Почему numba быстрее, чем numpy здесь?
Я не могу понять, почему numba бьет numpy здесь (более 3x). Я сделал какую-то фундаментальную ошибку в том, как я оцениваю здесь? Кажется, идеальная ситуация для numpy, нет? Обратите внимание, что в качестве проверки я также запустил вариант, объединяющий numba и numpy (не показан), который, как ожидалось, был таким же, как запуск numpy без numba.
(кстати, это следующий вопрос: самый быстрый способ численно обрабатывать 2d-массив: dataframe vs series vs array vs numba )
import numpy as np
from numba import jit
nobs = 10000
def proc_numpy(x,y,z):
x = x*2 - ( y * 55 ) # these 4 lines represent use cases
y = x + y*2 # where the processing time is mostly
z = x + y + 99 # a function of, say, 50 to 200 lines
z = z * ( z - .88 ) # of fairly simple numerical operations
return z
@jit
def proc_numba(xx,yy,zz):
for j in range(nobs): # as pointed out by Llopis, this for loop
x, y = xx[j], yy[j] # is not needed here. it is here by
# accident because in the original benchmarks
x = x*2 - ( y * 55 ) # I was doing data creation inside the function
y = x + y*2 # instead of passing it in as an array
z = x + y + 99 # in any case, this redundant code seems to
z = z * ( z - .88 ) # have something to do with the code running
# faster. without the redundant code, the
zz[j] = z # numba and numpy functions are exactly the same.
return zz
x = np.random.randn(nobs)
y = np.random.randn(nobs)
z = np.zeros(nobs)
res_numpy = proc_numpy(x,y,z)
z = np.zeros(nobs)
res_numba = proc_numba(x,y,z)
результаты:
In [356]: np.all( res_numpy == res_numba )
Out[356]: True
In [357]: %timeit proc_numpy(x,y,z)
10000 loops, best of 3: 105 µs per loop
In [358]: %timeit proc_numba(x,y,z)
10000 loops, best of 3: 28.6 µs per loop
Я запустил это на macbook air 2012 года (13.3), стандартное распределение anaconda. Я могу предоставить более подробную информацию о моей настройке, если это актуально.
4 ответов
Я думаю, что этот вопрос подчеркивает (несколько) ограничения вызова предварительно скомпилированных функций с языка более высокого уровня. Предположим, в C++ вы пишете что-то вроде:
for (int i = 0; i != N; ++i) a[i] = b[i] + c[i] + 2 * d[i];
компилятор видит все это во время компиляции, все выражение. Здесь он может делать много действительно умных вещей, включая оптимизацию временных (и развертывание цикла).
в python, однако, рассмотрим, что происходит: при использовании numpy каждый " + " использует оператор перегрузка типов массивов np (которые являются просто тонкими оболочками вокруг смежных блоков памяти, т. е. массивов в смысле низкого уровня), и вызывает функцию fortran (или C++), которая делает добавление супер быстро. Но он просто делает одно дополнение и выплевывает временное.
мы видим, что в некотором роде, в то время как numpy является удивительным и удобным и довольно быстрым, он замедляет работу, потому что, хотя кажется, что он вызывает быстрый скомпилированный язык для тяжелой работы, компилятор не видит всю программу, он просто подает изолированные маленькие биты. И это очень вредно для компилятора, особенно современных компиляторов, которые очень умны и могут удаляться несколько инструкций за цикл, когда код хорошо написан.
Numba, с другой стороны, использовал jit. Таким образом, во время выполнения он может выяснить, что временные не нужны, и оптимизировать их. В принципе, у Numba есть шанс скомпилировать программу в целом, numpy может только назовите небольшие атомарные блоки, которые сами были предварительно скомпилированы.
когда вы просите numpy сделать:
x = x*2 - ( y * 55 )
это внутренне переведено на что-то вроде:
tmp1 = y * 55
tmp2 = x * 2
tmp3 = tmp2 - tmp1
x = tmp3
каждый из этих temps-это массивы, которые должны быть выделены, обработаны, а затем освобождены. Numba, с другой стороны, обрабатывает вещи по одному элементу за раз и не имеет дела с этими накладными расходами.
Numba обычно быстрее, чем Numpy и даже Cython (по крайней мере, в Linux).
вот сюжет (украден из Numba против Cython: Возьмите 2):
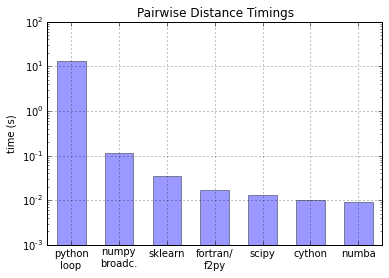
в этом тесте были вычислены попарные расстояния, поэтому это может зависеть от алгоритма.
обратите внимание, что это может отличаться на других платформах, см. Это для Winpython (от WinPython Cython учебник):
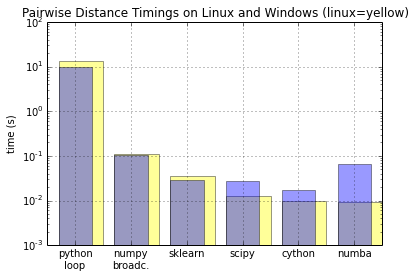
вместо того, чтобы загромождать исходный вопрос дальше, я добавлю еще несколько вещей здесь в ответ на Джеффа, Хайме, Veedrac:
def proc_numpy2(x,y,z):
np.subtract( np.multiply(x,2), np.multiply(y,55),out=x)
np.add( x, np.multiply(y,2),out=y)
np.add(x,np.add(y,99),out=z)
np.multiply(z,np.subtract(z,.88),out=z)
return z
def proc_numpy3(x,y,z):
x *= 2
x -= y*55
y *= 2
y += x
z = x + y
z += 99
z *= (z-.88)
return z
моя машина, кажется, работает немного быстрее сегодня, чем вчера, поэтому здесь они по сравнению с proc_numpy (proc_numba синхронизируется так же, как и раньше)
In [611]: %timeit proc_numpy(x,y,z)
10000 loops, best of 3: 103 µs per loop
In [612]: %timeit proc_numpy2(x,y,z)
10000 loops, best of 3: 92.5 µs per loop
In [613]: %timeit proc_numpy3(x,y,z)
10000 loops, best of 3: 85.1 µs per loop
обратите внимание,что,когда я писал proc_numpy2/3,я начал видеть некоторые побочные эффекты,поэтому я сделал копии x, y, z и передал копии вместо повторного использования x, y, z. Также, различные функции иногда имели небольшие различия в точности, поэтому некоторые из них не прошли тесты на равенство, но если вы их различаете, они действительно близки. Я предполагаю, что это связано с созданием или (не созданием) временных переменных. Например:
In [458]: (res_numpy2 - res_numba)[:12]
Out[458]:
array([ -7.27595761e-12, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, -7.27595761e-12, 0.00000000e+00])
кроме того, это довольно мелкие (около 10 МКС), но с использованием float литералы (55. вместо 55) также сэкономит немного времени для numpy, но не поможет numba.