Простое распознавание цифр OCR в OpenCV-Python
Я пытаюсь реализовать "распознавание цифр OCR" в OpenCV-Python (cv2). Это только для учебных целей. Я хотел бы изучить функции KNearest и SVM в OpenCV.
у меня есть 100 образцов (т. е. изображения) каждой цифры. Я хотел бы тренироваться с ними.
есть пример letter_recog.py это поставляется с образцом OpenCV. Но я все еще не мог понять, как им пользоваться. Я не понимаю, что такое образцы, ответы и т. д. Кроме того, он загружает файл txt на во-первых, чего я сначала не понял.
позже, немного поискав, я смог найти letter_recognition.данные в образцах cpp. Я использовал его и сделал код cv2.KNearest в модели letter_recog.py (только для тестирования):
import numpy as np
import cv2
fn = 'letter-recognition.data'
a = np.loadtxt(fn, np.float32, delimiter=',', converters={ 0 : lambda ch : ord(ch)-ord('A') })
samples, responses = a[:,1:], a[:,0]
model = cv2.KNearest()
retval = model.train(samples,responses)
retval, results, neigh_resp, dists = model.find_nearest(samples, k = 10)
print results.ravel()
Он дал мне массив размером 20000, я не понимаю, что это такое.
вопросы:
1) Что такое letter_recognition.файл данных? Как создать этот файл из моих собственных данных набор?
2) Что значит results.reval() обозначим?
3) Как мы можем написать простой инструмент распознавания цифр с помощью letter_recognition.файл данных (KNearest или SVM)?
3 ответов
Ну, я решил потренироваться на своем вопросе, чтобы решить вышеуказанную проблему. Я хотел реализовать simpl OCR, используя функции KNearest или SVM в OpenCV. А ниже-что я сделал и как. ( это просто для обучения, как использовать KNearest для простых целей OCR).
1) мой первый вопрос был о letter_recognition.файл данных, который поставляется с образцами OpenCV. Я хотел знать, что в этом файле.
он содержит Письмо, наряду с 16 особенности этого письма.
и this SOF помог мне найти его. Эти 16 особенностей описаны в статьеLetter Recognition Using Holland-Style Adaptive Classifiers.
(Хотя я не понял некоторых особенностей в конце)
2) поскольку я знал, не понимая всех этих особенностей, трудно сделать этот метод. Я попробовал другие бумаги, но все они были немного трудными для новичка.
So I just decided to take all the pixel values as my features. (Я не волнует точность или производительность, я просто хотел, чтобы он работал, по крайней мере, с наименьшей точностью)
Я взял ниже изображение для моих данных обучения:
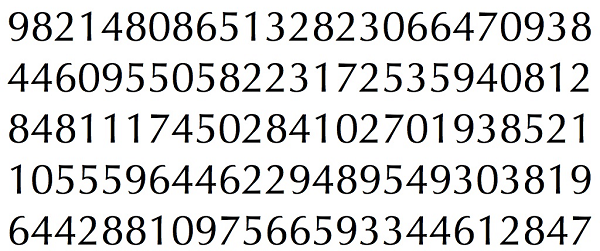
(Я знаю, что количество данных обучения меньше. Но, поскольку все буквы имеют одинаковый шрифт и размер, я решил попробовать это).
чтобы подготовить данные для обучения, я сделал небольшой код в OpenCV. Он делает следующие вещи:
A) он загружает изображение.
B) Выбирает цифры (очевидно, путем поиска контура и применения ограничений по площади и высоте букв, чтобы избежать ложных обнаружений).
C) рисует ограничивающий прямоугольник вокруг одной буквы и ждет key press manually. На этот раз мы!--9-- > нажмите цифровую клавишу сами соответствует букве в поле.
D) После нажатия соответствующей цифровой клавиши он изменяет размер этого поля на 10x10 и сохраняет 100 значений пикселей в массиве (здесь, образцы) и соответствующие введенные вручную цифра в другом массиве (здесь, ответы).
E) затем сохраните оба массива в отдельных txt-файлах.
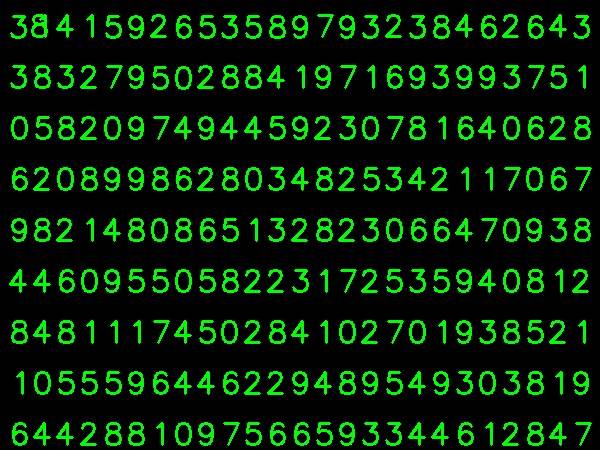
в конце ручной классификации цифр, все цифры в данных железнодорожного( железнодорожный.png) помечены вручную самостоятельно, изображение будет выглядеть следующим образом:

Ниже приведен код, который я использовал для указанной цели ( конечно, не так чисто):
import sys
import numpy as np
import cv2
im = cv2.imread('pitrain.png')
im3 = im.copy()
gray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray,(5,5),0)
thresh = cv2.adaptiveThreshold(blur,255,1,1,11,2)
################# Now finding Contours ###################
contours,hierarchy = cv2.findContours(thresh,cv2.RETR_LIST,cv2.CHAIN_APPROX_SIMPLE)
samples = np.empty((0,100))
responses = []
keys = [i for i in range(48,58)]
for cnt in contours:
if cv2.contourArea(cnt)>50:
[x,y,w,h] = cv2.boundingRect(cnt)
if h>28:
cv2.rectangle(im,(x,y),(x+w,y+h),(0,0,255),2)
roi = thresh[y:y+h,x:x+w]
roismall = cv2.resize(roi,(10,10))
cv2.imshow('norm',im)
key = cv2.waitKey(0)
if key == 27: # (escape to quit)
sys.exit()
elif key in keys:
responses.append(int(chr(key)))
sample = roismall.reshape((1,100))
samples = np.append(samples,sample,0)
responses = np.array(responses,np.float32)
responses = responses.reshape((responses.size,1))
print "training complete"
np.savetxt('generalsamples.data',samples)
np.savetxt('generalresponses.data',responses)
теперь мы входим в обучение и тестирование часть.
для тестирования части я использовал ниже изображение, которое имеет тот же тип букв, которые я использовал для обучения.

для обучения мы делаем следующее:
A) загрузите файлы txt, которые мы уже сохранили ранее
B) создайте экземпляр классификатора, который мы используем (здесь, это KNearest)
C) тогда мы используем KNearest.поезд функция для тренировки данных
для целей испытания, мы делаем как следует:
A) мы загружаем изображение, используемое для тестирования
B) обработайте изображение как раньше и извлеките каждую цифру с помощью методов контура
C) нарисуйте ограничивающую рамку для него, затем измените размер до 10x10 и сохраните его значения пикселей в массиве, как это было сделано ранее.
D) тогда мы используем KNearest.функция find_nearest (), чтобы найти ближайший элемент к тому, который мы дали. (Если повезет, он узнает правильную цифру.)
Я включил последние два шага ( обучение и тестирование) в одном коде ниже:
import cv2
import numpy as np
####### training part ###############
samples = np.loadtxt('generalsamples.data',np.float32)
responses = np.loadtxt('generalresponses.data',np.float32)
responses = responses.reshape((responses.size,1))
model = cv2.KNearest()
model.train(samples,responses)
############################# testing part #########################
im = cv2.imread('pi.png')
out = np.zeros(im.shape,np.uint8)
gray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
thresh = cv2.adaptiveThreshold(gray,255,1,1,11,2)
contours,hierarchy = cv2.findContours(thresh,cv2.RETR_LIST,cv2.CHAIN_APPROX_SIMPLE)
for cnt in contours:
if cv2.contourArea(cnt)>50:
[x,y,w,h] = cv2.boundingRect(cnt)
if h>28:
cv2.rectangle(im,(x,y),(x+w,y+h),(0,255,0),2)
roi = thresh[y:y+h,x:x+w]
roismall = cv2.resize(roi,(10,10))
roismall = roismall.reshape((1,100))
roismall = np.float32(roismall)
retval, results, neigh_resp, dists = model.find_nearest(roismall, k = 1)
string = str(int((results[0][0])))
cv2.putText(out,string,(x,y+h),0,1,(0,255,0))
cv2.imshow('im',im)
cv2.imshow('out',out)
cv2.waitKey(0)
и это сработало, ниже результат, который я получил:

здесь он работал со 100% точностью. Я предполагаю, что это потому, что все цифры имеют одинаковый вид и одинаковый размер.
но в любом случае, это хорошее начало для начинающих ( я надеюсь).
для тех, кто интересуется кодом C++, см. ниже код. Спасибо Рахман Абид для хорошего объяснения.
процедура такая же, как и выше, но поиск контура использует только контур первого уровня иерархии, так что алгоритм использует только внешний контур для каждой цифры.
код для создания образца и метки данных
//Process image to extract contour
Mat thr,gray,con;
Mat src=imread("digit.png",1);
cvtColor(src,gray,CV_BGR2GRAY);
threshold(gray,thr,200,255,THRESH_BINARY_INV); //Threshold to find contour
thr.copyTo(con);
// Create sample and label data
vector< vector <Point> > contours; // Vector for storing contour
vector< Vec4i > hierarchy;
Mat sample;
Mat response_array;
findContours( con, contours, hierarchy,CV_RETR_CCOMP, CV_CHAIN_APPROX_SIMPLE ); //Find contour
for( int i = 0; i< contours.size(); i=hierarchy[i][0] ) // iterate through first hierarchy level contours
{
Rect r= boundingRect(contours[i]); //Find bounding rect for each contour
rectangle(src,Point(r.x,r.y), Point(r.x+r.width,r.y+r.height), Scalar(0,0,255),2,8,0);
Mat ROI = thr(r); //Crop the image
Mat tmp1, tmp2;
resize(ROI,tmp1, Size(10,10), 0,0,INTER_LINEAR ); //resize to 10X10
tmp1.convertTo(tmp2,CV_32FC1); //convert to float
sample.push_back(tmp2.reshape(1,1)); // Store sample data
imshow("src",src);
int c=waitKey(0); // Read corresponding label for contour from keyoard
c-=0x30; // Convert ascii to intiger value
response_array.push_back(c); // Store label to a mat
rectangle(src,Point(r.x,r.y), Point(r.x+r.width,r.y+r.height), Scalar(0,255,0),2,8,0);
}
// Store the data to file
Mat response,tmp;
tmp=response_array.reshape(1,1); //make continuous
tmp.convertTo(response,CV_32FC1); // Convert to float
FileStorage Data("TrainingData.yml",FileStorage::WRITE); // Store the sample data in a file
Data << "data" << sample;
Data.release();
FileStorage Label("LabelData.yml",FileStorage::WRITE); // Store the label data in a file
Label << "label" << response;
Label.release();
cout<<"Training and Label data created successfully....!! "<<endl;
imshow("src",src);
waitKey();
код для обучения и тестирования
Mat thr,gray,con;
Mat src=imread("dig.png",1);
cvtColor(src,gray,CV_BGR2GRAY);
threshold(gray,thr,200,255,THRESH_BINARY_INV); // Threshold to create input
thr.copyTo(con);
// Read stored sample and label for training
Mat sample;
Mat response,tmp;
FileStorage Data("TrainingData.yml",FileStorage::READ); // Read traing data to a Mat
Data["data"] >> sample;
Data.release();
FileStorage Label("LabelData.yml",FileStorage::READ); // Read label data to a Mat
Label["label"] >> response;
Label.release();
KNearest knn;
knn.train(sample,response); // Train with sample and responses
cout<<"Training compleated.....!!"<<endl;
vector< vector <Point> > contours; // Vector for storing contour
vector< Vec4i > hierarchy;
//Create input sample by contour finding and cropping
findContours( con, contours, hierarchy,CV_RETR_CCOMP, CV_CHAIN_APPROX_SIMPLE );
Mat dst(src.rows,src.cols,CV_8UC3,Scalar::all(0));
for( int i = 0; i< contours.size(); i=hierarchy[i][0] ) // iterate through each contour for first hierarchy level .
{
Rect r= boundingRect(contours[i]);
Mat ROI = thr(r);
Mat tmp1, tmp2;
resize(ROI,tmp1, Size(10,10), 0,0,INTER_LINEAR );
tmp1.convertTo(tmp2,CV_32FC1);
float p=knn.find_nearest(tmp2.reshape(1,1), 1);
char name[4];
sprintf(name,"%d",(int)p);
putText( dst,name,Point(r.x,r.y+r.height) ,0,1, Scalar(0, 255, 0), 2, 8 );
}
imshow("src",src);
imshow("dst",dst);
imwrite("dest.jpg",dst);
waitKey();
результат
в результате точка в первой строке определяется как 8 и мы не обучены точка. Также я рассматриваю каждый контур на первом уровне иерархии как образец ввода, пользователь может избежать этого, вычисляя область.
Если вы заинтересованы в состоянии искусства в машинном обучении, вы должны смотреть в глубокое обучение. Вы должны иметь CUDA поддержки GPU или альтернативно использовать GPU на Amazon Web Services.
Google Udacity имеет хороший учебник по этому вопросу с помощью Поток Тензора. Этот учебник научит вас, как тренировать свой собственный классификатор на рукописных цифрах. Я получил точность более 97% на тестовом наборе с использованием сверточных сетей.