Скорость и эффективность доступа к IndexedDB
Я разрабатываю RPG в Dart, и я собираюсь использовать IndexedDB для сохранения данных.
У меня будет две базы данных: одна для доступа только для чтения и одна для доступа для чтения и записи, где будут храниться игры сохранения. Мне просто интересно, должен ли я читать необходимые данные непосредственно из базы данных или кэшировать их в картах. Потенциально у меня может быть несколько сотен записей, которые нужно вытащить из базы данных только для чтения (враги, игровые карты и т. д.) и я хотя бы вытаскиваю все из база данных может быть менее эффективной, чем использование карт Dart.
О, и каждая база данных будет храниться на карте. Хранилища объектов будут вложенными картами внутри этой карты.
должен ли я читать непосредственно из базы данных, или я должен поместить все в карту и читать оттуда?
редактировать: забыл упомянуть, что база данных только для чтения будет инициализирована данными из файла JSON, расположенного на компьютере пользователя, а не через AJAX.
2 ответов
Я уверен, что сотни записей не представят вам никаких проблем в IndexedDB. IDB был разработан с учетом такого масштаба, и его асинхронные API-интерфейсы-в то время как досадно для новичков-убедитесь, что ваше приложение остается отзывчивым по дизайну.
Я работаю над демонстрацией, призванной подтолкнуть IDB дальше, чем он должен идти, и иметь для вас легкодоступную статистику. Они попадают в один индекс в одном хранилище базы данных.
получает пылают быстро в Технологии IndexedDB. Вопрос с ИБР на шкале обычно пишет.
тысяча успешных обратных вызовов, один полный обратный вызов, были субсекундными:
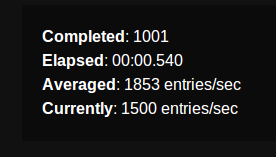
десять тысяч обратных вызовов успеха, один полный обратный вызов, был около 5 секунд:
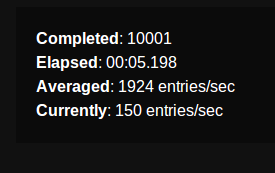
более пятидесяти тысяч успешных обратных вызовов, выпущенных менее чем за минуту:
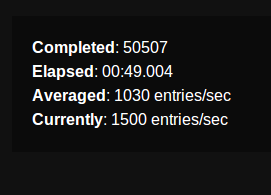
записи намного медленнее-сначала бурные, но затем медленные через несколько минут и собака замедляется после часа. Это с любой схемой, но у вас, вероятно, будет несколько индексов по местоположению (по крайней мере, широта и долгота), поэтому ваши записи будут особенно медленными (больше индексов, больше работы для основных вставок и обновлений).
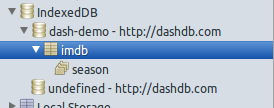
макет для статистики выше (так же важно, как сами статистики, убедитесь, что разработать схему в соответствии с тем, как вам нужно получить к нему доступ):


Я бы пошел с прямым доступом к базе данных, а затем отслеживать производительность, а затем оптимизировать, где можно ожидать заметных выгод. Преждевременная оптимизация редко бывает хорошей идеей.