Создание и сжатие TIFF-графика: R против GIMP против IrfanView против Photoshop размеры файлов
я сгенерировал некоторые графики качества публикации с высоким разрешением, например
library(plot3D)
Volcano<-volcano
zf=10 #zoom factor
tiff("Volcano.tif", width=1800*zf, height=900*zf, res=175*zf, compression="lzw")
image2D(z = Volcano, clab = "height, m",colkey = list(dist = -0.20, shift = 0.15,side = 3, length = 0.5, width = 0.5,cex.clab = 1.2, col.clab = "white", line.clab = 2,col.axis = "white", col.ticks = "white", cex.axis = 0.8))
dev.off()
файл 22 МБ.
теперь я открываю файл с помощью GIMP и не делая ничего другого я экспортирую его как " вулкан gimp.tif "(не меняйте разрешение или не делайте ничего другого). GIMP генерирует файл ("Volcano gimp.tif"), то есть 1,9 Мб.
imagemagick сообщает подобную статистику изображения:
$ identify Volcano.tif
Volcano.tif TIFF 18000x9000 18000x9000+0+0 8-bit DirectClass 22.37MB 0.000u 0:00.000
$ identify "Volcano gimp.tif"
Volcano gimp.tif TIFF 18000x9000 18000x9000+0+0 8-bit DirectClass 1.89MB 0.000u 0:00.000
даже с помощью identify -verbose 2 файла отображаются в быть схожими.
в чем разница между этими файлами? Почему у них такие разные размеры файлов?
обновление: хорошо, все становится безумнее. Я сделал то же самое с IrfanView и я получаю разные размеры файлов. Начальный файл -Volcano.tif создается от R С compression="lzw". Проверьте, как Volcano irfan.tif и Volcano gimp.tif отличаются по размеру, но все остальные характеристики такие же. Объем памяти, DPI, цвета, разрешение идентичны. Размер диска отличается.
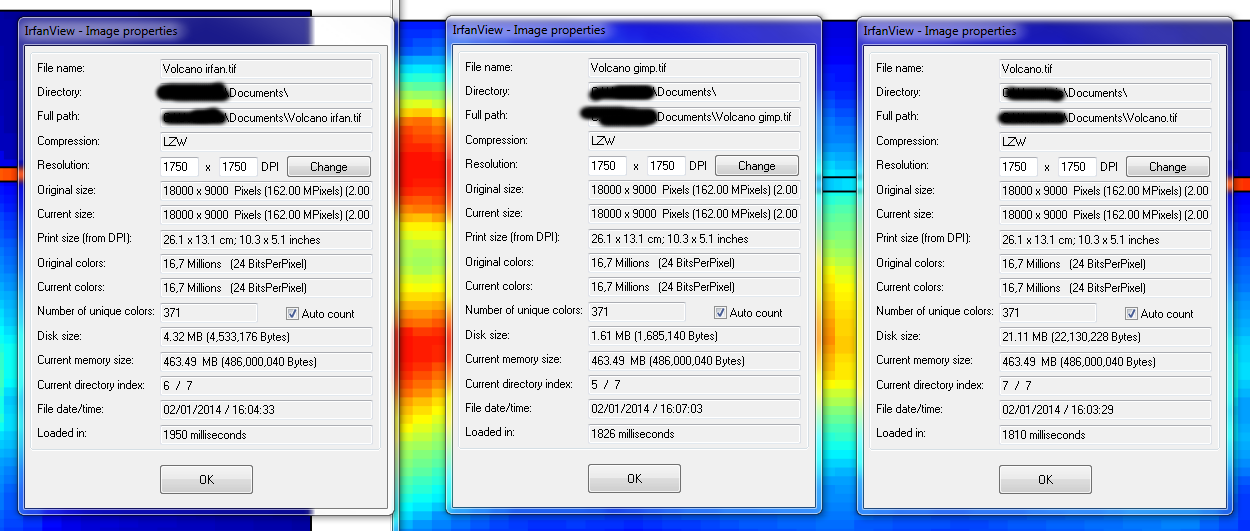
обновление 2: Adobe Photoshop сохраняет файл до 2,6 МБ
WinRar сообщает, что исходный R сгенерированный TIFF сильно сжимается (от 22MB ->3.6 MB)
обновление 3: эта проблема может быть похожа на монтаж / присоединиться 2 TIFF изображения в 2 col x 1 ряд плитки без потери качества
обновление 4: R сгенерированный TIFF файл можно найти здесь http://ge.tt/7ZvRd4C1/v/0?c
1 ответов
по-видимому, компрессор TIFF LZW, используемый R, не использует важный параметр (предиктор TIFF), который приводит к чрезвычайно большому файлу. Сжатие данных лучше всего работает, когда оно может распознавать симметрии/избыточности в данных. В этом случае данные изображения состоят из 24-битных (3-байтовых) пикселей, содержащих красные, зеленые и синие 8-битные значения. Стандартное сжатие LZW просматривает поток байтов для повторяющихся шаблонов. Если он смотрит на цветное изображение просто как поток байтов, он будет видеть повторяющиеся шаблоны 3-байтов вместо повторяющихся шаблонов постоянного цвета. Включение предиктора TIFF для данных приводит к тому, что разностный фильтр сохраняет дельту каждого пикселя с его соседом. Если соседние пиксели имеют тот же цвет, он будет хранить 0. Длинная строка 0 сжимается намного лучше, чем повторяющиеся шаблоны ненулей, которые имеют длину не менее 3 байт.
вот пример того, как это работает на 6-пиксельной линии. При кодировании запускается предиктор с правого края и работает слева для каждой строки сканирования:
Original data:
2A 50 40 2A 50 40 2A 50 40 2A 50 40 2A 50 40 2A 50 40 (6 pixels of the same color)
After horizontal differencing (TIFF predictor):
2A 50 40 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
The data is much more compressible after the predictor since long runs of the same value (0x00) are easier for LZW to compress.
вывод: это должно быть подано как ошибка против владельца кода сжатия R, так как использование LZW на полноцветных изображениях без предиктора дает плохие результаты. В то же время, обходной путь нужен, чтобы сжать его более эффективно.