Solr: точный запрос фразы с EdgeNGramFilterFactory
в Solr (3.3) можно ли сделать поле по буквам доступным для поиска через EdgeNGramFilterFactory, а также чувствительны к поисковым фраза?
например, я ищу поле, которое, если содержит "contrat informatique", будет найдено, если пользователь вводит:
- контраст
- информатике
- contr
- informa
- "Contra informatique"
- "договор инфо"
В Настоящее Время Я сделал что-то вроде этого:
<fieldtype name="terms" class="solr.TextField">
<analyzer type="index">
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="2" maxGramSize="15" side="front"/>
</analyzer>
<analyzer type="query">
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
</analyzer>
</fieldtype>
...но это не на поисковые фразы.
когда я смотрю в анализаторе схем в Solr admin, я нахожу, что" Contra informatique " сгенерировал следующие токены:
[...] contr contra contrat in inf info infor inform [...]
таким образом, запрос работает с "Contra in" (последовательные токены), но не "Contra inf" (потому что эти два токена разделены).
Я уверен, что любой тип stemming может работать с запросами фраз, но я не могу найти правильный токенизатор фильтр для использования перед EdgeNGramFilterFactory.
4 ответов
точный поиск фразы не работает из-за параметра slop запроса = 0 по умолчанию. Поиск фразы "Hello World" - это поиск терминов с последовательными позициями. Я хотел бы, чтобы EdgeNGramFilter имел параметр для управления выходным позиционированием, это выглядит как старый вопрос.
установив параметр qs на очень высокое значение (больше максимального расстояния между ngrams), вы можете получить фразы обратно. Это частично решает проблему, разрешающую фразы, но не точные, перестановки будут найдены. Так что поиск "contrat informatique" будет соответствовать тексту "...договор отказались. Информатика..."
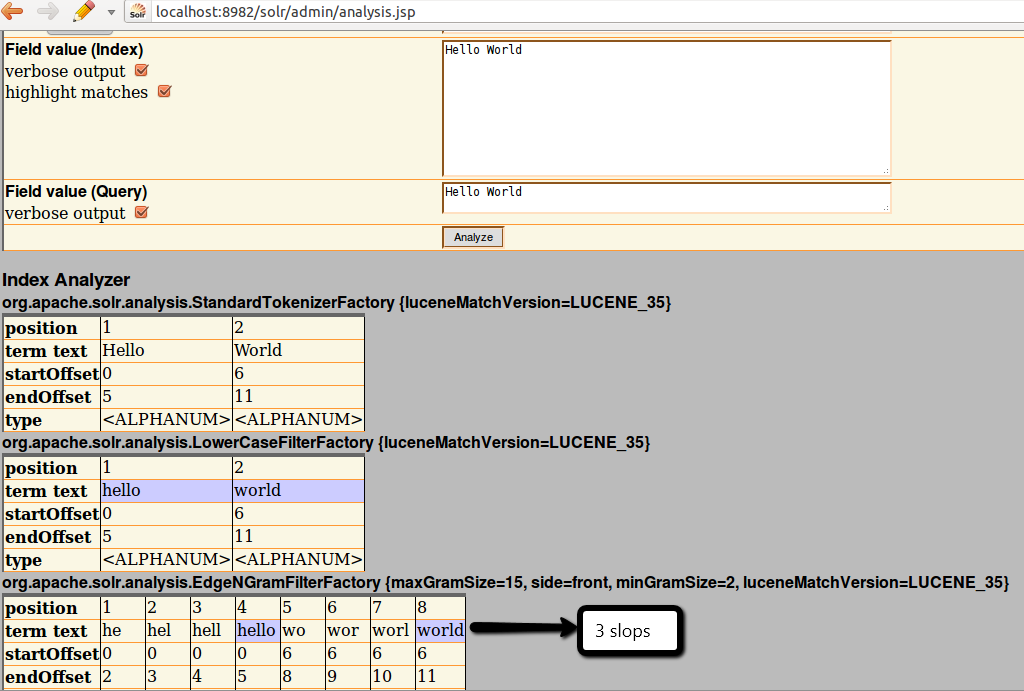
в поддержку точно запрос-фраза, которую я в конечном итоге использовать отдельные поля для ngrams.
необходимые действия:
определите отдельные типы полей для индексирования регулярных значений и граммов:
<fieldType name="text" class="solr.TextField" omitNorms="false">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="ngrams" class="solr.TextField" omitNorms="false">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="2" maxGramSize="15" side="front"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
рассказать Solr, чтобы копировать поля когда индексирование:
вы можете определить отдельное отражение ngrams для каждого поля:
<field name="contact_ngrams" type="ngrams" indexed="true" stored="false"/>
<field name="product_ngrams" type="ngrams" indexed="true" stored="false"/>
<copyField source="contact_text" dest="contact_ngrams"/>
<copyField source="product_text" dest="product_ngrams"/>
или вы можете поместить все ngrams в одно поле:
<field name="heap_ngrams" type="ngrams" indexed="true" stored="false"/>
<copyField source="*_text" dest="heap_ngrams"/>
обратите внимание, что в этом случае вы не сможете отделить ускорители.
и последнее, что нужно указать поля ngrams и ускорители в запросе. Один из способов-настроить приложение. Другой способ-указать" добавляет " параметры в solrconfig.в XML
<lst name="appends">
<str name="qf">heap_ngrams</str>
</lst>
как увы мне не удалось использовать PositionFilter правильно, как предложил Jayendra Patil (PositionFilter делает любой запрос a или логический запрос), я использовал другой подход.
еще с EdgeNGramFilter, Я добавил тот факт, что каждое ключевое слово, введенное пользователем, является обязательным, и отключил все фразы.
поэтому, если пользователь попросит "cont info", оно превращается в +cont +info. Это немного более допустимо, что истинная фраза будет, но ей удалось сделать то, что я хочу (и не возвращается результаты только с одним термином из двух).
единственное мошенничество против этого обходного пути заключается в том, что термины могут быть перестанованы в результатах (поэтому также будет найден документ с "informatique Contra"), но это не так уж важно.
вот о чем я думала -
Для того, чтобы ngrams была фраза соответствовала положению токенов, генерируемых для каждого слова, должно быть одинаковым.
Я проверил фильтр edge grams, и он увеличивает токены, и не нашел никакого параметра, чтобы предотвратить это.
Существует доступный фильтр позиции, и это поддерживает позицию токенов в том же токене, что и в начале.
Поэтому, если используется следующая конфигурация, все маркеры находятся в одной позиции и совпадают запрос фразы (те же позиции маркеров сопоставляются с фразами)
Я проверил его через инструмент anaylsis, и запросы совпали.
поэтому вы можете попробовать подсказку : -
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory" />
<charFilter class="solr.MappingCharFilterFactory"
mapping="mapping-ISOLatin1Accent.txt" />
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1"
generateNumberParts="1" catenateWords="1" catenateNumbers="1"
catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.EdgeNGramFilterFactory" minGramSize="2"
maxGramSize="15" side="front"/>
<filter class="solr.PositionFilterFactory" />
</analyzer>
я исправил EdgeNGramFilter, поэтому позиции в токене больше не увеличиваются:
public class CustomEdgeNGramTokenFilterFactory extends TokenFilterFactory {
private int maxGramSize = 0;
private int minGramSize = 0;
@Override
public void init(Map<String, String> args) {
super.init(args);
String maxArg = args.get("maxGramSize");
maxGramSize = (maxArg != null ? Integer.parseInt(maxArg)
: EdgeNGramTokenFilter.DEFAULT_MAX_GRAM_SIZE);
String minArg = args.get("minGramSize");
minGramSize = (minArg != null ? Integer.parseInt(minArg)
: EdgeNGramTokenFilter.DEFAULT_MIN_GRAM_SIZE);
}
@Override
public CustomEdgeNGramTokenFilter create(TokenStream input) {
return new CustomEdgeNGramTokenFilter(input, minGramSize, maxGramSize);
}
}
public class CustomEdgeNGramTokenFilter extends TokenFilter {
private final int minGram;
private final int maxGram;
private char[] curTermBuffer;
private int curTermLength;
private int curGramSize;
private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);
private final OffsetAttribute offsetAtt = addAttribute(OffsetAttribute.class);
private final PositionIncrementAttribute positionIncrementAttribute = addAttribute(PositionIncrementAttribute.class);
/**
* Creates EdgeNGramTokenFilter that can generate n-grams in the sizes of the given range
*
* @param input {@link org.apache.lucene.analysis.TokenStream} holding the input to be tokenized
* @param minGram the smallest n-gram to generate
* @param maxGram the largest n-gram to generate
*/
public CustomEdgeNGramTokenFilter(TokenStream input, int minGram, int maxGram) {
super(input);
if (minGram < 1) {
throw new IllegalArgumentException("minGram must be greater than zero");
}
if (minGram > maxGram) {
throw new IllegalArgumentException("minGram must not be greater than maxGram");
}
this.minGram = minGram;
this.maxGram = maxGram;
}
@Override
public final boolean incrementToken() throws IOException {
while (true) {
int positionIncrement = 0;
if (curTermBuffer == null) {
if (!input.incrementToken()) {
return false;
} else {
positionIncrement = positionIncrementAttribute.getPositionIncrement();
curTermBuffer = termAtt.buffer().clone();
curTermLength = termAtt.length();
curGramSize = minGram;
}
}
if (curGramSize <= maxGram) {
if (!(curGramSize > curTermLength // if the remaining input is too short, we can't generate any n-grams
|| curGramSize > maxGram)) { // if we have hit the end of our n-gram size range, quit
// grab gramSize chars from front
int start = 0;
int end = start + curGramSize;
offsetAtt.setOffset(start, end);
positionIncrementAttribute.setPositionIncrement(positionIncrement);
termAtt.copyBuffer(curTermBuffer, start, curGramSize);
curGramSize++;
return true;
}
}
curTermBuffer = null;
}
}
@Override
public void reset() throws IOException {
super.reset();
curTermBuffer = null;
}
}