Regex с незахватывающие группы В C#
Я использую следующее регулярное выражение
JOINTS.*s*(?:(d*s*S*s*S*s*S*)rns*)*
по следующему типу данных:
JOINTS DISPL.-X DISPL.-Y ROTATION
1 0.000000E+00 0.975415E+01 0.616921E+01
2 0.000000E+00 0.000000E+00 0.000000E+00
идея состоит в том, чтобы извлечь две группы, каждая из которых содержит строку (начиная с совместного номера, 1, 2 и т. д.) Код C# выглядит следующим образом:
string jointPattern = @"JOINTS.*s*(?:(d*s*S*s*S*s*S*)rns*)*";
MatchCollection mc = Regex.Matches(outFileSection, jointPattern );
foreach (Capture c in mc[0].Captures)
{
JointOutput j = new JointOutput();
string[] vals = c.Value.Split();
j.Joint = int.Parse(vals[0]) - 1;
j.XDisplacement = float.Parse(vals[1]);
j.YDisplacement = float.Parse(vals[2]);
j.Rotation = float.Parse(vals[3]);
joints.Add(j);
}
однако это не работает: вместо того, чтобы возвращать две захваченные группы (внутреннюю группу), он возвращает одну группу: весь блок, включая заголовки столбцов. Почему это происходит? Имеет ли C# дело с un-captured группы по-разному?
наконец, являются ли RegExes лучшим способом сделать это? (Я действительно чувствую, что у меня теперь две проблемы.)
4 ответов
mc[0].Captures эквивалентно mc[0].Groups[0].Captures. Groups[0] всегда относится ко всему матчу, поэтому будет только один захват, связанный с ним. Часть, которую вы ищете, захвачена в группе #1, поэтому вы должны использовать mc[0].Groups[1].Captures.
но ваше регулярное выражение предназначено для соответствия всему входу в одной попытке, поэтому Matches() метод всегда возвращает MatchCollection только с одним совпадением в нем (при условии, что совпадение успешно). Вы также можете использовать Match() вместо этого:
Match m = Regex.Match(source, jointPattern);
if (m.Success)
{
foreach (Capture c in m.Groups[1].Captures)
{
Console.WriteLine(c.Value);
}
}
выход:
1 0.000000E+00 0.975415E+01 0.616921E+01
2 0.000000E+00 0.000000E+00 0.000000E+00
Я бы просто не использовать Regex для тяжелого подъема и разбора текста.
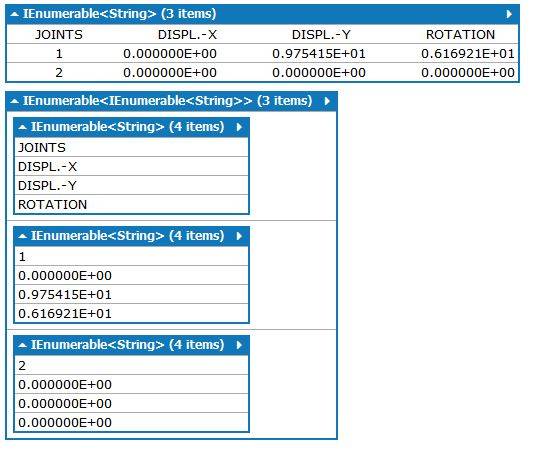
var data = @" JOINTS DISPL.-X DISPL.-Y ROTATION
1 0.000000E+00 0.975415E+01 0.616921E+01
2 0.000000E+00 0.000000E+00 0.000000E+00";
var lines = data.Split('\r', '\n').Where(s => !string.IsNullOrWhiteSpace(s));
var regex = new Regex(@"(\S+)");
var dataItems = lines.Select(s => regex.Matches(s)).Select(m => m.Cast<Match>().Select(c => c.Value));
почему бы просто не захватить ценности, и игнорировать остальные. Вот регулярное выражение, которое получает значения.
string data = @"JOINTS DISPL.-X DISPL.-Y ROTATION
1 0.000000E+00 0.975415E+01 0.616921E+01
2 0.000000E+00 0.000000E+00 0.000000E+00";
string pattern = @"^
\s+
(?<Joint>\d+)
\s+
(?<ValX>[^\s]+)
\s+
(?<ValY>[^\s]+)
\s+
(?<Rotation>[^\s]+)";
var result = Regex.Matches(data, pattern, RegexOptions.Multiline | RegexOptions.IgnorePatternWhitespace | RegexOptions.ExplicitCapture)
.OfType<Match>()
.Select (mt => new
{
Joint = mt.Groups["Joint"].Value,
ValX = mt.Groups["ValX"].Value,
ValY = mt.Groups["ValY"].Value,
Rotation = mt.Groups["Rotation"].Value,
});
/* result is
IEnumerable<> (2 items)
Joint ValX ValY Rotation
1 0.000000E+00 0.975415E+01 0.616921E+01
2 0.000000E+00 0.000000E+00 0.000000E+00
*/
есть две проблемы: повторяющаяся часть (?:...) не соответствует должным образом; и .* жаден и потребляет весь вход, поэтому повторяющаяся часть никогда не совпадает, даже если это возможно.
используйте этот код:
JOINTS.*?[\r\n]+(?:\s*(\d+\s*\S*\s*\S*\s*\S*)[\r\n\s]*)*
это имеет не жадную ведущую часть, гарантирует, что соответствующая строке часть начинается на новой строке (не в середине заголовка) и использует [\r\n\s]* в случае, если строки не так, как вы ожидаете.
лично я бы использовала regexes для этого, но мне нравятся regexes: -) если вы знаете, что структура строки всегда будет [title][newline][newline][lines], то, возможно, более просто (если менее гибко) просто разделить на новые строки и обработать соответственно.
наконец, вы можете использовать regex101.com или один из многих других сайтов тестирования регулярных выражений для отладки регулярных выражений.