Почему некоторые итераторы быстрее других в C#?
некоторые итераторы быстрее. Я узнал об этом, потому что услышал от Боба табора на канал 9 чтобы не копировать и вставлять.
у меня была привычка делать что-то вроде этого, чтобы установить значения массива:
testArray[0] = 0;
testArray[1] = 1;
Это упрощенный пример, но чтобы не копировать и вставлять или не печатать вещи снова, я полагаю, что должен использовать цикл. Но у меня было это ноющее чувство, что цикл будет медленнее, чем просто перечисление команд, и похоже, что я правильно: перечислять вещи намного быстрее. Скорость, от самой быстрой до самой медленной, в большинстве моих испытаний была списком, циклом do, циклом for, а затем циклом while.
почему перечисление вещей быстрее, чем использование итератора, и почему итераторы разные скорости?
пожалуйста, помогите мне, если я не использовал эти итераторы в наиболее эффективным способом.
вот мои результаты (для массива 2 int), и мой код ниже (для массива 4 int). Я попытался это несколько раз на моей Windows 7 64 бит.
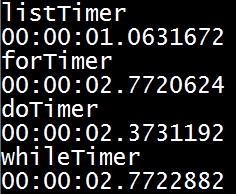
либо я не хорош в итерации, либо использование итераторов не так здорово, как это было сделано. Пожалуйста, дайте мне знать, что это. Большое спасибо.
int trials = 0;
TimeSpan listTimer = new TimeSpan(0, 0, 0, 0);
TimeSpan forTimer = new TimeSpan(0, 0, 0, 0);
TimeSpan doTimer = new TimeSpan(0, 0, 0, 0);
TimeSpan whileTimer = new TimeSpan(0, 0, 0, 0);
Stopwatch stopWatch = new Stopwatch();
long numberOfIterations = 100000000;
int numElements = 4;
int[] testArray = new int[numElements];
testArray[0] = 0;
testArray[1] = 1;
testArray[2] = 2;
testArray[3] = 3;
// List them
stopWatch.Start();
for (int x = 0; x < numberOfIterations; x++)
{
testArray[0] = 0;
testArray[1] = 1;
testArray[2] = 2;
testArray[3] = 3;
}
stopWatch.Stop();
listTimer += stopWatch.Elapsed;
Console.WriteLine(stopWatch.Elapsed);
stopWatch.Reset();
// for them
stopWatch.Start();
int q;
for (int x = 0; x < numberOfIterations; x++)
{
for (q = 0; q < numElements; q++)
testArray[q] = q;
}
stopWatch.Stop();
forTimer += stopWatch.Elapsed;
Console.WriteLine(stopWatch.Elapsed);
stopWatch.Reset();
// do them
stopWatch.Start();
int r;
for (int x = 0; x < numberOfIterations; x++)
{
r = 0;
do
{
testArray[r] = r;
r++;
} while (r < numElements);
}
stopWatch.Stop();
doTimer += stopWatch.Elapsed;
Console.WriteLine(stopWatch.Elapsed);
stopWatch.Reset();
// while
stopWatch.Start();
int s;
for (int x = 0; x < numberOfIterations; x++)
{
s = 0;
while (s < numElements)
{
testArray[s] = s;
s++;
}
}
stopWatch.Stop();
whileTimer += stopWatch.Elapsed;
Console.WriteLine(stopWatch.Elapsed);
stopWatch.Reset();
Console.WriteLine("listTimer");
Console.WriteLine(listTimer);
Console.WriteLine("forTimer");
Console.WriteLine(forTimer);
Console.WriteLine("doTimer");
Console.WriteLine(doTimer);
Console.WriteLine("whileTimer");
Console.WriteLine(whileTimer);
Console.WriteLine("Enter any key to try again the program");
Console.ReadLine();
trials++;
когда я попробовал 4 элемента массива результатов становилось более выраженным.
Я подумал, что было бы справедливо, если бы я сделал значение для группы listThem, назначенной через переменную, как и другие испытания. Это сделало listThem группа немного медленнее, но все равно быстрее. Вот результаты после нескольких попыток:
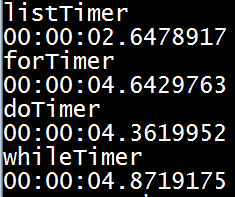
и вот как я реализовал список:
int w = 0;
for (int x = 0; x < numberOfIterations; x++)
{
testArray[w] = w;
w++;
testArray[w] = w;
w++;
testArray[w] = w;
w++;
testArray[w] = w;
w = 0;
}
Я знаю, что эти результаты, вероятно, специфичны для реализации, но вы могли бы подумать, что Microsoft предупредит нас о преимуществах и недостатках каждого цикла, когда дело доходит до скорости. А ты как думаешь? Спасибо.
обновление: в соответствии с комментариями я опубликовал код и список все еще быстрее, чем циклы, но циклы кажутся ближе по производительности. Циклы от самого быстрого до самого медленного: Для, в то время как, затем сделать. Это немного отличается, поэтому я предполагаю, что do и while по существу одинаковы, а цикл for примерно на полпроцента быстрее, чем циклы do и while, по крайней мере на моей машине. Вот результаты нескольких испытаний:--38-->
2 ответов
некоторые итераторы быстрее.
конечно, некоторые итераторы делают разные вещи. Другой код, делающий разные вещи, будет работать с разной скоростью.
у меня была привычка делать что-то вроде этого, чтобы установить значения массива:
во-первых, это действительно время нужно, чтобы сэкономить? Из ваших измерений (которые бессмысленны, если это была отладочная сборка) казалось бы, что ваш дополнительный код приносит вам экономия около 10 наносекунд. Если все в мире использовали ваше приложение один раз, общее количество времени, которое вы сохранили все ваши пользователи все равно будет меньше, чем дополнительное время, потраченное на ввод текста. Ни один из них в любой момент не подумает: "Ну, есть десять наносекунд, которые я никогда не вернусь".
но вы могли бы подумать, что Microsoft предупредит нас о преимуществах и недостатках каждого цикла, когда дело доходит до скорости
Нет, я действительно не стал бы.
особенно, когда вы обобщаете дальше. Во-первых, с большим циклом эквивалентный размотанный код вполне может быть медленнее, из-за того, что цикл может поместиться в кэш строки инструкции, в то время как размотанный код не будет.
для другого, итерация и перечисление (которое в среднем имеет тенденцию быть медленнее, чем итерация, но не намного) намного более гибки. Они приведут к меньшему, более идиоматическому коду. АР применимо ко многим случаям, когда вид размотки у вас либо не применим, либо не применим (поэтому вы теряете любую экономию, которую ожидаете из-за необходимости делать что-то запутанное). У них меньше возможностей для ошибок просто потому, что у них меньше возможностей для чего-либо.
поэтому, во-первых, MS или кто-либо еще не может посоветовать всегда заполнять ваш код страницами повторяющихся вставленных копий, чтобы сэкономить несколько наносекунд, потому что это не всегда будет самым быстрым подходите в любом случае, а во-вторых, они не будут этого делать из-за всех других способов, которыми другой код превосходит.
теперь, действительно, есть случаи, когда экономия нескольких наносекунд действительно важна, когда мы делаем что-то несколько миллиардов раз. Если производитель микросхем выбивает несколько наносекунд времени, необходимого для выполнения основной инструкции, это приведет к реальной победе.
С точки зрения кода, который мы могли бы сделать в C#, мы могли бы сделать оптимизацию, которая разматывается, хотя мы редко заботимся о времени.
предположим, мне нужно что-то сделать x раза.
во-первых, я делаю очевидное:
for(int i = 0; i != x; ++i)
DoSomething();
допустим, мое приложение в целом не так быстро, как мне нужно. Первое, что я делаю, это рассмотреть, что означает "быстро, как мне нужно", потому что, если это не кодирование для удовольствия (Эй, смешные усилия в погоне за скоростью могут быть забавными), это первое, что я хочу знать. Я получаю ответ на это, или, что более вероятно несколько ответов (минимально приемлемые, минимальные целевые, идеальные и маркетинговые-получить-хвастаться-о-как-быстро-это-может быть разных уровней).
затем я нахожу, какие биты фактического времени кода тратятся. Нет смысла оптимизировать что-то, что занимает 10ns в жизни приложения, когда другая часть, которая занимает 400 мс, вызывается внешним циклом 1,000 раз, когда пользователь нажимает кнопку, вызывая 4-секундную задержку.
тогда я пересматриваю все подход - это "делай раз" (который по сути о(х) во времени сложности), единственный способ достичь своей цели, или может я делаю что-то совершенно другое, что было возможно, о(ЛН х) (то есть, вместо того времени, пропорционального х требуется время, пропорциональное логарифму х). Могу ли я кэшировать некоторые результаты, чтобы для большего начального времени работы я мог сэкономить несколько миллисекунд много тысяч раз?
тогда я посмотрю, смогу ли я улучшить скорость DoSomething(). 99.9% из этого времени я бы сделал лучше, чем при изменении цикла, потому что это, вероятно, займет больше времени, чем пара наносекунд, которые занимает сам цикл.
и я мог бы сделать некоторые действительно ужасные unidiomatic и запутанные вещи в DoSomething() что я обычно считаю плохим кодом, потому что я буду знать, что это место, где это стоит (и я прокомментирую не только объяснить, как работает этот более запутанный код, но и почему это было сделано таким образом). И я измерю это. изменения, и, возможно, через несколько лет я измерю их снова, потому что самый быстрый подход к чему-то с текущей структурой на текущих процессорах может быть не самым быстрым подходом на .NET 6.5 теперь, когда мы переместили приложение на крутой новый сервер с последними чипами Intel, выпущенными в 2017 году.
вполне возможно, что у меня будет hand-inlined DoSomething() прямо в цикл, так как стоимость вызова функции почти наверняка больше, чем стоимость подхода к циклированию (но не совсем, конечно, могут быть сюрпризы только с тем, что попадает в джиттер и какие эффекты он имеет).
и, возможно, просто, возможно, я заменю фактический цикл чем-то вроде:
if(x > 0)
switch(x & 7)
{
case 0:
DoSomething();
goto case 7;
case 7:
DoSomething();
goto case 6;
case 6:
DoSomething();
goto case 5;
case 5:
DoSomething();
goto case 4;
case 4:
DoSomething();
goto case 3;
case 3:
DoSomething();
goto case 2;
case 2:
DoSomething();
goto case 1;
case 1:
DoSomething();
if((x -= 8) > 0)
goto case 0;
break;
}
потому что это способ объединить циклы преимуществ производительности, которые не занимают большого объема памяти инструкций, с преимуществами производительности, которые вы обнаружили, что размотка цикла вручную приводит к коротким циклам; он в значительной степени использует ваш подход для группы из 8 элементов и петли через куски 8.
Почему 8? потому что это разумная отправная точка; я бы измерил разные размеры, если бы это было так важно в моем коде. Единственный раз, когда я когда-либо делал это в реальном (не только для удовольствия) .NET-коде, я закончил делать куски 16.
и это только когда-либо, инструкция, вызываемая на каждой итерации, была очень короткой (12 Il-инструкций, которые соответствовали бы коду c#*x++ = *y++) и это был в коде, предназначенном для того, чтобы позволить другому коду делать что-то быстро и весь кодовый путь был тем, на который я избегаю попадать в большинстве случаев, с большей работой по выяснению, когда я лучше использовал или избегал его, чем в создании этого бита как можно быстрее.
в остальное время, либо размотка не экономит много (если что-нибудь), либо не сохраняет, где это имеет значение, или есть другие гораздо более насущные оптимизации, чтобы сделать раньше даже учитывая это.
Я, конечно, не начать с такого кода, это было бы само определение преждевременной оптимизации.
как правило, итерация выполняется быстро. Это известно другим кодерам. Это известно джиттеру (который может применять некоторые оптимизации в некоторых случаях). Это понятно. Она короткая. Он гибкий. Как правило, используя foreach также быстро, хотя и не так быстро, как итерация, и он еще более гибкий (есть всевозможные способы, которыми можно использовать IEnumerable реализации с большой эффективностью).
повторяющийся код более хрупкий, более вероятно, чтобы скрыть глупую ошибку (мы все пишем ошибки, которые заставляют нас думать, что "это было так глупо, что почти не достаточно хорошо, чтобы считать ошибкой", их легко исправить, пока вы можете их найти). Его сложнее поддерживать и, скорее всего, превратится во что-то еще более трудное для поддержания по мере продолжения проекта. Это трудно увидеть общую картину, и это в картине, что самые большие улучшения производительности могут быть сделаны.
в целом, причина, по которой парень на эпизоде канала 9 не предупредил вас, что что-то может сделать вашу программу, возможно, 10ns медленнее, в определенных обстоятельствах, он был бы смеяться.
Я ILDASM чтобы посмотреть на IL для цикла for против прямых назначений.
IL для прямого назначения, не используя цикл, выглядит так, повторяется еще 3 раза для каждого назначения:
IL_0007: ldloc.0
IL_0008: ldc.i4.0
IL_0009: ldc.i4.0
IL_000a: stelem.i4
IL для цикла for выглядит следующим образом:
IL_0017: ldc.i4.0
IL_0018: stloc.1
IL_0019: br.s IL_0023
IL_001b: ldloc.0
IL_001c: ldloc.1
IL_001d: ldloc.1
IL_001e: stelem.i4
IL_001f: ldloc.1
IL_0020: ldc.i4.1
IL_0021: add
IL_0022: stloc.1
IL_0023: ldloc.1
IL_0024: ldc.i4.4
IL_0025: blt.s IL_001b
IL_0027: ret
назначение массива выполняется по строкам IL_001b to IL_001e. Но, кроме этого, происходит еще кое-что.
первое, что происходит в цикле не назначение - это проверка того, что переменная цикла находится в диапазоне. Поэтому он ветвится на IL_0023, затем возвращается обратно до IL_001b для начала задания.
после назначения он затем должен увеличить счетчик циклов (IL_001f to IL_0022). Затем он снова проверяет переменную loop и ветви.
таким образом, вы можете видеть, что цикл имеет гораздо больше, чем прямое назначение. Как говорили другие - в этом и заключается преимущество разворачивания петли - запуск этого цикла накладных расходов реже, или избежать его вообще в вашем примере.
точки Джона о том, как JIT делает оптимизацию, также важны. При такой микромаркировке такие вещи, как кэш процессора и ветвление (что и делает цикл for), могут оказать серьезное влияние на производительность - потому что вы измеряете такие крошечные числа.
в конечном счете, если структура цикла дороже, чем операции внутри цикла и крошечные накладные расходы производительности от цикла на самом деле значительны, тогда у вас может быть случай для развертывания цикла. Но, скорее всего, у вас есть дизайн, который можно улучшить.