Подготовка сложного изображения для OCR
Я хочу распознавать цифры с кредитной карты. Что еще хуже, исходное изображение не гарантируется высоким качеством. OCR должен быть реализован через нейронную сеть, но это не должно быть темой здесь.
текущий вопрос-это предобработки изображения. Поскольку кредитные карты могут иметь фон и другую сложную графику, текст не так понятен, как при сканировании документа. Я провел эксперименты с обнаружением края (Canny Edge, Sobel), но это было не так успешный. Также вычисляется разница между изображением в оттенках серого и размытым (как указано в удалить цвет фона в обработке изображений для OCR) не привел к OCRable результату.
Я думаю, что большинство подходов не потому, что контраст между определенной цифрой и фоном не хватает. Вероятно, необходимо выполнить сегментацию изображения на блоки и найти лучшее решение предварительной обработки для каждого блока?
У вас есть любые предложения, как преобразовать источник в удобочитаемый двоичный образ? Является ли обнаружение края способом пойти или я должен придерживаться основного цветового порога?
вот пример подхода в градациях серого (где я, очевидно, не довольны результатом):
оригинальное изображение:

изображение в оттенках серого:

Thresholded image:
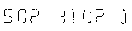
спасибо за любые советы, Валентин!--1-->
3 ответов
Если это вообще возможно, запросите лучшее освещение для захвата изображений. Низкоугольный свет будет освещать края поднятых (или затонувших) символов, что значительно улучшит качество изображения. Если изображение предназначено для анализа машиной, то освещение должно быть оптимизировано для считываемости машины.
тем не менее, один алгоритм, который вы должны изучить, - это преобразование ширины Штриха, которое используется для извлечения символов из естественных изображения.
реализация преобразования ширины Штриха (SWT) (Java, C#...)
глобальный порог (для бинаризации или сильных кромок обрезки), вероятно, не сократит его для этого приложения, и вместо этого вы должны посмотреть на локализованные пороги. В вашем примере изображения " 02 "после" 31 " особенно слабы, поэтому поиск самых сильных локальных ребер в этой области будет лучше, чем фильтрация всех ребер в символьной строке с помощью одного порог.
Если вы можете идентифицировать частичные сегменты символов, вы можете использовать некоторые операции направленной морфологии, чтобы помочь объединить сегменты. Например, если у вас есть два почти горизонтальных сегмента, как показано ниже, где 0-фон и 1-передний план...
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 1 1 1 1 0 0 1 1 1 1 1 1 0 0 0
0 0 0 1 0 0 0 1 0 1 0 0 0 0 1 0 0 0
затем вы можете выполнить морфологическую операцию "закрыть" вдоль горизонтального направления только для соединения этих сегментов. Ядро может быть чем-то как
x x x x x
1 1 1 1 1
x x x x x
существуют более сложные методы для выполнения завершения кривой с использованием Безье или даже спиралей Эйлера (a.к. a. clothoids), но предварительная обработка для идентификации присоединяемых сегментов и постобработка для устранения плохих соединений могут быть очень сложными.
способ, как я бы пошел о проблеме, это разделить карты в другой раздел. Есть не так много уникальных кредитных карт, чтобы начать с (MasterCard, Visa, список зависит от вас), поэтому вы можете сделать как выпадающий список, чтобы указать, какая кредитная карта это. Таким образом, вы можете исключить и указать область пикселей:
пример:
работа только с областью 20 пикселов от дна, 30 пикселов от влево на 10 пикселей справа до 30 пикселей снизу (создание прямоугольник) - это будет охватывать все MasterCards
когда я работал с программами обработки изображений (fun project), я увеличил контраст изображения, преобразовал его в серый масштаб, взял среднее значение каждого отдельного RGB-значения 1 пикселя и сравнил его со всеми вокруг пикселей:
пример:
PixAvg[i,j] = (Pix.R + Pix.G + Pix.B)/3
if ((PixAvg[i,j] - PixAvg[i,j+1])>30)
boolEdge == true;
30 было бы, насколько четко вы хотите, чтобы ваше изображение было. Чем ниже разница, чем ниже будет толерантность.
в моем проекте, чтобы просмотреть обнаружение края, я сделал отдельный массив булевых значений, который содержал значения из boolEdge, и массив пикселей. Пиксельный массив был заполнен только черными и белыми точками. Он получил значения из логического массива, где boolEdge = true-белая точка, а boolEdge = false-черная точка. Таким образом, в конце концов вы получите массив пикселей (полное изображение), который содержит только белые и черные точки.
оттуда, гораздо проще определить, где начинается число и где заканчивается число.
в моей реализации я попытался использовать код отсюда:http://rnd.azoft.com/algorithm-identifying-barely-legible-embossed-text-image/ результаты лучше, но недостаточно... мне трудно найти правильные параметры для текстурных карт.
(void)processingByStrokesMethod:(cv::Mat)src dst:(cv::Mat*)dst {
cv::Mat tmp;
cv::GaussianBlur(src, tmp, cv::Size(3,3), 2.0); // gaussian blur
tmp = cv::abs(src - tmp); // matrix of differences between source image and blur iamge
//Binarization:
cv::threshold(tmp, tmp, 0, 255, CV_THRESH_BINARY | CV_THRESH_OTSU);
//Using method of strokes:
int Wout = 12;
int Win = Wout/2;
int startXY = Win;
int endY = src.rows - Win;
int endX = src.cols - Win;
for (int j = startXY; j < endY; j++) {
for (int i = startXY; i < endX; i++) {
//Only edge pixels:
if (tmp.at<unsigned char="">(j,i) == 255)
{
//Calculating maxP and minP within Win-region:
unsigned char minP = src.at<unsigned char="">(j,i);
unsigned char maxP = src.at<unsigned char="">(j,i);
int offsetInWin = Win/2;
for (int m = - offsetInWin; m < offsetInWin; m++) {
for (int n = - offsetInWin; n < offsetInWin; n++) {
if (src.at<unsigned char="">(j+m,i+n) < minP) {
minP = src.at<unsigned char="">(j+m,i+n);
}else if (src.at<unsigned char="">(j+m,i+n) > maxP) {
maxP = src.at<unsigned char="">(j+m,i+n);
}
}
}
//Voiting:
unsigned char meanP = lroundf((minP+maxP)/2.0);
for (int l = -Win; l < Win; l++) {
for (int k = -Win; k < Win; k++) {
if (src.at<unsigned char="">(j+l,i+k) >= meanP) {
dst->at<unsigned char="">(j+l,i+k)++;
}
}
}
}
}
}
///// Normalization of imageOut:
unsigned char maxValue = dst->at<unsigned char="">(0,0);
for (int j = 0; j < dst->rows; j++) { //finding max value of imageOut
for (int i = 0; i < dst->cols; i++) {
if (dst->at<unsigned char="">(j,i) > maxValue)
maxValue = dst->at<unsigned char="">(j,i);
}
}
float knorm = 255.0 / maxValue;
for (int j = 0; j < dst->rows; j++) { //normalization of imageOut
for (int i = 0; i < dst->cols; i++) {
dst->at<unsigned char="">(j,i) = lroundf(dst->at<unsigned char="">(j,i)*knorm);
}
}