Разница между HBase и Hadoop/HDFS
Это своего рода наивный вопрос, но я новичок в парадигме NoSQL и мало знаю об этом. Поэтому, если кто-то может помочь мне четко понять разницу между HBase и Hadoop или дать некоторые указатели, которые могут помочь мне понять разницу.
до сих пор я провел некоторые исследования и acc. насколько я понимаю, Hadoop предоставляет платформу для работы с необработанным куском данных (файлов) в HDFS, а HBase-это компонент database engine выше Hadoop, который в основном работает со структурированными данными вместо необработанного куска данных. Hbase предоставляет логический слой над HDFS так же, как и SQL. Правильно ли это?
Pls чувствуют свободными исправить меня.
спасибо.
5 ответов
Hadoop-это в основном 3 вещи, FS (распределенная файловая система Hadoop), вычислительная платформа (MapReduce) и мост управления (Еще один переговорщик ресурсов). HDFS позволяет хранить огромные объемы данных распределенным (обеспечивает более быстрый доступ для чтения / записи) и избыточным (обеспечивает лучшую доступность) способом. И MapReduce позволяет обрабатывать эти огромные данные распределенным и параллельным образом. Но MapReduce не ограничивается только HDFS. Будучи FS, HDFS не хватает случайного возможность чтения / записи. Это хорошо для последовательного доступа к данным. И вот где HBase входит в картину. Это база данных NoSQL, которая работает поверх кластера Hadoop и предоставляет вам случайный доступ для чтения/записи в режиме реального времени к вашим данным.
вы можете хранить как структурированные, так и неструктурированные данные в Hadoop и HBase. Оба они предоставляют вам несколько механизмов доступа к данным, таких как оболочка и другие API. И, HBase хранит данные как пары ключ / значение в столбчатой моде пока HDFS хранит данные в виде плоских файлов. Некоторые из характерных особенностей обеих систем:
Hadoop
- оптимизирован для потокового доступа к большим файлам.
- следует писать-однажды прочитал - много идеологии.
- не поддерживает случайное чтение/запись.
HBase
- хранит пары ключ / значение в столбчатой моде (столбцы объединены вместе как столбец свои семьи.)
- обеспечивает доступ с низкой задержкой к небольшим объемам данных из большого набора данных.
- предоставляет гибкую модель данных.
Hadoop наиболее подходит для автономной пакетной обработки, в то время как HBase используется, когда у вас есть потребности в реальном времени.
аналогичное сравнение было бы между MySQL и Ext4.
Apache Hadoop проект включает в себя четыре ключевых модуля
- Hadoop И Общие: общие утилиты, поддерживающие другие модули Hadoop.
- распределенная файловая система Hadoop (HDFS™): распределенная файловая система, обеспечивающая доступ с высокой пропускной способностью к данным приложения.
- пряжа Hadoop: основой для планирования заданий и управления ресурсами кластера.
- в Hadoop В MapReduce: A пряжа-система для параллельной обработки больших массивов данных.
HBase - это масштабируемая распределенная база данных, поддерживающая структурированное хранение данных для больших таблиц. Так же, как Bigtable использует распределенное хранилище данных, предоставляемое файловой системой Google, Apache HBase предоставляет возможности Bigtable-like поверх Hadoop и HDFS.
когда использовать В HBase:
- если ваше приложение имеет переменную схему, где каждая строка немного отличается
- если вы обнаружите, что ваши данные хранятся в коллекциях, то все они имеют одинаковое значение
- Если вам нужен случайный, в режиме реального времени доступ для чтения / записи к вашим большим данным.
- Если вам нужен ключ доступа к данным при сохранении или извлечении.
- если у вас есть огромное количество данных с существующим Hadoop кластер
но HBase имеет некоторые ограничения
- его нельзя использовать для классических транзакционных приложений или даже реляционной аналитики.
- он также не является полной заменой HDFS при выполнении большого пакета MapReduce.
- он не говорит SQL, имеет оптимизатор, поддерживает транзакции с перекрестными записями или соединения.
- его нельзя использовать со сложными шаблонами доступа (такими как присоединяется)
резюме:
рассмотрим HBase при загрузке данных по ключу, поиске данных по ключу (или диапазону), обслуживании данных по ключу, запросе данных по ключу или при хранении данных по строкам, которые не соответствуют схеме.
посмотрите на Do и не HBase из для Cloudera блог.
Hadoop использует распределенную файловую систему i.E HDFS для хранения bigdata.Но есть определенные ограничения HDFS и для преодоления этих ограничений появились базы данных NoSQL, такие как HBase,Cassandra и Mongodb.
Hadoop может выполнять только пакетную обработку, и доступ к данным будет осуществляться только последовательным образом. Это означает, что нужно искать весь набор данных даже для простейших заданий.Огромный набор данных при обработке приводит к другому огромному набору данных, который также следует обрабатывать последовательно. На этом этапе необходимо новое решение для доступа к любой точке данных в одной единице времени (произвольный доступ).
как и все другие файловые системы, HDFS предоставляет нам хранилище, но отказоустойчивым образом с высокой пропускной способностью и меньшим риском потери данных(из-за репликации).Но , будучи файловой системой, HDFS не имеет случайного доступа для чтения и записи. Вот где HBase входит в картину. Это распределенное, масштабируемое, большое хранилище данных, смоделированное после Google BigTable. Кассандра несколько похожа на hbase.
и HBase и HDFS в одном изображении

Примечание:
Проверьте демонов HDFS (выделено зеленым цветом), как DataNode (серверы совместного региона) и NameNode в кластере с HBase и Hadoop HDFS
файловой системы HDFS - это распределенная файловая система, которая хорошо подходит для хранения больших файлов. который не обеспечивает быстрый индивидуальный запись поиска в файлах.
HBase, С другой стороны, построен поверх HDFS и обеспечивает быстрый поиск записей (и обновления) для больших таблиц. Иногда это может быть точкой концептуальной путаницы. HBase внутренне помещает ваши данные в индексированные "StoreFiles", которые существуют на HDFS для высокоскоростных поисков.
как это выглядит?
ну, на уровне инфраструктуры, каждая машина salve в кластере имеет следующие демоны
- Сервер Региона-HBase
- узел данных-HDFS
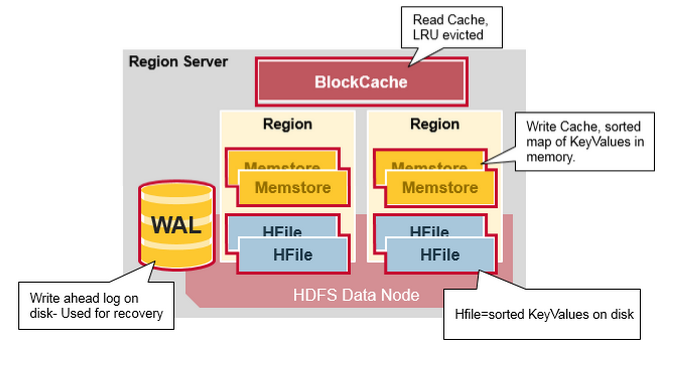
как это быстро с поисками?
HBase обеспечивает быстрый поиск HDFS (иногда и других распределенных файловых систем) в качестве базового хранилища, используя следующую модель данных
-
таблица
- таблица HBase состоит из нескольких строки.
-
Row
- строка в HBase состоит из ключа строки и одного или нескольких столбцов со значениями, связанными с ними. Строки сортируются в алфавитном порядке по ключу строки по мере их хранения. По этой причине, дизайн ключа строки очень важен. Цель состоит в том, чтобы хранить данные таким образом, чтобы связанные строки были рядом друг с другом. Общий шаблон ключа строки-это домен веб-сайта. Если ключи строк являются доменами, их следует хранить в реверс (org.апаш.www, org.апаш.mail, org.апаш.jira). Таким образом, все домены Apache находятся рядом друг с другом в таблице, а не распределяются на основе первой буквы поддомена.
-
колонки
- столбец в HBase состоит из семейства столбцов и классификатора столбцов, которые разделены символом : (двоеточие).
-
Семейство Столбцов
- семьи физически объединяют набор столбцов и их значения, часто по соображениям производительности. Каждое семейство столбцов имеет набор свойств хранения, например, следует ли кэшировать его значения в памяти, как сжимаются его данные или кодируются ключи строк и другие. Каждая строка в таблице имеет одинаковые семейства столбцов, хотя данная строка может ничего не хранить в данном семействе столбцов.
Спецификатор Столбца
- колонки классификатор добавляется в семейство столбцов для предоставления индекса для данного фрагмента данных. Учитывая содержимое семейства столбцов, классификатором столбцов может быть content: html, а другим-content: pdf. Хотя семейства столбцов фиксируются при создании таблицы, квалификаторы столбцов изменчивы и могут сильно отличаться между строками.
ячейка
- ячейка представляет собой комбинацию строки, семейства столбцов и классификатора столбцов и содержит значение и метку времени, который представляет версию значения.
метка
- метка времени записывается вместе с каждым значением, и является идентификатором для данной версии значение. По умолчанию метка времени представляет время на сервере RegionServer, когда данные были записаны, но можно указать другое значение метки времени при вводе данных в ячейку.
запрос на чтение клиента поток:
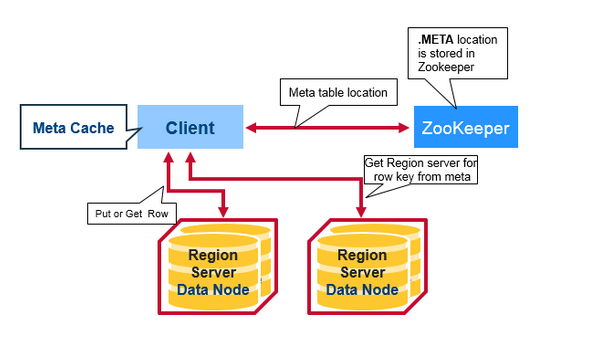
что такое мета-таблица на приведенном выше рисунке?
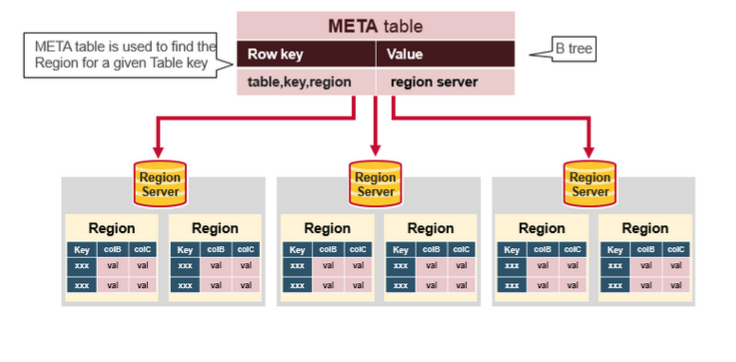
после всей информации, поток чтения HBase для поиска касается этих объектов
- во-первых, сканер ищет ячейки строки заблокировать кэш - кэша чтения. Недавно прочитанные значения ключей кэшируются здесь, а наименее недавно использованные вытесняются, когда память необходимый.
- далее сканер смотрит в MemStore кэширование записи в памяти, содержащий самые последние записи.
- если сканер не найдет все ячейки строк в кэше MemStore и Block, то HBase будет использовать индексы кэша блоков и фильтры bloom для загрузки HFiles в память, которая может содержать ячейки целевой строки.
источники и дополнительная информация:
ссылка:http://www.quora.com/What-is-the-difference-between-HBASE-and-HDFS-in-Hadoop
Hadoop-общее название для нескольких подсистем: 1) файловая система HDFS. Распределенная файловая система, которая распределяет данные по кластеру машин, заботящихся о резервировании и т. д 2) Карта Уменьшить. Система управления заданиями поверх HDFS-для управления map-reduce (и другими типами) заданий, обрабатывающих данные, хранящиеся в HDFS.
в основном это означает, что его автономная система-вы храните данные в HDFS, и вы можете обрабатывать их, выполняя задания.
HBase, с другой стороны, в базе данных на основе столбцов. Он использует HDFS в качестве хранилища , которое заботится о backup\redundency\etc, но его "интернет-магазин" - это означает, что вы можете запросить его для конкретной строки\строк и т. д. и получить немедленное значение.