Сохранить модель ML для будущего использования
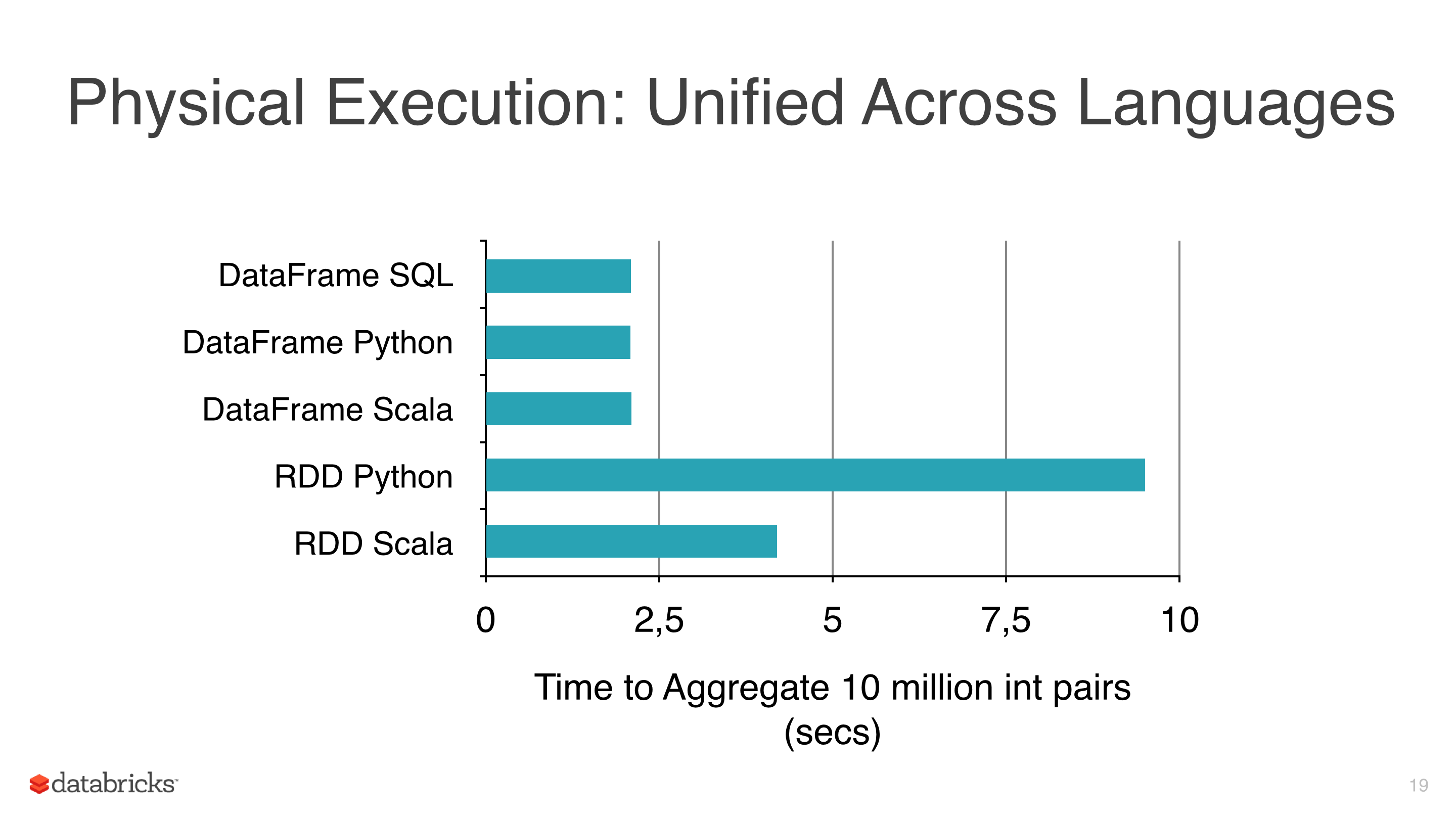
я применял некоторые алгоритмы машинного обучения, такие как линейная регрессия, логистическая регрессия и наивный Байес к некоторым данным, но я пытался избежать использования RDDs и начать использовать фреймы данных, потому что RDDs медленнее чем таблицы данных под pyspark (см. рис. 1).
другая причина, по которой я использую DataFrames, заключается в том, что библиотека ml имеет класс, очень полезный для настройки моделей, который CrossValidator этот класс возвращает модель после ее установки, очевидно, этот метод должен протестировать несколько сценариев, и после этого возвращает встроенные модели (с лучшими комбинациями параметров).
кластер, который я использую, не так велик, и данные довольно большие, а некоторые подгонки занимают часы, поэтому я хочу сохранить эти модели для их повторного использования позже, но я не понял, как, есть ли что-то, что я игнорирую?
Примечания:
- классы модели mllib имеют метод сохранения (т. е. NaiveBayes), но mllib не имеет CrossValidator и использует RDDs, поэтому я избегаю его преднамеренно.
- текущая версия-spark 1.5.1.
2 ответов
Искра 2.0.0+
на первый взгляд все Transformers и Estimators реализовать MLWritable. Если вы используете Spark
Искра >= 1.6
так как Spark 1.6 можно сохранить ваши модели с помощью save метод. Потому что почти каждый model осуществляет MLWritable интерфейс. Например, LinearRegressionModel и поэтому с его помощью можно сохранить вашу модель на желаемый путь.
Искра
я считаю, что вы делаете неправильные предположения здесь.
некоторые операции на DataFrames смогите быть оптимизировано и оно переводит к улучшенному представлению сравненному к простому RDDs. DataFrames обеспечить эффективное кэширование и SQLISH API, возможно, легче понять, чем RDD API.
трубопроводы ML весьма полезны и инструменты как кросс-валидатор или различные оценщики просто необходимы в любом машинном конвейере, и даже если ни одно из вышеперечисленных особенно трудно реализовать поверх низкоуровневого API MLlib, гораздо лучше иметь готовое к использованию, универсальное и относительно хорошо протестированное решение.
пока все хорошо, но есть несколько проблем:
- насколько я могу сказать, простой операции
DataFramesкакselectилиwithColumnпокажите подобное представление к своим эквивалентам RDD какmap, - в некоторых случаях увеличение количества столбцов в типичном конвейере может фактически ухудшить производительность по сравнению с хорошо настроенными низкоуровневыми преобразованиями. Конечно, вы можете добавить Drop-column-transformers по пути, чтобы исправить это,
- многие алгоритмы ML, в том числе
ml.classification.NaiveBayesпросто фантики вокругmllibAPI, - алгоритмы PySpark ML/MLlib делегируют фактическую обработку в Scala коллеги,
- последний, но не менее важный RDD все еще там, даже если хорошо скрыт за API DataFrame
я считаю, что в конце концов то, что вы получаете с помощью ML over MLLib, довольно элегантный API высокого уровня. Одна вещь, которую вы можете сделать, это объединить оба для создания пользовательского многоступенчатого конвейера:
- используйте ML для загрузки, очистки и преобразования данных,
- извлечение необходимых данных (см., например,extractLabeledPoints метод) и перейти к ,
- добавить пользовательскую перекрестную проверку / оценку
- сохранить
MLLibмодель с использованием метода по вашему выбору (Spark model или язык pmml)
это не оптимальное решение, но это лучшее, что я могу придумать с учетом текущего API.
похоже, что функциональность API для сохранения модели не реализована на сегодняшний день (см. Spark issue tracker SPARK-6725).
альтернатива была размещена (как сохранить модели от трубопровода ML к S3 или HDFS?), который включает в себя просто сериализацию модели, но является подходом Java. Я ожидаю, что в PySpark вы можете сделать что-то подобное, то есть рассолить модель для записи на диск.