Sklearn.KMeans (): получить метки центроида класса и ссылку на набор данных
Sci-Kit изучите уменьшение размерности Kmeans и PCA
у меня есть набор данных, 2M строк по 7 столбцам, с различными измерениями потребления энергии дома с датой для каждого измерение.
- дата,
- Global_active_power,
- Global_reactive_power,
- напряжение
- Global_intensity,
- Sub_metering_1,
- Sub_metering_2,
- Sub_metering_3
я помещаю свой набор данных в фрейм данных pandas, выбирая все столбцы, кроме столбца даты, а затем выполняю разделение перекрестной проверки.
import pandas as pd
from sklearn.cross_validation import train_test_split
data = pd.read_csv('household_power_consumption.txt', delimiter=';')
power_consumption = data.iloc[0:, 2:9].dropna()
pc_toarray = power_consumption.values
hpc_fit, hpc_fit1 = train_test_split(pc_toarray, train_size=.01)
power_consumption.head()

Я использую K-средства классификация с последующим уменьшением размерности PCA для отображения.
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
hpc = PCA(n_components=2).fit_transform(hpc_fit)
k_means = KMeans()
k_means.fit(hpc)
x_min, x_max = hpc[:, 0].min() - 5, hpc[:, 0].max() - 1
y_min, y_max = hpc[:, 1].min(), hpc[:, 1].max() + 5
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02), np.arange(y_min, y_max, .02))
Z = k_means.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(1)
plt.clf()
plt.imshow(Z, interpolation='nearest',
extent=(xx.min(), xx.max(), yy.min(), yy.max()),
cmap=plt.cm.Paired,
aspect='auto', origin='lower')
plt.plot(hpc[:, 0], hpc[:, 1], 'k.', markersize=4)
centroids = k_means.cluster_centers_
inert = k_means.inertia_
plt.scatter(centroids[:, 0], centroids[:, 1],
marker='x', s=169, linewidths=3,
color='w', zorder=8)
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()

теперь я хотел бы узнать, какие строки попали под данный класс, а затем какие даты попали под данный класс.
- есть ли способ связать точки На графике с индексом в моем набор данных, после PCA?
- какой-то метод, о котором я не знаю?
- или мой подход принципиально ошибочен?
- любой рекомендации?
Я довольно новичок в этом поле и пытаюсь прочитать много кода, это компиляция нескольких примеров, которые я видел документально .
моя цель-классифицировать данные, а затем получить даты, которые попадают под класс.
Спасибо
1 ответов
KMeans().предсказать(х) ..документы здесь
предсказать ближайший кластер каждого образца в X принадлежит.
в литературе векторного квантования cluster_centers_ называется кодовой книгой, и каждое значение, возвращаемое predict, является индексом ближайшего кода в кодовой книге.
Parameters: (New data to predict)
X : {array-like, sparse matrix}, shape = [n_samples, n_features]
Returns: (Index of the cluster each sample belongs to)
labels : array, shape [n_samples,]
проблема I с представленным вами кодом заключается в использовании
train_test_split()
который возвращает два массива случайных строк в вашем набор данных, эффективно разрушающий порядок набора данных, что затрудняет корреляцию меток, возвращаемых из классификации KMeans, с последовательными датами в наборе данных.
вот пример:
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
#read data into pandas dataframe
df = pd.read_csv('household_power_consumption.txt', delimiter=';')

#convert merge date and time colums and convert to datetime objects
df['Datetime'] = pd.to_datetime(df['Date'] + ' ' + df['Time'])
df.set_index(pd.DatetimeIndex(df['Datetime'],inplace=True))
df.drop(['Date','Time'], axis=1, inplace=True)
#put last column first
cols = df.columns.tolist()
cols = cols[-1:] + cols[:-1]
df = df[cols]
df = df.dropna()

#convert dataframe to data array and removes date column not to be processed,
sliced = df.iloc[0:, 1:8].dropna()
hpc = sliced.values
k_means = KMeans()
k_means.fit(hpc)
# array of indexes corresponding to classes around centroids, in the order of your dataset
classified_data = k_means.labels_
#copy dataframe (may be memory intensive but just for illustration)
df_processed = df.copy()
df_processed['Cluster Class'] = pd.Series(classified_data, index=df_processed.index)
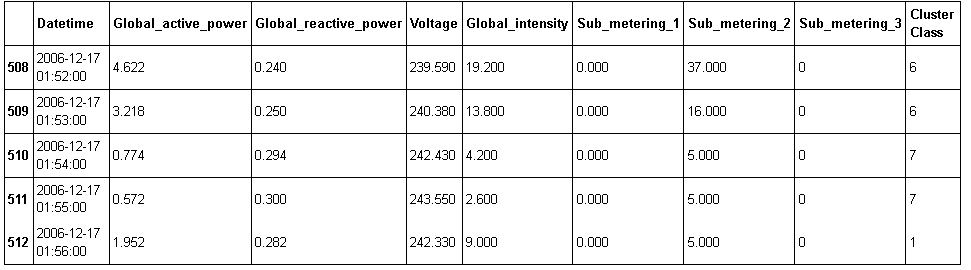
- теперь вы можете увидеть, что ваш результат соответствует вашему набору данных с правой стороны.
- теперь, когда это засекречено, это до вы, чтобы получить смысл.
- это просто хороший общий пример, как его можно использовать, от начала до конца.
- отображение результата, посмотрите на PCA или создание других графиков в зависимости от класса.