Справедливо ли сравнивать блоки SSE/AVX с ядрами GPU?
У меня есть презентация для людей, которые (почти) не знают, как работает GPU. Я думаю, что говорить, что GPU имеет тысячу ядер, где CPU имеет только от четырех до восьми из них, не имеет смысла. Но я хочу дать моей аудитории элемент сравнения.
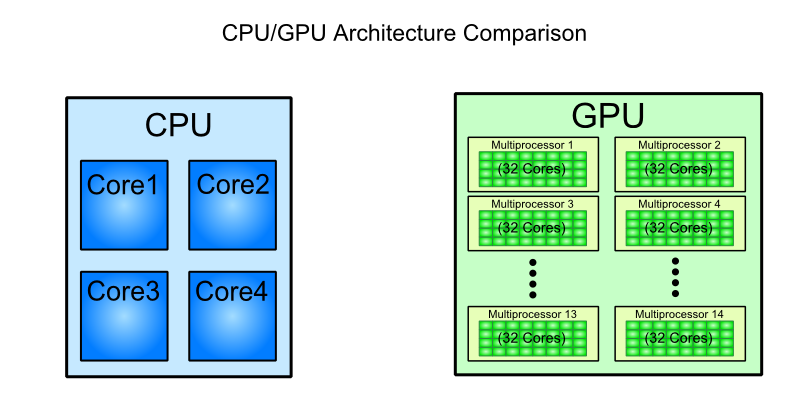
после нескольких месяцев работы с архитектурой NVidia Kepler и GCN AMD, у меня возникает соблазн сравнить GPU "core" до процессор SIMD ALU (Я не знаю, есть ли у них название для этого в Intel). разве это справедливо ? в конце концов, при взгляде на уровень сборки эти модели программирования имеют много общего (по крайней мере, с GCN, взгляните на p2-6 на руководство ISA).
в этой статье утверждает, что процессор Haswell может выполнять 32 операции с одной точностью за цикл, но я полагаю, что для достижения этой скорости происходит конвейеризация или другие вещи. на языке NVidia, сколько Cuda-ядра тут этот процессор есть ? Я бы сказал, 8 на CPU-core для 32-битных операций, но это всего лишь предположение, основанное на ширине SIMD.
конечно, есть много других вещей, которые следует учитывать при сравнении оборудования CPU и GPU, но это не то, что я пытаюсь сделать. Я просто должен объяснить, как эта штука работает.
PS: все указатели на CPU аппаратная документация или презентации CPU/GPU очень ценятся !
EDIT: Спасибо за ваши ответы, к сожалению мне пришлось выбирать только один из них. Я отметил Игорь потому что он больше всего прилипает к моему первоначальному вопросу и дал мне достаточно информации, чтобы оправдать, почему это сравнение не должно быть принято слишком далеко, но CaptainObvious предоставил очень хорошие статьи.
4 ответов
очень грубо говоря, не совсем неразумно говорить, что ядро Haswell имеет около 16 ядер CUDA, но вы определенно не хотите заходить слишком далеко в этом сравнении. Вы можете быть осторожны, делая это заявление непосредственно в презентации, но я нашел полезным думать о ядре CUDA как о чем-то связанном со скалярным блоком FP.
Это может помочь, если я объясню, почему Haswell может выполнять 32 операции с одной точностью в ездить на велосипеде.
8 операций с одной точностью выполняются в каждой инструкции AVX/AVX2. При написании кода, который будет работать на процессоре Haswell, вы можете использовать инструкции AVX и AVX2, которые работают с 256-битными векторами. Эти 256-разрядные векторы могут представлять 8 одноточных чисел FP, 8 целых чисел (32-разрядных) или 4 двухточных числа FP.
2 инструкции AVX/AVX2 могут выполняться в каждом ядре за цикл, хотя есть некоторые ограничения, на которые инструкции можно спарить вверх.
сплавленная умножьте добавьте (FMA) инструкция технически выполняет 2 деятельности одиночн-точности. Инструкции FMA выполняют "слитые" операции, такие как A = A * B + C, поэтому, возможно, есть две операции на скалярный операнд: умножение и сложение.
эта статья объясняет вышеуказанные пункты более подробно:http://www.realworldtech.com/haswell-cpu/4/
В общем учет, ядро Haswell может выполнять 8 * 2 * 2 деятельность одиночн-точности в цикл. Поскольку ядра CUDA также поддерживают операции FMA, вы не можете подсчитать этот коэффициент 2 при сравнении ядер CUDA с ядрами Haswell.
сердечник Kepler CUDA имеет один блок с плавающей запятой одиночн-точности, поэтому он может выполнить одну деятельность с плавающей запятой в цикл: http://www.nvidia.com/content/PDF/kepler/NVIDIA-Kepler-GK110-Architecture-Whitepaper.pdf, http://www.realworldtech.com/kepler-brief/
Если бы я собирал слайды на этом, у меня был бы один раздел, объясняющий, сколько операций FP Haswell может сделать за цикл: три точки выше, плюс у вас есть несколько ядер и, возможно, несколько процессоров. И у меня был бы другой раздел, объясняющий, сколько операций FP может выполнять GPU Kepler за цикл: 192 за SMX, и у вас есть несколько единиц SMX на GPU.
PS.: Я могу констатировать очевидное, но чтобы избежать путаницы: архитектура Haswell также включает интегрированный GPU, который имеет совершенно другую архитектуру от процессора Haswell.
Я бы очень осторожно сделал такое сравнение. В конце концов, даже в мире GPU термин "ядро" в зависимости от контекста имеет действительно разные возможности: новый AMD GCN сильно отличается от старого VLIW4, который сам по себе сильно отличается от ядра CUDA.
Кроме того, вы принесете больше недоумения, чем понимания вашей аудитории, если вы сделаете только одно небольшое сравнение с CPU, и все. Если бы я был тобой, я бы все равно пошел на более подробный (все еще может быть быстрое сравнение.
например, кто-то использовал CPU и с небольшим знанием GPU, может задаться вопросом, почему GPU может иметь так много регистров, хотя это так дорого (в мире CPU). Объяснение этому вопросу дается в конце этого в должности а также некоторые другие сравнения GPU vs CPU.
другой статьи дает хорошее сравнение между этими двумя видами процессоров, объясняя, как работают графические процессоры, но и как они развивались и показаны различия с процессорами. В нем рассматриваются такие темы, как поток данных, иерархия памяти, а также для каких приложений полезен GPU. Ведь мощность, которую может развить GPU, доступна (эффективно) только для некоторых типов проблем.
И лично, если бы мне пришлось сделать презентацию о GPU и была возможность сделать только одна ссылка на CPU это было бы так: представляя проблемы, которые GPU может эффективно решить против тех, которые процессор может обрабатывать лучше.
В качестве бонуса, даже если это не связано непосредственно с вашей презентацией, вот статьи это ставит GPGPU в перспективе, показывая, что некоторые ускорения, заявленные некоторыми людьми, переоценены (это связано с моей последней точкой btw :))
Я полностью согласен с CaptainObvious, особенно представляя проблемы, которые GPU может решить эффективно против тех, что процессор может обрабатывать лучше было бы хорошей идеей.
один из способов, которым мне нравится сравнивать процессоры и графические процессоры, - это количество операций/сек, которые они могут выполнить. Но, конечно, не сравнивайте одно ядро процессора с многоядерным gpu.
ядро SandyBridge может выполнять 2 цикла AVX op/, то есть хруст 8 чисел двойной точности / цикл. Следовательно, компьютер при 16 ядрах Sandy-Bridge с тактовой частотой 2,6 ГГц имеет пиковую мощность 333 Gflops.
вычислительный модуль K20 GK110 имеет пик 1170 Gflops, то есть в 3,5 раза больше. На мой взгляд, это справедливое сравнение, и следует подчеркнуть, что пиковая производительность намного легче достичь на CPU (некоторые приложения достигают 80% -90% пика), чем на GPU (лучшие случаях я знаю менее 50% от пика).
поэтому, чтобы летом, я бы не пошел в детали архитектуры, а скорее указать некоторые сдвиговые числа с точки зрения того, что пик часто далеко от досягаемости на графических процессорах.
более справедливо сравнивать GPU с векторизованными блоками процессора, однако, если ваша аудитория имеет ноль идея о том, как работают графические процессоры, кажется справедливым предположить, что они имеют аналогичные знания векторизованных инструкций SSE.
для таких аудиторий, как эти, важно указать на различия высокого уровня, например, как блоки "ядер" на gpu совместно используют планировщик и файл регистрации.
Я бы сослался на обзор архитектуры GTC Kepler для a лучшее представление о том, как выглядит архитектура Кеплера. этой также достаточно понятное сравнение между ними, если вы хотите придерживаться идеи "ядра gpu".
{kind=link}