Почему в JVM Integer хранится как байт и короткий?
вот один фрагмент кода
public class Classifier {
public static void main(String[] args)
{
Integer x = -127;//this uses bipush
Integer y = 127;//this use bipush
Integer z= -129;//this use sipush
Integer p=32767;//maximum range of short still sipush
Integer a = 128; // use sipush
Integer b = 129786;// invokes virtual method to get Integer class
}
}
вот частичный байтовый код этого
stack=1, locals=7, args_size=1
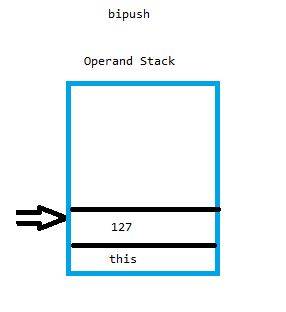
0: bipush -127
2: invokestatic #16 // Method java/lang/Integer.valueO
f:(I)Ljava/lang/Integer;
5: astore_1
6: bipush 127
8: invokestatic #16 // Method java/lang/Integer.valueO
f:(I)Ljava/lang/Integer;
11: astore_2
12: sipush -129
15: invokestatic #16 // Method java/lang/Integer.valueO
f:(I)Ljava/lang/Integer;
18: astore_3
19: sipush 32767
22: invokestatic #16 // Method java/lang/Integer.valueO
f:(I)Ljava/lang/Integer;
25: astore 4
27: sipush 128
30: invokestatic #16 // Method java/lang/Integer.valueO
f:(I)Ljava/lang/Integer;
33: astore 5
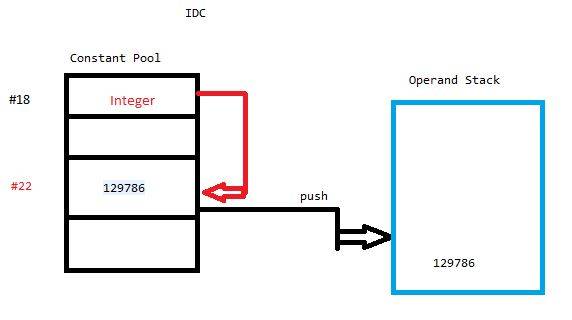
35: ldc #22 // int 129786
37: invokestatic #16 // Method java/lang/Integer.valueO
f:(I)Ljava/lang/Integer;
40: astore 6
42: return
как я вижу, для целого диапазона между -128 to 127 он использует bipush которые помещают байт в стек как целое значение.
В диапазоне -32768 to 32767 он использует short как класс оболочки as sipush. Для next он использует Integer. Что JVM использует byte и short для хранения целочисленного значения?
3 ответов
насколько я понял.
как вы можете из оставшейся инструкции байтового кода, она не хранит int as byte или short
Во-первых, почему bipush или short : bipush имеет 2 байта один для кода операции и второй для значения. я.Е, который может находиться в диапазоне от -128 127 тп (я.е 2 мощность 8)
Это экономит пространство и время исполнения. Как вы можете видеть из компилятора кода remianing создает ссылку на эту переменную как целочисленный тип
2: invokestatic #16 // Method java/lang/Integer.valueO
f:(I)Ljava/lang/Integer;
а то astore_1 что store what's on top of the stack i.e a reference here into local variable 1
Похожие для sipush где вы можете хранить значение из диапазона (-32768 to 32767) beacuse это набор инструкций 3 байта, один байт для кода операции и
отдохните два байта для значения (i.Э может держать силу 2 16)
теперь почему бы и нет lDC
JVM имеет постоянный пул для каждого типа. Байтовый код требует данных, но большую часть времени
эти данные слишком велики, чтобы хранить их непосредственно в байтовых кодах.
таким образом, он хранится в пуле констант, а байтовый код содержит ссылку на пул констант.
Что?!--12--> нажимает a constant #index из постоянного пула (String, int или float) в стек
Что потребляет дополнительное время и циклы
Вот примерное сравнение между ldc, а bipush операция
байт-код JVM ref здесь написано
где возможный, свой эффективный для использования одного из bipush, sipush, или одна из инструкций const вместо ldc.
он не хранится как byte или short во время выполнения, только в байт-коде.
Предположим, вы хотите сохранить значение 120 на Integer. Вы пишете компилятор, поэтому вы анализируете исходный код и знаете постоянное значение 120 может поместиться в один байт со знаком. Потому что вы не хотите тратить место в байт-коде для хранения значения 120 как 32-битное(4 байта) значение, если его можно сохранить в 8 бит (1 байт), вы создадите специальную инструкцию, которая сможет загрузить только один byte от байт-код метода и сохраните его в стеке как 32bit integer. Это означает, что во время выполнения у вас действительно есть integer тип данных.
полученный код меньше и быстрее, чем при использовании ldc везде, где необходимо более тесное взаимодействие с JVM в beceause манипуляции с пула константы этапа выполнения.
bipush имеет 2 байта, один байт кода операции, второй байт непосредственного значения constat. Поскольку у вас есть только один байт для значения, его можно использовать для значений между -128 и 127.
sipush имеет 3 байта, один байт кода операции, Второй и третий размер
постоянное значение.
bipush:
bipush
byte
sipush:
sipush
byte1
byte2
одной из причин могут быть преимущества, касающиеся байтового кода, которые были упомянуты в других ответах.
однако, можно также рассуждать об этом, начиная с язык. В частности, вы не хотите вставлять приведение, когда (постоянное) значение фактически представляется в целевом типе.
Итак, одна из причин наблюдаемого поведения: компилятор использует наименьший возможный тип который может представлять заданную константу значение.
для назначения на int (или Integer) это не было бы необходимо - но это не наносит никакого вреда, когда байт-код присваивает "меньший" тип "большему" типу. И наоборот, для меньших типов это is необходимо использовать меньший тип, поэтому использование "байт-кода для наименьшего типа" является поведением по умолчанию.
Это также неявно упоминается как "сужение времени компиляции постоянных выражений" в 5.2., Контексты Назначения спецификации языка Java:
сужающее примитивное преобразование может использоваться, если тип переменной-byte, short или char, а значение выражения константы можно представить в типе переменной.
...
сужение времени компиляции постоянных выражений означает, что код, такой как:
byte theAnswer = 42;разрешено. Без сужения, тот факт, что целое число литерал 42 имеет тип int будет означать, что приведение к байту потребуется:
byte theAnswer = (byte)42; // cast is permitted but not required