Почему это сканирование индекса, а не Поиск индекса?
вот запрос:
SELECT top 100 a.LocationId, b.SearchQuery, b.SearchRank
FROM dbo.Locations a
INNER JOIN dbo.LocationCache b ON a.LocationId = b.LocationId
WHERE a.CountryId = 2
AND a.Type = 7
Расположение Индексов:
PK_Locations:
идентификатор locationId
IX_Locations_CountryId_Type:
CountryId, Типа
Индексы LocationCache:
PK_LocationCache:
идентификатор locationId
IX_LocationCache_LocationId_Searchquery_searchrank:
LocationId, SearchQuery, SearchRank
Выполнение Плана:
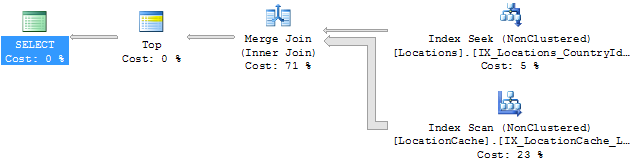
Итак, он делает Искать на местах, используя индекс покрытия, круто.
но почему он делает Сканирование Индекса по индексу покрытия LocationCache?
этот индекс покрытия имеет LocationId, SearchQuery, SearchRank в индексе (не как " включено столбцы.)"
наведите указатель мыши на сканирование индекса:
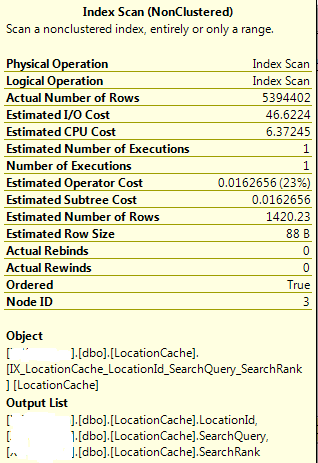
этот запрос должен идти в индексированном представлении, обслуживаемом каталогом FTS SQL Server, потребляемым плагином автозаполнения, поэтому он должен быть оптимизирован на 100%.
на данный момент, что выше запрос занимает 3 секунды. Должно быть
какие идеи?
5 ответов
имея в виду, что это приведет к запросу, который может работать плохо, как и когда в него вносятся дополнительные изменения, используя INNER LOOP JOIN должен заставить индекс покрытия использоваться на dbo.LocationCache.
SELECT top 100 a.LocationId, b.SearchQuery, b.SearchRank
FROM dbo.Locations a
INNER LOOP JOIN dbo.LocationCache b ON a.LocationId = b.LocationId
WHERE a.CountryId = 2
AND a.Type = 7
Он использует сканирование индекса в первую очередь потому, что он также использует объединение слиянием. Оператор объединения слиянием требует два входных потока, которые сортируются в порядке, совместимом с условиями соединения.
и он использует оператор объединения слияния для реализации вашего внутреннего соединения, потому что он считает, что это будет быстрее, чем более типичный оператор соединения вложенного цикла. И это, вероятно, правильно (Обычно так и есть), используя два выбранных индекса, он имеет входные потоки это оба предварительно отсортированы в соответствии с вашим условием соединения (LocationID). Когда входные потоки предварительно отсортированы, соединения слияния почти всегда быстрее, чем два других (циклические и хэш-соединения).
недостатком является то, что вы заметили: он, похоже, сканирует весь индекс, так как это может быть быстрее, если он читает так много записей, которые никогда не могут быть использованы? Ответ заключается в том, что сканирование (из-за их последовательного характера) может читать от 10 до 100 раз больше records / second as seeks.
теперь обычно ищет win, потому что они избирательны: они получают только строки, которые вы просите, тогда как сканирование неселективно: они должны возвращать каждую строку в диапазоне. Но потому что сканирование имеет много более высокая скорость чтения, они могут часто бить стремится до тех пор, как отношение отброшенных строк к соответствующим строкам ниже чем отношение строк сканирования / сек против. Искать строки / сек.
вопросы?
ОК, Я попросили объяснить последнее предложение подробнее:
"отброшенная строка" - это та, которую читает сканирование (потому что она должна читать все в индексе), но это будет отклонено оператором объединения слияния, потому что у него нет совпадения с другой стороны, возможно, потому, что условие предложения WHERE уже исключило его.
"соответствующие строки" - это те, которые он читает, которые фактически соответствуют чему-то в объединении слияния. Это те же строки, которые были прочитаны поиском, если сканирование было заменено поиском.
вы можете выяснить, что есть, посмотрев статистику в плане запроса. Видишь ту огромную жирную стрелку слева от индекса? Это представляет, сколько строк оптимизатор считает, что он будет читать при сканировании. Поле статистики сканирования индекса, которое вы разместили, показывает, что фактические возвращенные строки составляют около 5,4 м (5,394,402). Это равно:
TotalScanRows = (MatchingRows + DiscardedRows)
(в моих терминах, во всяком случае). Чтобы получить Сопоставляя строки, посмотрите на "фактические строки", сообщаемые оператором Merge Join (возможно, вам придется снять ТОП-100, чтобы получить это точно). Как только вы это узнаете, вы можете получить отброшенные строки по:
DiscardedRows = (TotalScanRows - MatchingRows)
и теперь вы можете рассчитать соотношение.
вы пытались обновить статистику?
UPDATE STATISTICS dbo.LocationCache
вот несколько хороших ссылок на то, что это делает и почему оптимизатор запросов выберет сканирования по поиску.
резюме
есть несколько вещей, чтобы принять во рассмотрение здесь. Во-первых, когда SQL решает на лучшее (достаточно хорошо) планируете использовать, он смотрит на запрос, а потом еще смотрит статистику что он хранит о таблицах вовлеченный.
затем он решает, если это более эффективно искать вниз по индексу, или сканировать весь листовой уровень индекса (в этом случае это включает прикосновение каждая страница в таблице, потому что это кластеризованный индекс) этого глядя на многие вещи. Во-первых, он угадывает строки / страницы, которые необходимо сканировать. Этот называется переломным моментом и является ниже, чем вы думаете. См. этот великий блог Кимберли Трипп http://www.sqlskills.com/BLOGS/KIMBERLY/category/The-Tipping-Point.aspx
Если вы находитесь в пределах переломный момент, это может быть потому, что статистика устарела, или индекс сильно фрагментирован.
можно заставить SQL искать индекс с помощью запроса FORCESEEK подсказка, но, пожалуйста, используйте это внимание, как правило, предоставляя вам держите все, что мы поддерживаем, SQL довольно хорошо решает, что самый эффективный план будет!!
Короче говоря: у вас нет фильтра на LocationCache, все содержимое таблицы должно быть возвращено. У вас есть полностью покрывающий индекс. Сканирование индекса (один раз) - самая дешевая операция, и оптимизатор запросов выбирает ее.
оптимизировать:
Вы присоединяетесь ко всем таблицам, а позже получаете только 100 лучших результатов. Я не знаю, насколько они велики, но попробуйте запросить таблицу [Locations]CountryId, Type а затем присоединиться только к результату с [LocationCache]. Будет waaaay быстрее, если у вас более 1000 строк там.
Кроме того, попробуйте добавить некоторые более ограничительные фильтры перед соединениями, если это возможно.
Сканирование Индекса : Поскольку сканирование затрагивает каждую строку таблицы независимо от ее квалификации, стоимость пропорциональна общему числу строк в таблице. Таким образом, сканирование является эффективной стратегией, если таблица мала или если большинство строк соответствуют предикату.
Искать: Поскольку поиск касается только строк, которые соответствуют требованиям, и страниц, содержащих эти строки, стоимость пропорционально количеству квалификационных строк и страниц, а не общему количеству строк в таблице.Если есть индекс в таблице, и если запрос касается большего объема данных, что означает, что запрос извлекает более 50 процентов или 90 процентов данных, а затем оптимизатор будет просто сканировать все страницы данных для извлечения строк данных.
Я сделал быстрый тест и придумали следующее
CREATE TABLE #Locations
(LocationID INT NOT NULL ,
CountryID INT NOT NULL ,
[Type] INT NOT NULL
CONSTRAINT PK_Locations
PRIMARY KEY CLUSTERED ( LocationID ASC )
)
CREATE NONCLUSTERED INDEX [LocationsIndex01] ON #Locations
(
CountryID ASC,
[Type] ASC
)
CREATE TABLE #LocationCache
(LocationID INT NOT NULL ,
SearchQuery VARCHAR(50) NULL ,
SearchRank INT NOT NULL
CONSTRAINT PK_LocationCache
PRIMARY KEY CLUSTERED ( LocationID ASC )
)
CREATE NONCLUSTERED INDEX [LocationCacheIndex01] ON #LocationCache
(
LocationID ASC,
SearchQuery ASC,
SearchRank ASC
)
INSERT INTO #Locations
SELECT 1,1,1 UNION
SELECT 2,1,4 UNION
SELECT 3,2,7 UNION
SELECT 4,2,7 UNION
SELECT 5,1,1 UNION
SELECT 6,1,4 UNION
SELECT 7,2,7 UNION
SELECT 8,2,7 --UNION
INSERT INTO #LocationCache
SELECT 4,'BlahA',10 UNION
SELECT 3,'BlahB',9 UNION
SELECT 2,'BlahC',8 UNION
SELECT 1,'BlahD',7 UNION
SELECT 8,'BlahE',6 UNION
SELECT 7,'BlahF',5 UNION
SELECT 6,'BlahG',4 UNION
SELECT 5,'BlahH',3 --UNION
SELECT * FROM #Locations
SELECT * FROM #LocationCache
SELECT top 3 a.LocationId, b.SearchQuery, b.SearchRank
FROM #Locations a
INNER JOIN #LocationCache b ON a.LocationId = b.LocationId
WHERE a.CountryId = 2
AND a.[Type] = 7
DROP TABLE #Locations
DROP TABLE #LocationCache
для меня план запроса показывает поиск с вложенным внутренним соединением цикла. Если вы запустите это, вы получите оба поиска? Если да, то сделайте тест в своей системе и создайте копию своих местоположений и таблицы LocationCache и вызовите их, скажем Locations2 и LocationCache2 со всеми индексами и скопируйте в них свои данные. Затем попробуйте свой запрос, попав в новые таблицы?