
if (cList == null) {
cList = new ArrayList<C>();
}
cList.add(c);
}
}
**C - will have list of DDs and NNs**
class C {
List<DD> ddList;
List<NN> nnList;
String value;
public C(String value) {
this.value = value;
}
public void addDD(DD dd) {
if (ddList == null) {
ddList = new ArrayList<DD>();
}
ddList.add(dd);
}
public void addNN(NN nn) {
if (nnList == null) {
nnList = new ArrayList<NN>();
}
nnList.add(nn);
}
}
**DD - will have list of NNs**
class DD {
String value;
List<NN> nnList;
public DD(String value) {
this.value = value;
}
public void addNN(NN nn) {
if (nnList == null) {
nnList = new ArrayList<NN>();
}
nnList.add(nn);
}
}
**NN- will hold the line only**
class NN {
String value;
public NN(String value) {
this.value = value;
}
}
Что Я Сделал Так Далеко:
метод public A parse(List<String> lines) читает список входных данных и возвращает объект A. Поскольку может быть несколько B, Я создал отдельный метод 'parseB для разбора каждого случая.
At parseB метод, петли через i = startIndex + 1 to i < lines.size() и проверяет начало строк. Вхождение " NN " добавляется к текущему объекту B. Если" C " обнаружен при запуске, он вызывает другой метод parseC. Петля оборвется, когда мы обнаружим " B" или "А" в начале.
аналогичная логика используется в parseC_DD.
public class GTTest {
public A parse(List<String> lines) {
A a;
for (int i = 0; i < lines.size(); i++) {
String curLine = lines.get(i);
if (curLine.startsWith("A")) {
a = new A(curLine);
continue;
}
if (curLine.startsWith("B")) {
i = parseB(lines, i); // returns index i to skip all the lines that are read inside parseB(...)
continue;
}
}
return a; // return mapped object
}
private int parseB(List<String> lines, int startIndex) {
int i;
B b = new B(lines.get(startIndex));
for (i = startIndex + 1; i < lines.size(); i++) {
String curLine = lines.get(i);
if (curLine.startsWith("NN")) {
b.addNN(new NN(curLine));
continue;
}
if (curLine.startsWith("C")) {
i = parseC(b, lines, i);
continue;
}
a.addB(b);
if (curLine.startsWith("B") || curLine.startsWith("A")) { //ending condition
System.out.println("B A "+curLine);
--i;
break;
}
}
return i; // return nextIndex to read
}
private int parseC(B b, List<String> lines, int startIndex) {
int i;
C c = new C(lines.get(startIndex));
for (i = startIndex + 1; i < lines.size(); i++) {
String curLine = lines.get(i);
if (curLine.startsWith("NN")) {
c.addNN(new NN(curLine));
continue;
}
if (curLine.startsWith("DD")) {
i = parseC_DD(c, lines, i);
continue;
}
b.addC(c);
if (curLine.startsWith("C") || curLine.startsWith("A") || curLine.startsWith("B")) {
System.out.println("C A B "+curLine);
--i;
break;
}
}
return i;//return next index
}
private int parseC_DD(C c, List<String> lines, int startIndex) {
int i;
DD d = new DD(lines.get(startIndex));
c.addDD(d);
for (i = startIndex; i < lines.size(); i++) {
String curLine = lines.get(i);
if (curLine.startsWith("NN")) {
d.addNN(new NN(curLine));
continue;
}
if (curLine.startsWith("DD")) {
d=new DD(curLine);
continue;
}
c.addDD(d);
if (curLine.startsWith("NN") || curLine.startsWith("C") || curLine.startsWith("A") || curLine.startsWith("B")) {
System.out.println("NN C A B "+curLine);
--i;
break;
}
}
return i;//return next index
}
public static void main(String[] args) {
GTTest gt = new GTTest();
List<String> list = new ArrayList<String>();
list.add("A1");
list.add("B1");
list.add("NN1");
list.add("NN2");
list.add("C1");
list.add("NNXX");
list.add("DD1");
list.add("DD2");
list.add("NN3");
list.add("NN4");
list.add("DD3");
list.add("NN5");
list.add("B2");
list.add("NN6");
list.add("C2");
list.add("DD4");
list.add("DD5");
list.add("NN7");
list.add("NN8");
list.add("DD6");
list.add("NN7");
list.add("C3");
list.add("DD7");
list.add("DD8");
A a = gt.parse(list);
//show values of a
}
}
моя логика работает неправильно. Есть ли другой подход, который вы можете выяснить? У вас есть какие-либо предложения/улучшения в моем пути?
3 ответов
использовать иерархию объектов:
public interface Node {
Node getParent();
Node getLastChild();
boolean addChild(Node n);
void setValue(String value);
Deque getChildren();
}
private static abstract class NodeBase implements Node {
...
abstract boolean canInsert(Node n);
public String toString() {
return value;
}
...
}
public static class A extends NodeBase {
boolean canInsert(Node n) {
return n instanceof B;
}
}
public static class B extends NodeBase {
boolean canInsert(Node n) {
return n instanceof NN || n instanceof C;
}
}
...
public static class NN extends NodeBase {
boolean canInsert(Node n) {
return false;
}
}
создать класс дерева:
public class MyTree {
Node root;
Node lastInserted = null;
public void insert(String label) {
Node n = NodeFactory.create(label);
if (lastInserted == null) {
root = n;
lastInserted = n;
return;
}
Node current = lastInserted;
while (!current.addChild(n)) {
current = current.getParent();
if (current == null) {
throw new RuntimeException("Impossible to insert " + n);
}
}
lastInserted = n;
}
...
}
а затем распечатать дерево:
public class MyTree {
...
public static void main(String[] args) {
List input;
...
MyTree tree = new MyTree();
for (String line : input) {
tree.insert(line);
}
tree.print();
}
public void print() {
printSubTree(root, "");
}
private static void printSubTree(Node root, String offset) {
Deque children = root.getChildren();
Iterator i = children.descendingIterator();
System.out.println(offset + root);
while (i.hasNext()) {
printSubTree(i.next(), offset + " ");
}
}
}
решение автомата mealy с 5 состояниями: ждать, видел, видел B, видел C, и видел DD.
разбор выполняется полностью одним методом. Есть один current узел, который является последним узлом, кроме NN те. Узел имеет родительский узел, кроме корневого. В состоянии seen (0), the current узел представляет собой (0) (например, в состоянии видел C, current может быть C1 в приведенном выше примере). Самая скрипка находится в состоянии видел DD, который имеет самые исходящие края (B, C, DD и NN).
public final class Parser {
private final static class Token { /* represents A1 etc. */ }
public final static class Node implements Iterable<Node> {
/* One Token + Node children, knows its parent */
}
private enum State { ExpectA, SeenA, SeenB, SeenC, SeenDD, }
public Node parse(String text) {
return parse(Token.parseStream(text));
}
private Node parse(Iterable<Token> tokens) {
State currentState = State.ExpectA;
Node current = null, root = null;
while(there are tokens) {
Token t = iterator.next();
switch(currentState) {
/* do stuff for all states */
/* example snippet for SeenC */
case SeenC:
if(t.Prefix.equals("B")) {
current.PN.PN.AddChildNode(new Node(t, current.PN.PN));
currentState = State.SeenB;
} else if(t.Prefix.equals("C")) {
}
}
return root;
}
}
я не удовлетворен этими trainwrecks, чтобы подняться по иерархии, чтобы вставить узел где-то еще (current.PN.PN). В конце концов, явные классы состояний сделают private parse способ более читабельным. Тогда решение становится больше похожа на @AlekseyOtrubennikov. Возможно прямой LL подход дает код, который является более красивым. Возможно, лучше всего просто перефразировать грамматику на BNF one и делегировать создание парсера.
Простой парсер LL, одно производственное правило:
// "B" ("NN" || C)*
private Node rule_2(TokenStream ts, Node parent) {
// Literal "B"
Node B = literal(ts, "B", parent);
if(B == null) {
// error
return null;
}
while(true) {
// check for "NN"
Node nnLit = literal(ts, "NN", B);
if(nnLit != null)
B.AddChildNode(nnLit);
// check for C
Node c = rule_3(ts, parent);
if(c != null)
B.AddChildNode(c);
// finished when both rules did not match anything
if(nnLit == null && c == null)
break;
}
return B;
}
TokenStream повышает Iterable<Token>, позволяя смотреть в поток -LL(1) потому что парсер должен выбирать между literal NN или глубокое погружение в двух случаях (rule_2 являясь одним из них). Выглядит хорошо, однако, отсутствуют некоторые функции C# здесь...
@Stefan и @Aleksey правы: это простая проблема разбора. Ограничения иерархии можно определить в Расширенная Форма Backus-Naur:
A ::= { B }
B ::= { NN | C }
C ::= { NN | DD }
DD ::= { NN }
это описание можно преобразовать в государственную машину и реализовать. Но есть много инструментов, которые могут эффективно сделать это для вас: парсер генераторы.
я публикую свой ответ только для того, чтобы показать, что довольно легко решить такие проблемы с Haskell (или некоторыми другими функциональный язык.)
Вот полное программа, которая читает строки форма stdin и выводит в stdout дерева.
-- We are using some standard libraries.
import Control.Applicative ((<$>), (<*>))
import Text.Parsec
import Data.Tree
-- This is EBNF-like description of what to do.
-- You can almost read it like a prose.
yourData = nodeA +>> eof
nodeA = node "A" nodeB
nodeB = node "B" (nodeC <|> nodeNN)
nodeC = node "C" (nodeNN <|> nodeDD)
nodeDD = node "DD" nodeNN
nodeNN = (`Node` []) <$> nodeLabel "NN"
node lbl children
= Node <$> nodeLabel lbl <*> many children
nodeLabel xx = (xx++)
<$> (string xx >> many digit)
+>> newline
-- And this is some auxiliary code.
f +>> g = f >>= \x -> g >> return x
main = do
txt <- getContents
case parse yourData "" txt of
Left err -> print err
Right res -> putStrLn $ drawTree res
выполнить его с вашими данными в zz.txt напечатает это славное дерево:
$ ./xxx < zz.txt
A1
+- B1
| +- NN1
| +- NN2
| `- C1
| +- NN2
| +- DD1
| +- DD2
| | +- NN3
| | `- NN4
| `- DD3
| `- NN5
`- B2
+- NN6
+- C2
| +- DD4
| +- DD5
| | +- NN7
| | `- NN8
| `- DD6
| `- NN9
`- C3
+- DD7
`- DD8
и вот как он обрабатывает искаженный ввод:
$ ./xxx
A1
B2
DD3
(line 3, column 1):
unexpected 'D'
expecting "B" or end of input