Роль смещения в нейронных сетях
Я знаю о градиентном спуске и теореме обратного распространения. Что я не понимаю: когда важно использовать предвзятость и как вы ее используете?
например, при отображении AND функция, когда я использую 2 входа и 1 выход, он не дает правильные веса, однако, когда я использую 3 входа (1 из которых является смещением), он дает правильные веса.
16 ответов
Я думаю, что предубеждения почти всегда полезны. В сущности,значение смещения позволяет смещать функцию активации влево или вправо, которые могут иметь решающее значение для успешного обучения.
Это может помочь взглянуть на простой пример. Рассмотрим эту 1-входную, 1-выходную сеть, которая не имеет смещения:
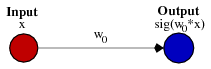
выход сети вычисляется путем умножения входного сигнала (x) на вес (w0) и прохождения результат через некоторую функцию активации (например, сигмовидную функцию.)
вот функция, которую вычисляет эта сеть, для различных значений w0:
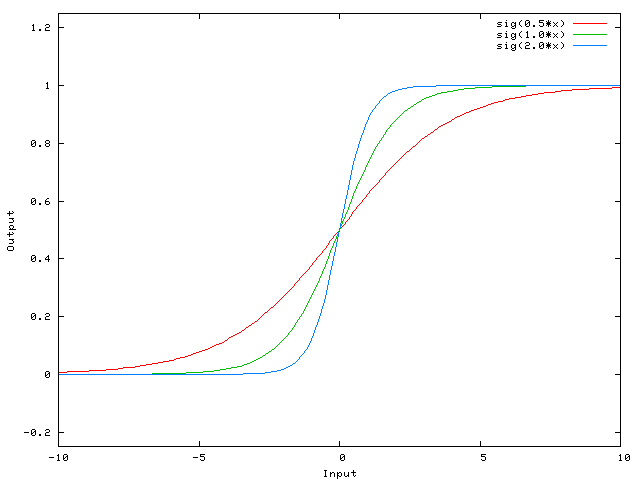
изменение веса w0 существенно изменяет "крутизну" сигмовидной кости. Это полезно, но что, если вы хотите, чтобы сеть выводила 0, когда x равно 2? Просто изменение крутизны сигмовидной кости не сработает ... --1-->вы хотите иметь возможность сдвиньте всю кривую вправо.
Это именно то, что позволяет вам делать смещение. Если мы добавим смещение к этой сети, например:
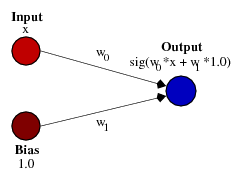
...тогда выход сети становится sig(w0 * x + w1*1.0). Вот как выглядит выход сети для различных значений w1:
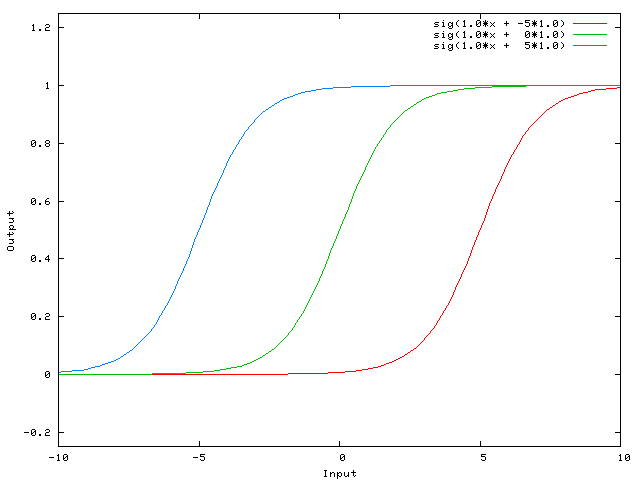
имея вес -5 для w1 сдвигает кривую справа, что позволяет нам иметь сеть, которая выводит 0, когда x равно 2.
просто добавить мои два цента.
более простой способ понять, что такое смещение: оно как-то похоже на константу b линейной функции
y = ax + b
Это позволяет перемещать линию вверх и вниз, чтобы лучше соответствовать прогнозу с данными. Без b линия всегда проходит через начало координат (0, 0), и вы можете сделать более пригодный.
2 различных вида параметров могут отрегулируйте во время тренировки Энн, веса и значение в функция активации. Это непрактично и было бы легче, если бы только один из параметров должен быть отрегулированный. Чтобы справиться с этой проблемой изобретен нейрон смещения. Предвзятость нейрон лежит в одном слое, соединен всем нейронам в следующем слое, но нет в предыдущем слое и это всегда выдает 1. С момента смещения нейрона выдает 1 весы, связанные с нейрон смещения, добавлены сразу к совокупность других Весов (уравнение 2.1), Как и значение t в функциях активации.1
причина, по которой это непрактично, заключается в том, что вы одновременно регулируете вес и значение, поэтому любое изменение веса может нейтрализовать изменение значения, которое было полезно для предыдущего экземпляра данных... добавление нейрона смещения без изменения значения позволяет контролируйте поведение слоя.
кроме того, смещение позволяет использовать одну нейронную сеть для представления подобных случаев. Рассмотрим и булеву функцию, представленную следующей нейронной сетью:
Энн http://www.aihorizon.com/images/essays/perceptron.gif
{kind=link}
- w0 соответствует b.
- w1 соответствует x1.
- w2 соответствует x2.
одиночный персептрон можно использовать к представляют множество булевых функций.
например, если мы принимаем логические значения из 1 (true) и -1 (false), то один способ использования двухвходового перцептрона для выполнять и функцию установить веса w0 = -3 и w1 = w2 = .5. Этот персептрон можно сделать к вместо этого представьте функцию OR от изменение порога на w0 = -.3. В факт, и и или можно рассматривать как частные случаи функций m-of-n: то есть функции, где, по крайней мере, м N входов в персептрон должны быть истинный. Функция OR соответствует m = 1 и функция AND для m = n. Любая функция m-of-n легко представлено с помощью персептрона установка всех входных Весов одинаковыми значение (например, 0.5), а затем установка порог w0 соответственно.
перцептронов может представлять все примитивные булевы функции и, или, NAND (1 и), и NOR ( 1 или). Машинное Обучение-Том Митчелл)
порог смещения и w0 - вес, связанный с нейроном смещения/порога.
слой в нейронной сети без смещения - это не что иное, как умножение входного вектора с матрицей. (Выходной вектор может быть передан через сигмовидную функцию для нормализации и для использования в многослойной ANN впоследствии, но это не важно.)
Это означает, что вы используете линейную функцию и, таким образом, вход всех нулей всегда будет отображаться на выход всех нулей. Это может быть разумным решением для некоторых систем, но в целом это слишком ограничительный.
используя смещение, вы эффективно добавляете другое измерение к своему входному пространству, которое всегда принимает значение one, поэтому вы избегаете входного вектора всех нулей. Вы не теряете общности, потому что ваша обученная матрица веса не должна быть сюръективной, поэтому она все еще может сопоставляться со всеми ранее возможными значениями.
2d ANN:
для отображения ANN двух измерений в одно измерение, как при воспроизведении AND или OR (или XOR) функции, вы можете думать о нейронной сети, как делать следующее:
на 2d плоскости отметьте все позиции входных векторов. Так, для логических значений, вы захотите пометить (-1,-1), (1,1), (-1,1), (1,-1). Теперь ваша ANN рисует прямую линию на 2d-плоскости, отделяя положительные выходные данные от отрицательных выходных значений.
без смещения эта прямая линия должна пройти через ноль, тогда как с смещением вы можете поместить ее куда угодно. Итак, вы увидите, что без смещения вы сталкиваетесь с проблемой с функцией AND, так как вы не можете поставить оба (1,-1) и (-1,1) в отрицательную сторону. (Им не позволено быть on линии.) Проблема равна для функции OR. С уклоном, однако, легко провести черту.
обратите внимание, что функция XOR в этой ситуации не может быть решена даже с уклоном.
когда вы используете ANNs, вы редко знаете о внутренних системах, которые вы хотите узнать. Некоторые вещи нельзя узнать без предубеждения. Например, взгляните на следующие данные: (0, 1), (1, 1), (2, 1), в основном функция, которая отображает любой x в 1.
Если у вас есть однослойная сеть (или линейное отображение), вы не можете найти решение. Однако, если у вас есть предубеждение, это тривиально!
в идеальной обстановке смещение может также сопоставлять все точки со средним значением цели точки и пусть скрытые нейроны моделируют различия с этой точки.
просто добавить ко всему этому то, чего очень не хватает и чего остальные, скорее всего, не знали.
Если вы работаете с изображениями,вы можете вообще не использовать смещение. Теоретически, таким образом, ваша сеть будет более независимой от величины данных, например, будет ли изображение темным или ярким и ярким. И сеть научится делать свою работу, изучая относительность внутри ваших данных. Многие современные нейронные сети используют этот.
для других данных, имеющих смещения, может быть критическим. Это зависит от того, с какими данными вы имеете дело. Если ваша информация инвариантна по величине - - - - при вводе [1,0,0.1] должно привести к тому же результату, что и при вводе [100,0,10], вам может быть лучше без смещения.
в паре экспериментов в магистерской диссертации (например, стр. 59), я обнаружил, что смещение может быть важно для первого слоя(ов), но особенно на полностью связанных слоях в конце, похоже, не играет большой роли.
Это может сильно зависеть от сетевой архитектуры / набора данных.
модификация Весов нейронов только служит для манипулирования фигуры/кривизна вашей передаточной функции, а не ее равновесие/ноль точка пересечения.
введение смещение нейроны позволяют сдвигать кривую передаточной функции по горизонтали (влево/вправо) вдоль входной оси, оставляя форму/кривизну неизменной. Это позволит сети производить произвольные выходы, отличные от значений по умолчанию, и, следовательно, вы можете настроить/переместить отображение ввода-вывода в соответствии с вашими конкретными потребностями.
см. здесь для графического объяснения: http://www.heatonresearch.com/wiki/Bias
расширение на @ zfy объяснение... Уравнение для одного входа, одного нейрона, одного выхода должно выглядеть:
y = a * x + b * 1 and out = f(y)
где x-значение входного узла, а 1-значение узла смещения; y может быть непосредственно вашим выходом или передаваться в функцию, часто сигмовидную функцию. Также обратите внимание, что смещение может быть любой константой, но чтобы сделать все проще, мы всегда выбираем 1 (и, вероятно, это настолько распространено, что @zfy сделал это, не показывая и не объясняя это).
ваш сеть пытается изучить коэффициенты a и b, чтобы адаптироваться к вашим данным.
Таким образом, вы можете понять, почему добавление элемента b * 1 позволяет уместить больше данных: теперь вы можете изменить наклон и смещение.
если у вас есть более одного входа, ваше уравнение будет выглядеть так:
y = a0 * x0 + a1 * x1 + ... + aN * 1
обратите внимание, что уравнение по-прежнему описывает один нейрон, одну выходную сеть; если у вас больше нейронов, вы просто добавляете одно измерение в матрицу коэффициентов, чтобы мультиплексировать входы во все узлы и суммируйте вклад каждого узла.
что вы можете написать в векторизованном формате как
A = [a0, a1, .., aN] , X = [x0, x1, ..., 1]
Y = A . XT
т. е., помещая коэффициенты в один массив и (входы + смещение) в другой, у вас есть желаемое решение в качестве точечного произведения двух векторов (вам нужно транспонировать X для правильной формы, я написал XT A "X транспонирован")
таким образом, в конце концов вы также можете увидеть свое смещение, поскольку это всего лишь еще один вход для представления части вывода, которая фактически не зависит от ваш вклад.
в частности, ответ, zfy по ответ, и ответ большие.
проще говоря, предубеждения позволяют все больше и больше вариаций Весов, которые будут изучены / сохранены... (к: иногда задается некоторый порог). Во всяком случае,
думать простым способом, если у вас есть y=w1 * x здесь y ваш выход и w1 вес представьте себе состояние, когда x=0 затем y=w1 * x равно 0, если вы хотите обновить свой вес, вы должны вычислить, сколько изменений на delw=target-y где target-ваш целевой выход, в этом случае 'delw' не изменится, поскольку y вычисляется как 0.Итак, предположим, если вы можете добавьте дополнительное значение, это поможет y=w1 * x+w0 * 1, где смещение=1 и вес можно отрегулировать, чтобы получить правильное смещение.Рассмотрим пример ниже.
в терминах наклона линии-перехват является определенной формой линейных уравнений.
y=mx+b
Регистрация изображения
{kind=link}
здесь b (0,2)
Если вы хотите увеличить его до (0,3), как вы это сделаете, изменив значение b, которое будет вашим смещением
для всех книг ML, которые я изучал, W всегда определяется как индекс связности между двумя нейронами , что означает, что чем выше связь между двумя нейронами , тем сильнее сигналы будут передаваться от стреляющего нейрона к целевому нейрону или Y= w * X в результате для поддержания биологического характера нейронов, нам нужно сохранить 1 >=W >= -1, но в реальной регрессии W закончится с |W / >=1, Что противоречит тому, как работают нейроны, в результате I предложим W= cos (тета) , в то время как 1 > = / cos ( тета)|, и Y= a * X = W * X + b в то время как a = b + W = b + cos( тета) , b-целое число
кроме упомянутых ответов..Я хотел бы добавить еще несколько моментов.
Bias действует как наш ЯКОРЬ. Это способ для нас, чтобы иметь какой-то базовый уровень, где мы не пойдем ниже. В терминах графика подумайте о том, как y=mx+b это похоже на y-перехват этой функции.
output = input умножает значение веса и добавляет уклон стоимостью и затем применить функцию активации.
смещение решает, какой угол вы хотите, чтобы ваш вес вращался.
в 2-мерной диаграмме вес и смещение помогают нам найти границу решения выходов. Скажем, нам нужно построить и функционировать, входная(p)-выходная (t) пара должна быть
{p=[0,0], t=0}, {p=[1,0], t=0}, {p=[0,1], t=0}, {p=[1,1], t=1}

теперь нам нужно найти границу решения, граница идеи должна быть:

посмотреть? W перпендикулярно нашей границе. Таким образом, мы говорим, что W решил направление границы.
однако трудно найти правильный W в первый раз. В основном мы выбираем исходное значение W случайным образом. Таким образом, первая граница может быть такой:

теперь граница пареллер к оси Y.
мы хотим повернуть границу, как?
изменение У.
Итак, мы используем функцию правила обучения: W ' =W+P:

W '=W+P эквивалентно W ' =W+bP, в то время как b=1.
поэтому, изменяя значение b (смещение), вы можете решить угол между W' и W. Это "правило обучения ANN".
вы можете ознакомиться Дизайн Нейронной Сети Мартин т. Хаган / Говард Б. Демут / Марк Х. бил, Глава 4 "правило обучения перцептрона"
В общем, в машинном обучении у нас есть эта базовая формула Смещение-Дисперсия Компромисс Поскольку в NN у нас есть проблема подгонки (проблема обобщения модели, где небольшие изменения данных приводят к большим изменениям в результате модели), и из-за этого у нас большая дисперсия, введение небольшого смещения может помочь. Учитывая формулу выше Смещение-Дисперсия Компромисс, где смещение в квадрате, следовательно, введение небольшого смещения может привести к снижение дисперсии много. Итак, представьте предвзятость, когда у вас есть большая дисперсия и чрезмерная опасность.