Реализация эмпирической функции распределения Python (ecdf)
Я в курсе statsmodels.инструменты.инструменты.ECDF но поскольку вычисление эмпричной кумулятивной функции распределения (ECDF) довольно прямолинейно, и я хочу свести к минимуму зависимости в моем проекте, я хочу закодировать его вручную.
в данной list() / np.array() Pandas.Series, ECDF для каждого элемента можно вычислить как дано в Википедии:
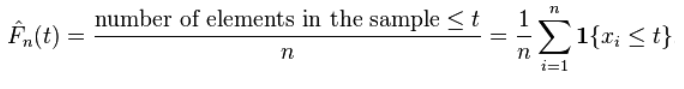
у меня есть фрейм данных Pandas,dfser ниже, и я хотите получить ecdf
1 ответов
так как вы уже используете pandas Я думаю, что будет глупо не использовать некоторые из его особенностей:
In [15]:
import numpy as np
from numpy import *
sq=ser.value_counts()
sq.sort_index().cumsum()*1./len(sq)
Out[15]:
2.083520e-12 0.058824
1.283440e-09 0.117647
8.517870e-09 0.176471
4.282550e-08 0.235294
1.121860e-07 0.294118
3.336140e-07 0.352941
4.276430e-07 0.411765
8.974670e-07 0.470588
2.018990e-06 0.529412
2.912570e-06 0.588235
9.761900e-06 0.647059
1.394780e-05 0.705882
1.937330e-05 0.764706
3.506300e-05 0.823529
1.209630e-04 0.882353
1.788900e-04 0.941176
1.732035e-02 1.000000
dtype: float64
и сравнение скорости
In [19]:
%timeit sq.sort_index().cumsum()*1./len(sq)
1000 loops, best of 3: 344 µs per loop
In [18]:
%timeit ser.value_counts().sort_index().cumsum()*1./len(ser.value_counts())
1000 loops, best of 3: 1.58 ms per loop
In [17]:
%timeit [sum( ser <= x)/float(len(ser)) for x in ser]
100 loops, best of 3: 3.31 ms per loop
если все значения уникальны, то ser.value_counts() больше не нужен. Эта часть медленная (получение уникальных значений). Все, что вам нужно в этом случае просто вроде ser.
In [23]:
%timeit np.arange(1, ser.size+1)/float(ser.size)
10000 loops, best of 3: 11.6 µs per loop
самая быстрая версия, которую я могу придумать, - это использовать GET vectorized:
In [35]:
np.sum(dfser['values'].values[...,newaxis]<=dfser['values'].values.reshape((1,-1)), axis=0)*1./dfser['values'].size
Out[35]:
array([ 0.55555556, 0.33333333, 0.5 , 0.61111111, 0.77777778,
0.94444444, 0.88888889, 0.44444444, 0.38888889, 0.11111111,
0.72222222, 0.27777778, 0.66666667, 0.22222222, 0.16666667,
0.83333333, 1. , 0.11111111])
добавить давайте см.:
In [37]:
%timeit dfser['ecdf']=[sum( dfser['values'] <= x)/float(dfser['values'].size) for x in dfser['values']]
100 loops, best of 3: 6 ms per loop
In [38]:
%%timeit
dfser['rank'] = dfser['values'].rank(ascending = 0)
dfser['ecdf_r']=(len(dfser)-dfser['rank']+1)/len(dfser)
1000 loops, best of 3: 827 µs per loop
In [39]:
%timeit np.sum(dfser['values'].values[...,newaxis]<=dfser['values'].values.reshape((1,-1)), axis=0)*1./dfser['values'].size
10000 loops, best of 3: 91.1 µs per loop