почему LZMA SDK (7-zip) так медленно
Я нашел 7-zip отлично, и я хотел бы использовать его в приложениях .net. У меня есть файл 10MB (a.001) и берет:
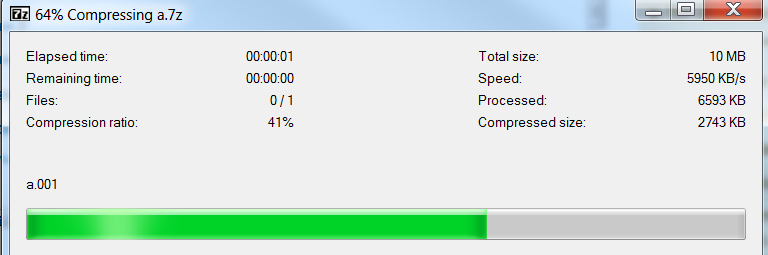
2 секунды для кодирования.
теперь было бы неплохо, если бы я мог сделать то же самое на c#. Я скачал http://www.7-zip.org/sdk.html исходный код LZMA SDK c#. Я в основном скопировал каталог CS в консольное приложение в visual studio:
затем я скомпилировал и все прошло гладко. Поэтому в выходной каталог я поместил файл a.001 что 10MB размера. На основном методе, который пришел на исходный код, я разместил:
[STAThread]
static int Main(string[] args)
{
// e stands for encode
args = "e a.001 output.7z".Split(' '); // added this line for debug
try
{
return Main2(args);
}
catch (Exception e)
{
Console.WriteLine("{0} Caught exception #1.", e);
// throw e;
return 1;
}
}
когда я запустить консольное приложение, приложение отлично работает и я получаю выход a.7z на рабочем каталоге. проблема в том, что это занимает так много времени. Она занимает около 15 секунд, чтобы выполнить! Я также пробовал https://stackoverflow.com/a/8775927/637142 подход и это также занимает очень много времени. Почему он в 10 раз медленнее, чем сама программа ?
и
даже если я использую только один поток:
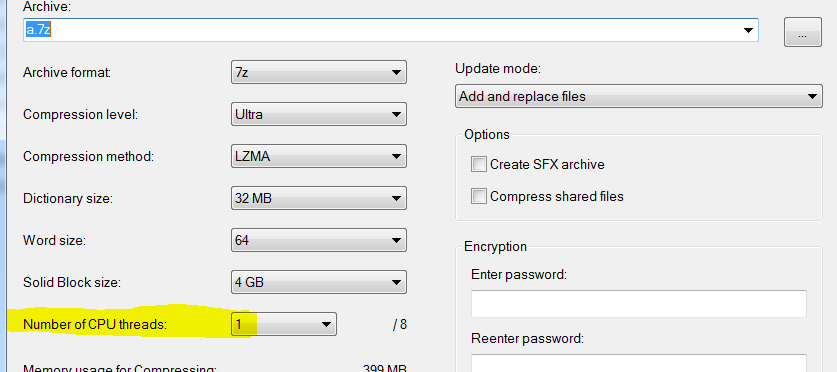
это все еще занимает гораздо меньше времени (3 секунды против 15):
(Edit) Еще Одна Возможность
может быть, потому, что C# медленнее, чем сборка или C ? Я замечаю, что алгоритм делает много тяжелых операций. Например, сравните эти два блока кода. Они оба делают то же вещь:
C
#include <time.h>
#include<stdio.h>
void main()
{
time_t now;
int i,j,k,x;
long counter ;
counter = 0;
now = time(NULL);
/* LOOP */
for(x=0; x<10; x++)
{
counter = -1234567890 + x+2;
for (j = 0; j < 10000; j++)
for(i = 0; i< 1000; i++)
for(k =0; k<1000; k++)
{
if(counter > 10000)
counter = counter - 9999;
else
counter= counter +1;
}
printf (" %d n", time(NULL) - now); // display elapsed time
}
printf("counter = %dnn",counter); // display result of counter
printf ("Elapsed time = %d seconds ", time(NULL) - now);
gets("Wait");
}
выход
c#
static void Main(string[] args)
{
DateTime now;
int i, j, k, x;
long counter;
counter = 0;
now = DateTime.Now;
/* LOOP */
for (x = 0; x < 10; x++)
{
counter = -1234567890 + x + 2;
for (j = 0; j < 10000; j++)
for (i = 0; i < 1000; i++)
for (k = 0; k < 1000; k++)
{
if (counter > 10000)
counter = counter - 9999;
else
counter = counter + 1;
}
Console.WriteLine((DateTime.Now - now).Seconds.ToString());
}
Console.Write("counter = {0} n", counter.ToString());
Console.Write("Elapsed time = {0} seconds", DateTime.Now - now);
Console.Read();
}
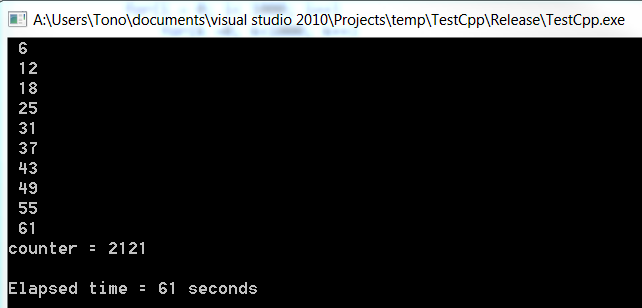
выход
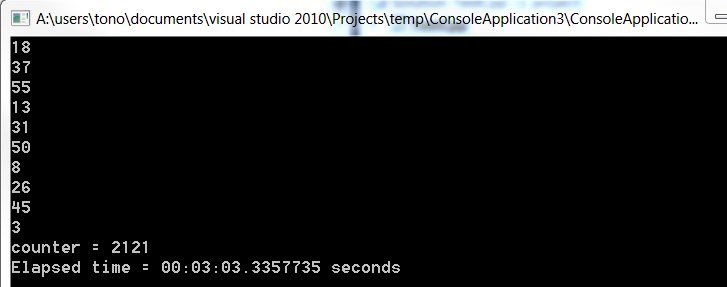
обратите внимание, насколько медленнее был c#. Обе программы, запущенные из-за пределов visual studio в режиме выпуска. возможно, именно поэтому в .net это занимает гораздо больше времени, чем на c++.
также я получил те же результаты. C# был в 3 раза медленнее, как на примере, который я только что показал!
вывод
Я, похоже, не знаю, что вызывает проблему. Я думаю, я буду использовать 7z.dll и вызовите необходимые методы из c#. Библиотека, которая делает это на: http://sevenzipsharp.codeplex.com/ и таким образом я использую ту же библиотеку, которую 7zip использует как:
// dont forget to add reference to SevenZipSharp located on the link I provided
static void Main(string[] args)
{
// load the dll
SevenZip.SevenZipCompressor.SetLibraryPath(@"C:Program Files (x86)-Zipz.dll");
SevenZip.SevenZipCompressor compress = new SevenZip.SevenZipCompressor();
compress.CompressDirectory("MyFolderToArchive", "output.7z");
}
6 ответов
этот вид двоичного арифметического и ветвящегося кода-это то, что любят c-компиляторы и что ненавидит .NET JIT. .NET JIT не очень умный компилятор. Он оптимизирован для быстрой компиляции. Если бы Microsoft хотела настроить его на максимальную производительность, они бы подключили бэкэнд VC++, но затем намеренно этого не делают.
кроме того, я могу сказать по скорости, с которой вы получаете 7z.exe (6 МБ/с), что вы используете несколько ядер, возможно, используя LZMA2. Мой быстрый сердечник i7 может поставить 2MB/s на ядро, так что я думаю 7z.exe работает многопоточный для вас. Попробуйте Включить потоковую обработку в 7zip-библиотеке, если это возможно.
Я рекомендую вместо использования управляемого кода LZMA-algorithm использовать скомпилированную библиотеку или вызов 7z.exe использование Process.Start. Последний должен заставить вас начать очень быстро с хорошими результатами.
я запустил профилировщик кода, и самая дорогая операция, похоже, заключается в поиске совпадений. В C# он ищет по одному байту за раз. В LzBinTree есть две функции (GetMatches и Skip).cs, которые содержат следующий фрагмент кода, и он тратит что-то вроде 40-60% своего времени на этот код:
if (_bufferBase[pby1 + len] == _bufferBase[cur + len])
{
while (++len != lenLimit)
if (_bufferBase[pby1 + len] != _bufferBase[cur + len])
break;
это в основном пытается найти длину совпадения одного байта за раз. Я извлек это в свой собственный метод:
if (GetMatchLength(lenLimit, cur, pby1, ref len))
{
и если вы используете небезопасный код и бросаете байт* в ulong* и сравниваете 8 байтов за раз вместо 1, скорость почти удвоилась для моих тестовых данных (в 64-битном процессе):
private bool GetMatchLength(UInt32 lenLimit, UInt32 cur, UInt32 pby1, ref UInt32 len)
{
if (_bufferBase[pby1 + len] != _bufferBase[cur + len])
return false;
len++;
// This method works with or without the following line, but with it,
// it runs much much faster:
GetMatchLengthUnsafe(lenLimit, cur, pby1, ref len);
while (len != lenLimit
&& _bufferBase[pby1 + len] == _bufferBase[cur + len])
{
len++;
}
return true;
}
private unsafe void GetMatchLengthUnsafe(UInt32 lenLimit, UInt32 cur, UInt32 pby1, ref UInt32 len)
{
const int size = sizeof(ulong);
if (lenLimit < size)
return;
lenLimit -= size - 1;
fixed (byte* p1 = &_bufferBase[cur])
fixed (byte* p2 = &_bufferBase[pby1])
{
while (len < lenLimit)
{
if (*((ulong*)(p1 + len)) == *((ulong*)(p2 + len)))
{
len += size;
}
else
return;
}
}
}
Я сам не использовал LZMA SDK, но я уверен, что по умолчанию 7-zip выполняет большинство операций во многих потоках. Поскольку я не сделал этого сам, единственное, что я могу предложить, - это проверить, можно ли заставить его использовать много потоков (если он не используется по умолчанию).
изменить:
Поскольку кажется, что потоковая передача не может быть (единственной) проблемой, связанной с производительностью, есть другие, о которых я мог бы подумать:
вы проверили, что вы установите те же параметры, что и при использовании 7-zip UI? Выходной файл одинакового размера? Если нет - может случиться так, что один метод сжатия гораздо быстрее, чем другой.
вы выполняете свое приложение из withing VS или нет? Если это так - это может добавить некоторые накладные расходы (но я думаю, что это не должно привести к тому, что приложение работает в 5 раз медленнее).
- есть ли какие-либо другие операции, происходящие перед сжатием файл?
Я только что взглянул на реализацию LZMA CS, и все это выполняется в управляемом коде. Недавно проведя некоторое исследование этого для требования сжатия в моем текущем проекте, большинство реализаций сжатия в управляемом коде, похоже, работают менее эффективно, чем в native.
Я могу только предположить, что это является причиной проблемы здесь. Если вы посмотрите на таблицу производительности для другого инструмента сжатия QuickLZ, вы увидите разницу в производительности между машинным и управляемым кодом (будь то C# или Java).
на ум приходят два варианта: используйте средства взаимодействия .NET для вызова собственного метода сжатия, или если вы можете позволить себе пожертвовать размером сжатия, взгляните наhttp://www.quicklz.com/.
Другой альтернативой является использование SevenZipSharp (доступно на NuGet) и указать его на ваш 7z.dll - ... Тогда ваши скорости должны быть примерно одинаковыми:
var libPath = Path.Combine(Environment.GetFolderPath(Environment.SpecialFolder.ProgramFiles), "7-zip", "7z.dll");
SevenZip.SevenZipCompressor.SetLibraryPath(libPath);
SevenZip.SevenZipCompressor compressor = new SevenZipCompressor();
compressor.CompressFiles(compressedFile, new string[] { sourceFile });
.net runtime работает медленнее, чем собственные инструкции. Если что-то пойдет не так в c, у нас обычно есть сбой приложения с синим экраном смерти. Но в c# это не так, потому что все проверки, которые мы не делаем в c, фактически добавляются в c#. Без дополнительной проверки null среда выполнения никогда не может поймать исключение нулевого указателя. Без проверки индекса и длины среда выполнения никогда не может поймать исключение за пределами границ.
это неявные инструкции перед каждой инструкцией это делает .net runtime медленным. В типичных бизнес-приложениях мы не заботимся о производительности, где важнее complxicity бизнес-логики и ui, поэтому .net runtime защищает каждую инструкцию с особой тщательностью, что позволяет нам быстро отлаживать и решать проблемы.
собственные программы c всегда будут быстрее, чем .NET runtime, но их трудно отлаживать и нуждаются в глубоком знании c для написания правильного кода. Потому что c выполнит все, но не даст вам никаких исключений или не знал, что пошло не так.