Простое объяснение наивной классификации Байеса
Мне трудно понять процесс наивного Байеса, и мне было интересно, может ли кто-нибудь объяснить это простым пошаговым процессом на английском языке. Я понимаю, что в качестве вероятности требуется сравнение по временам, но я понятия не имею, как данные обучения связаны с фактическим набором данных.
пожалуйста, дайте мне объяснение, какую роль играет учебный набор. Я даю очень простой пример для фруктов здесь, как банан, например
training set---
round-red
round-orange
oblong-yellow
round-red
dataset----
round-red
round-orange
round-red
round-orange
oblong-yellow
round-red
round-orange
oblong-yellow
oblong-yellow
round-red
5 ответов
Ваш вопрос как я понимаю состоит из двух частей. Одно из них вам нужно больше понимания для наивного классификатора Байеса , а второе-путаница вокруг набора тренировок.
в целом все алгоритмы машинного обучения должны быть обучены для контролируемых учебных задач, таких как классификация, прогнозирование и т. д. или для неконтролируемых задач обучения, таких как кластеризация.
под обучением это означает обучать их на определенных входах, чтобы позже мы могли проверить их для неизвестных входов (которые они никогда не видели раньше), для которых они могут классифицировать или предсказывать и т. д. (В случае контролируемого обучения) на основе их обучения. Это то, что большинство методов машинного обучения, таких как нейронные сети, SVM, Байесовский и т. д. основаны на.
таким образом, в общем проекте машинного обучения в основном вы должны разделить свой входной набор на набор разработки (набор обучения + набор Dev-Test) и набор тестов (или набор оценки). Помните, что вашей основной целью было бы ваша система изучает и классифицирует новые входы, которые они никогда не видели раньше ни в наборе разработчиков, ни в тестовом наборе.
тестовый набор обычно имеет тот же формат, что и обучающий набор. Однако очень важно, чтобы набор тестов отличался от тренировочного корпуса: если мы просто повторное использование обучающего набора в качестве тестового набора, а затем модель, которая просто запоминает свой ввод, не учась обобщать на новые примеры, получит обманчиво высокие баллы.
In общие, например, 70% могут быть обучающими наборами. Также не забудьте разделить исходный набор на учебные и тестовые наборы случайно.
теперь я перехожу к вашему другому вопросу о наивном Байесе.
источник, например, ниже: http://www.statsoft.com/textbook/naive-bayes-classifier
чтобы продемонстрировать концепцию наивной классификации Байеса, рассмотрим приведенный пример ниже:
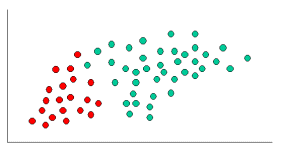
как указано, объекты могут быть классифицированы как GREEN или RED. Наша задача-классифицировать новые случаи по мере их поступления, т. е. решить, к какому классу они принадлежат, исходя из существующих в настоящее время объектов.
так как их вдвое больше GREEN объекты RED, разумно полагать, что новый случай (который еще не наблюдался) в два раза чаще будет иметь членство GREEN, а не RED. В байесовский анализ, это убеждение известно как априорная вероятность. Предыдущие вероятности основаны на предыдущем опыте, в этом случае процент GREEN и RED объекты, и часто используется для прогнозирования результатов, прежде чем они на самом деле произойдет.
таким образом, мы можем написать:
предварительная вероятность GREEN: number of GREEN objects / total number of objects
предварительная вероятность RED: number of RED objects / total number of objects
так как есть в общей сложности 60 предметы,40 из которых GREEN и 20 RED, наши предыдущие вероятности членства в классе:
до вероятности GREEN: 40 / 60
до вероятности RED: 20 / 60
сформулировав нашу предыдущую вероятность, мы теперь готовы классифицировать новый объект (WHITE круг на рисунке ниже). Поскольку объекты хорошо кластеризованы, разумно предположить, что чем больше GREEN (или RED) объекты в окрестности X, тем более вероятно, что новые случаи принадлежат этому конкретному цвету. Чтобы измерить эту вероятность, мы рисуем круг вокруг X, который охватывает число (выбираемое априори) точек независимо от их меток классов. Затем мы вычисляем количество точек в окружности, принадлежащих каждой метке класса. Из этого мы вычисляем вероятность:
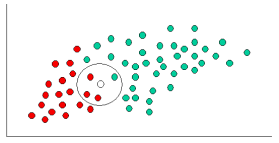
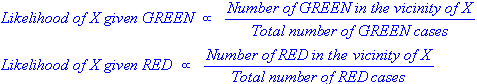
из иллюстрации выше, это ясно, что вероятность X дано GREEN меньше вероятность X дано RED, так как круг охватывает 1 GREEN объект и 3 RED те. Таким образом:
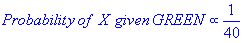
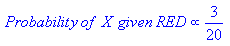
хотя предыдущие вероятности указывают на то, что X может принадлежать GREEN (учитывая, что их в два раза больше GREEN по сравнению с RED) вероятность указывает на обратное; что членство в классе X is RED (учитывая, что есть более RED объекты в непосредственной близости от X чем GREEN). В байесовском анализе окончательная классификация производится путем объединения обоих источников информации, т. е. предшествующей и вероятности, для формирования задней вероятности с использованием так называемого правила Байеса (названного в честь преподобного Томаса Байеса 1702-1761).

наконец, мы классифицируем X как RED так как его членство в классе достигает наибольшего заднего вероятность.
я понимаю, что это старый вопрос, с ответа. Причина, по которой я публикую, заключается в том, что принятый ответ имеет много элементов k-NN (k-ближайшие соседи), другой алгоритм.
как k-NN, так и NaiveBayes являются алгоритмами классификации. Концептуально k-NN использует идею "близости" для классификации новых сущностей. В k-NN "близость" моделируется такими идеями, как Евклидово расстояние или косинусное расстояние. Напротив, в NaiveBayes, в понятие "вероятность" используется для классификации новых объектов.
поскольку вопрос касается наивного Байеса, вот как я бы описал идеи и шаги кому-то. Я постараюсь сделать это как можно меньше уравнений и на простом английском языке.
Во-Первых, Условная Вероятность И Правило Байеса
прежде чем кто-то сможет понять и оценить нюансы наивного Байеса, им нужно сначала узнать пару связанных понятий, а именно идею Условная вероятность и правило Байеса. (Если вы знакомы с этими понятиями, перейдите к разделу добраться до наивного Байеса)
Условная Вероятность на простом английском языке: какова вероятность того, что что-то произойдет,учитывая, что что-то еще уже произошло.
предположим, что есть некоторый результат O. и некоторые доказательства E. Из способа определения этих вероятностей: вероятность имея и результат O и доказательство E: (Вероятность возникновения O), умноженная на (вероятность E, учитывая, что o произошло)
один пример для понимания условной вероятности:
Допустим у нас есть коллекция американских сенаторов. Сенаторы могут быть демократами или республиканцами. Они также либо мужчины, либо женщины.
если мы выберем одного сенатора совершенно случайным образом, какова вероятность того, что этот человек-женщина Демократ? Условная вероятность может помочь нам ответить на.
вероятность (демократ и женщина-сенатор)= Prob(сенатор-демократ), умноженная на условную вероятность быть женщиной, учитывая, что они демократ.
P(Democrat & Female) = P(Democrat) * P(Female | Democrat)
мы могли бы вычислить то же самое, наоборот:
P(Democrat & Female) = P(Female) * P(Democrat | Female)
Понимание Правила Байеса
концептуально это способ перейти от P(доказательства| известный результат) к P(результат|известные доказательства). Часто, мы знаем, как часто наблюдаются некоторые конкретные свидетельства,Дали известный результат!--19-->. Мы должны использовать этот известный факт для вычисления обратного, чтобы вычислить вероятность этого исход происходит, по данному факту.
P (результат, учитывая, что мы знаем некоторые доказательства) = P(доказательства, учитывая, что мы знаем результат) раз Prob(результат), масштабируется P(доказательство)
классический пример, чтобы понять правило Байеса:
Probability of Disease D given Test-positive =
Prob(Test is positive|Disease) * P(Disease)
_______________________________________________________________
(scaled by) Prob(Testing Positive, with or without the disease)
теперь, все это было лишь предисловием к наивному Байесу.
добраться до наивного Байеса
до сих пор мы говорили только об одной улики. На самом деле, мы должны предсказать результат, данный несколько доказательств. в этом случае математика очень сложна. Чтобы обойти это осложнение, один из подходов состоит в том, чтобы "расцепить" несколько частей доказательств и рассматривать каждую часть доказательств как независимую. Вот почему этот подход называется наивный Байеса.
P(Outcome|Multiple Evidence) =
P(Evidence1|Outcome) * P(Evidence2|outcome) * ... * P(EvidenceN|outcome) * P(Outcome)
scaled by P(Multiple Evidence)
многие люди предпочитают помнить это как:
P(Likelihood of Evidence) * Prior prob of outcome
P(outcome|evidence) = _________________________________________________
P(Evidence)
обратите внимание на несколько вещей об этом уравнении:
- если Prob (доказательство / результат) равно 1, то мы просто умножаем на 1.
- если проблема (некоторые конкретные доказательства|результат) равна 0, то вся проблема. становится 0. Если вы видите противоречащие доказательства, мы можем исключить этот результат.
- так как мы делим все на P (доказательство), мы можем даже уйти, не рассчитав его.
- интуиция, стоящая за умножением на до это так, что мы даем высокую вероятность более общих результатов и низкую вероятность маловероятных результатов. Они также называются
base ratesи они являются способом масштабирования наших предсказанных вероятностей.
как применить наивность, чтобы предсказать результат?
просто запустите формулу выше для каждого возможного результата. Так как мы пытаюсь классификация, каждый результат называется class и class label. наша задача-посмотреть на доказательства, рассмотреть, насколько вероятно, что это будет тот или иной класс, и назначить метку каждому объекту.
Опять же, мы принимаем очень простой подход: класс, который имеет наибольшую вероятность, объявляется "победителем", и эта метка класса присваивается этой комбинации доказательств.
Пример Фруктово
давайте попробуем это на примере, чтобы увеличить наше понимание: ОП попросила пример идентификации "фруктов".
предположим, что у нас есть данные на 1000 кусочков фруктов. Они банан, оранжевый или какой-нибудь Другие Фрукты. Мы знаем 3 Характеристики о каждом фрукте:
- ли это долго
- будь то сладкий и
- если его цвет желтый.
это наш тренировочный набор.'Мы будем использовать это предсказать тип новая фрукты мы сталкиваемся.
Type Long | Not Long || Sweet | Not Sweet || Yellow |Not Yellow|Total
___________________________________________________________________
Banana | 400 | 100 || 350 | 150 || 450 | 50 | 500
Orange | 0 | 300 || 150 | 150 || 300 | 0 | 300
Other Fruit | 100 | 100 || 150 | 50 || 50 | 150 | 200
____________________________________________________________________
Total | 500 | 500 || 650 | 350 || 800 | 200 | 1000
___________________________________________________________________
мы можем предварительно вычислить много вещей о нашей коллекции фруктов.
так называемые" предыдущие " вероятности. (Если бы мы не знали ни одного из атрибутов фруктов, это было бы нашей догадкой.) Это наши base rates.
P(Banana) = 0.5 (500/1000)
P(Orange) = 0.3
P(Other Fruit) = 0.2
вероятность "доказательств"
p(Long) = 0.5
P(Sweet) = 0.65
P(Yellow) = 0.8
вероятность "вероятность"
P(Long|Banana) = 0.8
P(Long|Orange) = 0 [Oranges are never long in all the fruit we have seen.]
....
P(Yellow|Other Fruit) = 50/200 = 0.25
P(Not Yellow|Other Fruit) = 0.75
учитывая фрукты, как классифицировать это?
допустим, нам даны свойства неизвестного плода, и нас попросили его классифицировать. Нам говорят, что плоды длинные, сладкие и желтые. Это банан? Это апельсин? Или это какой-то другой фрукт?
мы можем просто запустить числа для каждого из 3 результатов, один за другим. Затем мы выбираем самую высокую вероятность и "классифицируем" наш неизвестный плод как принадлежащий к классу, который имел самую высокую вероятность, основываясь на наших предыдущих доказательствах (наши 1000 фруктов учебный комплект):
P(Banana|Long, Sweet and Yellow)
P(Long|Banana) * P(Sweet|Banana) * P(Yellow|Banana) * P(banana)
= _______________________________________________________________
P(Long) * P(Sweet) * P(Yellow)
= 0.8 * 0.7 * 0.9 * 0.5 / P(evidence)
= 0.252 / P(evidence)
P(Orange|Long, Sweet and Yellow) = 0
P(Other Fruit|Long, Sweet and Yellow)
P(Long|Other fruit) * P(Sweet|Other fruit) * P(Yellow|Other fruit) * P(Other Fruit)
= ____________________________________________________________________________________
P(evidence)
= (100/200 * 150/200 * 50/200 * 200/1000) / P(evidence)
= 0.01875 / P(evidence)
подавляющим большинством голосов (0.252 >> 0.01875), мы классифицируем этот сладкий/длинный / желтый плод как, вероятно, банан.
почему классификатор Байеса настолько популярен?
посмотрите, к чему это в конечном итоге сводится. Просто подсчет и умножение. Мы можем предварительно вычислить все эти термины, и поэтому классификация становится простой, быстрой и эффективной.
Let z = 1 / P(evidence). теперь мы быстро вычисляем следующие три помногу.
P(Banana|evidence) = z * Prob(Banana) * Prob(Evidence1|Banana) * Prob(Evidence2|Banana) ...
P(Orange|Evidence) = z * Prob(Orange) * Prob(Evidence1|Orange) * Prob(Evidence2|Orange) ...
P(Other|Evidence) = z * Prob(Other) * Prob(Evidence1|Other) * Prob(Evidence2|Other) ...
назначьте метку класса в зависимости от того, какое число больше, и все готово.
несмотря на название, наивный Байес оказывается отличным в некоторых приложениях. Классификация текста - это одна из областей, где она действительно сияет.
надеюсь, что это поможет в понимании концепций наивного алгоритма Байеса.
Рам Нарасимхан очень хорошо объяснил концепцию здесь, ниже, альтернативное объяснение через пример кода наивного Байеса в действии
Он использует пример проблемы из этого книга на странице 351
Это набор данных, который мы будем использовать
В приведенном выше наборе данных, если мы дадим гипотезу = {"Age":'<=30', "Income":"medium", "Student":'yes' , "Creadit_Rating":'fair'} тогда какова вероятность того, что он купит или не купит компьютер.
Код ниже точно отвечает, что вопрос.
Просто создайте файл с именем new_dataset.csv и вставить следующее содержимое.
Age,Income,Student,Creadit_Rating,Buys_Computer
<=30,high,no,fair,no
<=30,high,no,excellent,no
31-40,high,no,fair,yes
>40,medium,no,fair,yes
>40,low,yes,fair,yes
>40,low,yes,excellent,no
31-40,low,yes,excellent,yes
<=30,medium,no,fair,no
<=30,low,yes,fair,yes
>40,medium,yes,fair,yes
<=30,medium,yes,excellent,yes
31-40,medium,no,excellent,yes
31-40,high,yes,fair,yes
>40,medium,no,excellent,no
вот код, комментарии, объясняет все, что мы делаем здесь! [python]
import pandas as pd
import pprint
class Classifier():
data = None
class_attr = None
priori = {}
cp = {}
hypothesis = None
def __init__(self,filename=None, class_attr=None ):
self.data = pd.read_csv(filename, sep=',', header =(0))
self.class_attr = class_attr
'''
probability(class) = How many times it appears in cloumn
__________________________________________
count of all class attribute
'''
def calculate_priori(self):
class_values = list(set(self.data[self.class_attr]))
class_data = list(self.data[self.class_attr])
for i in class_values:
self.priori[i] = class_data.count(i)/float(len(class_data))
print "Priori Values: ", self.priori
'''
Here we calculate the individual probabilites
P(outcome|evidence) = P(Likelihood of Evidence) x Prior prob of outcome
___________________________________________
P(Evidence)
'''
def get_cp(self, attr, attr_type, class_value):
data_attr = list(self.data[attr])
class_data = list(self.data[self.class_attr])
total =1
for i in range(0, len(data_attr)):
if class_data[i] == class_value and data_attr[i] == attr_type:
total+=1
return total/float(class_data.count(class_value))
'''
Here we calculate Likelihood of Evidence and multiple all individual probabilities with priori
(Outcome|Multiple Evidence) = P(Evidence1|Outcome) x P(Evidence2|outcome) x ... x P(EvidenceN|outcome) x P(Outcome)
scaled by P(Multiple Evidence)
'''
def calculate_conditional_probabilities(self, hypothesis):
for i in self.priori:
self.cp[i] = {}
for j in hypothesis:
self.cp[i].update({ hypothesis[j]: self.get_cp(j, hypothesis[j], i)})
print "\nCalculated Conditional Probabilities: \n"
pprint.pprint(self.cp)
def classify(self):
print "Result: "
for i in self.cp:
print i, " ==> ", reduce(lambda x, y: x*y, self.cp[i].values())*self.priori[i]
if __name__ == "__main__":
c = Classifier(filename="new_dataset.csv", class_attr="Buys_Computer" )
c.calculate_priori()
c.hypothesis = {"Age":'<=30', "Income":"medium", "Student":'yes' , "Creadit_Rating":'fair'}
c.calculate_conditional_probabilities(c.hypothesis)
c.classify()
выход:
Priori Values: {'yes': 0.6428571428571429, 'no': 0.35714285714285715}
Calculated Conditional Probabilities:
{
'no': {
'<=30': 0.8,
'fair': 0.6,
'medium': 0.6,
'yes': 0.4
},
'yes': {
'<=30': 0.3333333333333333,
'fair': 0.7777777777777778,
'medium': 0.5555555555555556,
'yes': 0.7777777777777778
}
}
Result:
yes ==> 0.0720164609053
no ==> 0.0411428571429
надеюсь, что это поможет лучше понять проблему
мирный
Наивный Байес: Наивный Байес попадает под контроль машинного обучения, которое используется для классификации наборов данных. Он используется для предсказания вещей на основе своих предварительных знаний и предположений о независимости.
они называют это наивный потому что это предположения (предполагается, что все объекты в наборе данных одинаково важны и независимы) действительно оптимистичны и редко верны в большинстве реальных приложений.
Это алгоритм классификации, который принимает решение для неизвестного набора данных. Он основан на Теорема Байеса которые описывают вероятность события, основанного на его предшествующих знаниях.
ниже диаграмма показывает, как наивный Байес работает
формула для предсказания NB:

Как использовать наивный алгоритм Байеса ?
давайте пример того, как N. B woks
Шаг 1: Сначала мы узнаем вероятность таблицы, которая показывает вероятность да или нет на диаграмме ниже. Шаг 2: Найдите заднюю вероятность каждого класса.

Problem: Find out the possibility of whether the player plays in Rainy condition?
P(Yes|Rainy) = P(Rainy|Yes) * P(Yes) / P(Rainy)
P(Rainy|Yes) = 2/9 = 0.222
P(Yes) = 9/14 = 0.64
P(Rainy) = 5/14 = 0.36
Now, P(Yes|Rainy) = 0.222*0.64/0.36 = 0.39 which is lower probability which means chances of the match played is low.
для получения дополнительной справки обратитесь к этим блог.
Обратитесь К Репозиторию GitHub Наивный Байес-Примеры
Я пытаюсь объяснить правило Байеса пример.
предположим, что вы знаете, что 10% из людей курильщики. Вы также знаете, что 90% курящих мужчин и 80% из них старше 20 лет.
теперь вы видите кого-то, кто это человек и 15 лет. Вы хотите знать, есть ли шанс, что он курильщик:
X = smoker | he is a man and under 20
так как вы знаете, что 10% людей курильщики ваши первоначальное предположение 10% (априорная вероятность ничего не зная о человеке), а другой доказательства (что он мужчина и ему 15) может повлиять на эту догадку.
каждое доказательство может увеличить или уменьшить этот шанс. Например, это то, что он человек мая увеличить шанс, при условии, что этот процент (будучи мужчиной) среди некурящих ниже, например, 40%. Другими словами, быть мужчиной-это хорошо. показатель того, что вы курильщик, а не некурящий.
мы можем показать этот вклад по-другому. Для каждого признака вам нужно сравнить общность (вероятность) этого признака (f) только с его общностью при заданных условиях. (P(f) vs. P(f | x). Например, если мы знаем, что вероятность быть мужчиной в обществе составляет 90%, а 90% курильщиков - тоже мужчины, то знание того, что кто-то мужчина, нам не поможет!--3-->. А если мужчина до 40% населения, но 90% курильщики, то зная, что кто-то является человеком увеличивает шансы быть курильщиком (10% * (90% / 40%) = 22.5% ). Точно так же, если вероятность быть мужчиной в обществе составляла 95%, то независимо от того, что процент мужчин среди курильщиков высок (90%)! доказательство того, что кто-то является человеком, уменьшает вероятность того, что он курильщик! (10% * (90% / 95%) = 9.5%).
Итак, мы имеем:
P(X) =
P(smoker)*
(P(being a man | smoker)/P(being a man))*
(P(under 20 | smoker)/ P(under 20))
обратите внимание, что в этой формуле мы предполагали, что человек и под 20 являются независимыми функциями, поэтому мы умножили их, это означает, что знание того, что кто-то моложе 20 лет не влияет на догадку, что он мужчина или женщина. Но это может быть неправдой, например, большинство подростков в обществе-мужчины...
использовать эту формулу в классификаторе
классификатор дается с некоторыми особенностями (будучи человеком и будучи до 20), и он должен решить, является ли он курильщиком или нет. Он использует приведенную выше формулу, чтобы найти это. К обеспечения требуемых вероятностей (90%, 10%, 80%...) он использует тренировочный набор. Например, он подсчитывает людей в тренировочном наборе, которые курят, и обнаруживает, что они вносят 10% выборки. Затем для курильщиков проверяет, сколько из них мужчины или женщины .... сколько выше 20 или в 20....