Получение данных из диаграммы, отображаемой на веб-сайте
меня попросили нарисовать такой график, как этот
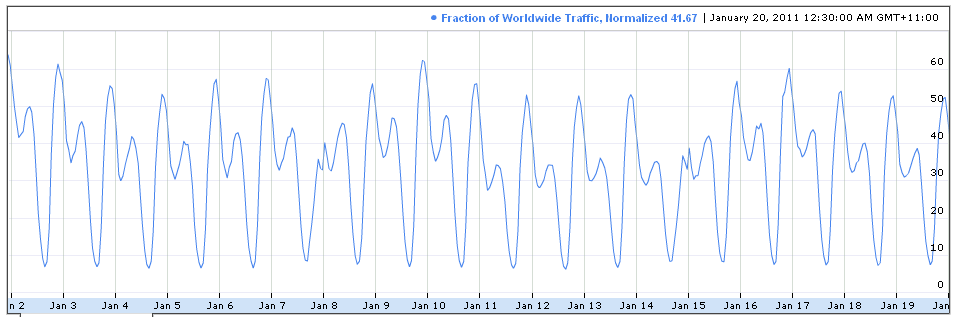
использование Latex (точнее, tikz и/или pgf). Это не было бы проблемой, если бы у меня были данные, но у меня их нет. Все, что у меня есть, это сайт откуда могут отображаться графики, но я не знаю, как получить данные оттуда.
Я провел день сегодня, пытаясь получить эти данные, в том числе писать в Google и использовать тип программного обеспечения, которое отслеживает линию и выводит точки графа, такого как Datathief и DigitizeIt, но мне это не удалось. Я думаю, что последнее не сработало, потому что линии на графике слишком тонкие и имеют более одного оттенка синего. Конечно, я пытался улучшить качество изображения с помощью программы Paint и Gimp, но я все еще не мог заставить его работать.
Я также попытался использовать eps2pgf, Java-скрипт, который преобразует цифры eps в код pgf, но даже это не работало для графиков, которые я сохранил с помощью Image Capture (mac) и Print Screen (Windows), и, честно говоря, это был бы мой последний вариант, так как это "подход грубой силы", выплевывающий уродливый код, который вы не можете улучшить.
после всего этого я решил начать изучать Python, потому что мой руководитель, человек, который попросил меня нарисовать эту картину с помощью tikz, сказал, что есть код Python для получения данных с таких сайтов. Теперь я даже не уверен, что Python выполнит эту работу (хотя я рад за предлог, чтобы узнать это), и, конечно, требуется время, чтобы узнать новый язык и сделать что-то подобное, поэтому я хочу знать, действительно ли есть способ получить данные с этого сайта, используя предпочтительно Python, но если нет, любой другой метод.
1 ответов
Ну, было бы здорово, если бы Google предоставил API для этих данных! Тем не менее, вы все еще можете соскрести некоторые данные с сайта. Вот как это сделать...
Установить Firebug
предпочитаю Палий для Firefox, но инструменты разработчика Chrome также должны работать.
расследование
Прежде всего, давайте посетим URL-адресом в вопросе и использовать Firebug попробовать и посмотреть, что происходит. Активируйте Firebug с помощью F12 или перейдите в меню Инструменты->Firebug->открыть Firebug. Сначала перейдите на вкладку Net и перезагрузите страницу. Это показывает все сделанные запросы и даст вам некоторое представление о том, как работает сайт. Обычно Flash-Плагины загружают данные извне, а не встроены в фактический плагин, и если вы посмотрите на запросы, вы увидите запрос с надписью POST service. Если вы наведете курсор на него, firebug покажет полный url-адрес, и вы увидите, что страница сделала запрос на http://www.google.com/transparencyreport/traffic/service. Вы можете нажать на запрос и посмотрите на отправленные заголовки, данные post, ответ и куки, используемые для выполнения запроса.
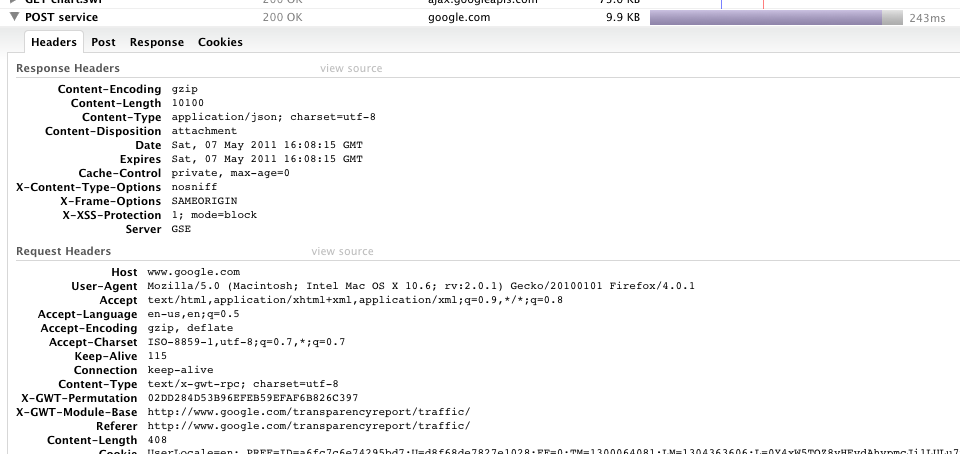
если вы посмотрите на ответ, вы увидите то, что кажется искаженным JSON. Из того, что я могу сказать, это, похоже, содержит список нормализованных точек данных трафика. Вы могли бы вырезать и вставить ответ из firebug, но так как это вопрос python, давайте работать немного сложнее.
получение данных в Питон
чтобы сделать запрос post успешно, нам нужно будет сделать (почти) все, что делает браузер. Мы можем немного обмануть и просто скопировать заголовки запросов и опубликовать данные из firebug, чтобы подделать реальные запрос.
заголовки и данные post
используйте тройные кавычки для вставки многострочных строк в оболочку. Скопируйте заголовки запроса и вставьте их.
>>> headers = """ <paste headers> """
далее преобразовать его в дикт для httplib2. Я собираюсь использовать понимание списка (который разбивает строку на основе новых строк, а затем разбивает строку на первую : и полосы, заканчивающиеся пробелами, что дает мне список двух элементов, которыеdict можно преобразовать в словарь), но вы можете сделать это так, как вы хотите. Вы также можете вручную создать dict, я просто нахожу это быстрее.
>>> headers = dict([[s.strip() for s in line.split(':', 1)]
for line in headers.strip().split('\n')])
и скопируйте данные post.

>>> body = """ <paste post data> """
сделать запрос Я собираюсь использовать httplib2 но есть несколько других http-клиентов и некоторые хорошие инструменты для очистки интернета, Как механизировать и scrapy. Мы сделаем запрос POST, используя url-адрес API, заголовки, которые мы скопировали, и данные post, которые мы скопировали из firebug. Запрос возвращает кортеж заголовков ответов и содержимого.
>>> import httplib2
>>> h = httplib2.Http()
>>> url = 'http://www.google.com/transparencyreport/traffic/service'
>>> resp, content = h.request(url, 'POST', body=body, headers=headers)
Массаж Данных
оригинальный формат действительно странный и только верхний бит кажется, содержит точки данных, так что я выкину остальное.
>>> cleaned = content.split("'")[0][4:-1] + ']'
теперь, когда он действителен JSON, мы можем десериализовать его в собственные типы данных python.
>>> import json
>>> data = json.loads(cleaned)
все точки, которые меня интересуют, являются поплавками, поэтому я буду фильтровать на основе этого.
>>> data = [x for x in data if type(x) == float]
Обработка / Сохранение Данных
теперь, когда у нас есть наши данные, проверьте его, выполните дополнительную обработку и т. д...
>>> data[:5]
<<<
[44.73874282836914,
45.4061279296875,
47.5350456237793,
44.56114196777344,
46.08817672729492]
...или просто сохранить он.
>>> with open('data.json', 'w') as f:
...: f.write(json.dumps(data))
мы могли бы также построить его с помощью pyplot С библиотек matplotlib (или какая-либо другая библиотека построения графиков/графиков).
>>> import matplotlib.pyplot as plt
>>> plt.plot(data)
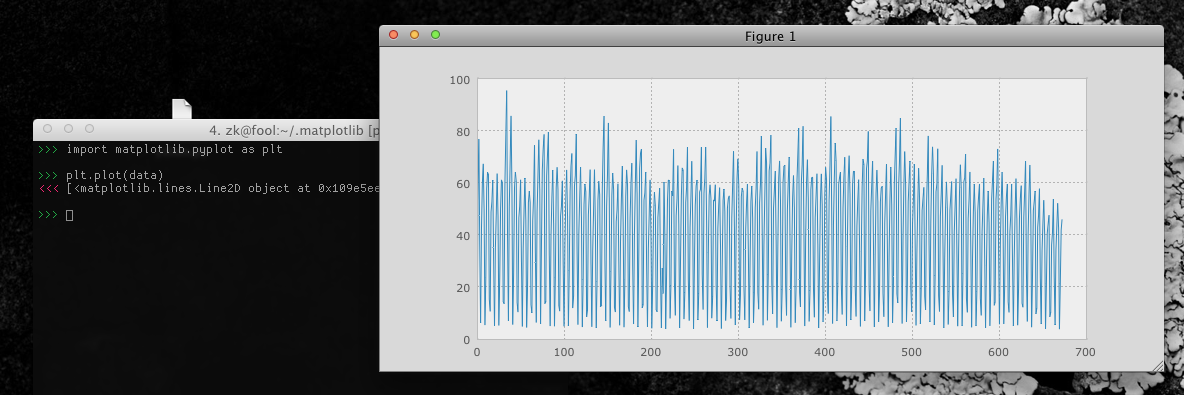
вывод
если вы просто заинтересованы в нескольких вещах, вы можете настроить диаграмму для отображения того, что вы хотите, а затем использовать заголовки запросов/данные post, используемые соответствующим запросом http://www.google.com/transparencyreport/traffic/service. Возможно, вы захотите проверить фактический ответ ближе, чем я, я просто отбросил части, которые не имели смысла для меня. Надеюсь, они выставят открытый API для этих данных.