Реализация взаимной информации Python
У меня возникли некоторые проблемы с реализацией функции взаимной информации, которую предоставляют библиотеки машинного обучения Python, в частности : sklearn.метрика.mutual_info_score(labels_true, labels_pred, многовариантное=нет)
(http://scikit-learn.org/stable/modules/generated/sklearn.metrics.mutual_info_score.html)
Я пытаюсь реализовать пример, который я нахожу на сайте учебника Стэнфордского НЛП:
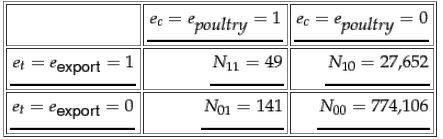
сайт находится здесь: http://nlp.stanford.edu/IR-book/html/htmledition/mutual-information-1.html#mifeatsel2
проблема в том, что я продолжаю получать разные результаты, еще не выясняя причину.
Я получаю концепцию взаимной информации и выбора функций, я просто не понимаю, как она реализована в Python. Я предоставляю метод mutual_info_score с двумя массивами на основе примера сайта NLP, но он выводит разные результаты. Другим интересным фактом является то, что в любом случае вы играете и меняете номера на этих массивах, вы, скорее всего, получите тот же результат. Должен ли я использовать другую структуру данных, специфичную для Python, или в чем проблема? Если кто-то успешно использовал эту функцию в прошлом, это было бы очень полезно для меня, спасибо за ваше время.
2 ответов
я столкнулся с той же проблемой сегодня. После нескольких попыток я нашел настоящую причину: вы берете log2, если вы строго следовали учебнику НЛП, но sklearn.метрика.mutual_info_score использует натуральный логарифм (база e, номер Эйлера). Я не нашел эту деталь в документации sklearn...
Я проверил это:
import numpy as np
def computeMI(x, y):
sum_mi = 0.0
x_value_list = np.unique(x)
y_value_list = np.unique(y)
Px = np.array([ len(x[x==xval])/float(len(x)) for xval in x_value_list ]) #P(x)
Py = np.array([ len(y[y==yval])/float(len(y)) for yval in y_value_list ]) #P(y)
for i in xrange(len(x_value_list)):
if Px[i] ==0.:
continue
sy = y[x == x_value_list[i]]
if len(sy)== 0:
continue
pxy = np.array([len(sy[sy==yval])/float(len(y)) for yval in y_value_list]) #p(x,y)
t = pxy[Py>0.]/Py[Py>0.] /Px[i] # log(P(x,y)/( P(x)*P(y))
sum_mi += sum(pxy[t>0]*np.log2( t[t>0]) ) # sum ( P(x,y)* log(P(x,y)/( P(x)*P(y)) )
return sum_mi
если вы измените этот np.log2 to np.log, Я думаю, это даст вам такой же ответ, как sklearn. Единственная разница заключается в том, что когда этот метод возвращает 0, sklearn вернет число, близкое к 0. (И, конечно, используйте sklearn, если вы не заботитесь о базе журналов, мой код предназначен только для демонстрации, он дает низкую производительность...)
к вашему сведению, 1)sklearn.metrics.mutual_info_score принимает списки, а также np.массива; 2) в sklearn.metrics.cluster.entropy использует также журнал, а не log2
Edit: что касается "того же результата", я не уверен, что вы действительно имеете в виду. В общем, значения в векторах на самом деле не имеют значения, важно "распределение" значений. Вы заботитесь о P (X=x), P(Y=y) и P (X=x,Y=y), а не значение x,y.
приведенный ниже код должен содержать результат: 0.00011053558610110256
c=np.concatenate([np.ones(49), np.zeros(27652), np.ones(141), np.zeros(774106) ])
t=np.concatenate([np.ones(49), np.ones(27652), np.zeros(141), np.zeros(774106)])
computeMI(c,t)