Различия между int и uuid в mysql
если я поставил primary ключ в int типа (auto increment) или установите его в UUID, в чем разница между этими двумя в производительности базы данных (select, insert ...) и почему?
2 ответов
UUID возвращает универсальный уникальный идентификатор (hopefuly также уникален, если импортирован в другую БД)
цитата из MySQL doc (акцент мой):
UUID разработан как число, которое глобально уникально в космосе и время. Ожидается, что два вызова UUID() будут генерировать два разных ценности, даже если эти вызовы выполняются на двух отдельных компьютеры!--39--> которые не связаны друг с другом.
С другой стороны, просто INT первичный id ключ (e.G autoincrement) вернет уникальное целое число для конкретной таблицы DB и DB, но которая не universaly уникальный (так что, если импортировать в другую БД, скорее всего, будут конфликты первичного ключа)
С точки зрения производительности, не должно быть никакой заметной разницы с помощью auto-increment над UUID. Наиболее сообщения (в том числе некоторые авторы этого сайта), состояние как таковое. Конечно!--0--> может занять немного больше времени (и пространства), но это не является узким местом для большинства (если не всех) случаях. Наличие столбца как Primary Key должен сделать оба варианта равными wrt производительности. См. ссылки ниже:
- до
UUIDили неUUID? - мифы
GUIDvsAutoincrement - производительность:
UUIDvsauto-incrementв CakePHP-mysql UUIDпроизводительность в MySQL?- Первичные Ключи:
IDs противGUIDs (кодирование хоррор)
(UUID vs auto-increment результаты производительности, адаптированные из мифы GUID vs Autoincrement)
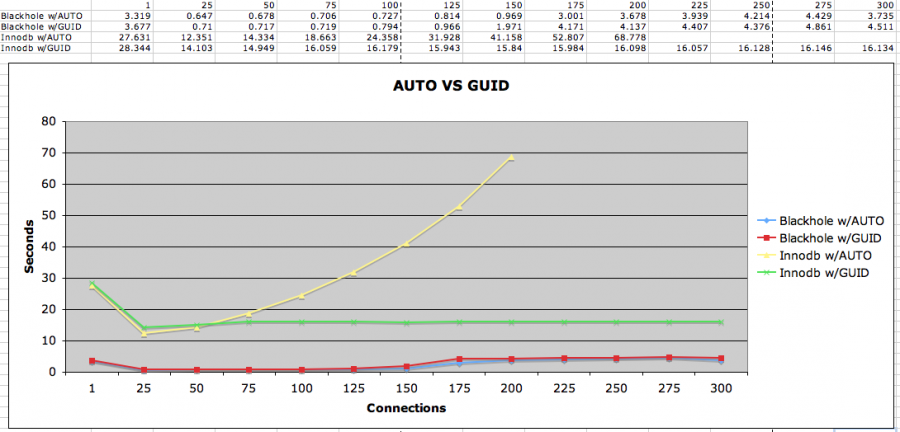
UUID плюсы / минусы (взято из Первичные Ключи: IDs против GUIDs)
GUIDплюсы
- уникально через каждую таблицу, каждую базу данных, каждый сервер
- позволяет легко объединять записи из разных баз данных
- позволяет легко распределять базы данных по нескольким серверам
- вы можете создать
IDs в любом месте, вместо того, чтобы туда и обратно в базу данных- большинство сценариев репликации требует
GUIDстолбцы в любом случае
GUIDминусы
- это колоссальное 4 раза больше, чем традиционное 4-байтовое значение индекса; это может иметь серьезные последствия для производительности и хранения, если ты не осторожен!--64-->
- громоздкий для отладки (
where userid='{BAE7DF4-DDF-3RG-5TY3E3RF456AS10}')- созданный
GUIDs должен быть частично последовательный для лучшей производительности (например,newsequentialid()на SQL 2005) и включить использование кластеризованный индексы.
Примечание я бы внимательно прочитал упомянутые ссылки и решил, следует ли использовать UUID или нет в зависимости от моего варианта использования. Тем не менее, во многих случаях UUIDs было бы действительно предпочтительнее. Например, можно создать UUIDs без использования / доступа к базе данных вообще или даже использовать UUIDs, которые были предварительно вычислены и / или сохранены где-то еще. Кроме того, вы можете легко обобщить/обновить схему базы данных и/или кластеризации схема без необходимости беспокоиться о IDs ломать и причинять конфликты.
ключ UUID не может быть pk до тех пор, пока не будет сохранен в DB, поэтому круглое отключение произойдет до тех пор, пока вы не сможете принять его pk без успешной транзакции. Большинство UUID используют time based, mac based, name based или какой-то случайный uuid. Учитывая, что мы активно продвигаемся к развертываниям на основе контейнеров, и у них есть шаблон для запуска MAC-адресов последовательности, полагающихся на mac-адреса, не будет работать. Time based не гарантирует, поскольку предполагается, что системы всегда находятся в точной синхронизации времени что иногда неверно, так как часы не следуют правилам. GUID не может гарантировать, что столкновение никогда не произойдет, только то, что в данный короткий период времени оно не произойдет, но при наличии достаточного времени и систем, работающих параллельно, и распространения систем, которые гарантируют, что в конечном итоге потерпят неудачу. [http://www.ietf.org/rfc/rfc4122.txt].