Сравнение двух списков в R
У меня есть два списка идентификаторов.
Я хотел бы сравнить два списка, в частности меня интересуют следующие цифры:
- сколько идентификаторов в списке A и B
- сколько идентификаторов в A, но не в B
- сколько идентификаторов в B, но не в A
Я также хотел бы нарисовать диаграмму Венна.
5 ответов
вот некоторые основы, чтобы попробовать:
> A = c("Dog", "Cat", "Mouse")
> B = c("Tiger","Lion","Cat")
> A %in% B
[1] FALSE TRUE FALSE
> intersect(A,B)
[1] "Cat"
> setdiff(A,B)
[1] "Dog" "Mouse"
> setdiff(B,A)
[1] "Tiger" "Lion"
аналогично, вы можете получить подсчеты просто как:
> length(intersect(A,B))
[1] 1
> length(setdiff(A,B))
[1] 2
> length(setdiff(B,A))
[1] 2
обычно я имею дело с большими наборами, поэтому я использую таблицу вместо диаграммы Венна:
xtab_set <- function(A,B){
both <- union(A,B)
inA <- both %in% A
inB <- both %in% B
return(table(inA,inB))
}
set.seed(1)
A <- sample(letters[1:20],10,replace=TRUE)
B <- sample(letters[1:20],10,replace=TRUE)
xtab_set(A,B)
# inB
# inA FALSE TRUE
# FALSE 0 5
# TRUE 6 3
еще один способ, с помощью %в% и булевы векторы общих элементов вместо пересечение и setdiff. Я так понимаю, вы действительно хотите сравнить два векторы, не два списки - a список - это класс R, который может содержать любой тип элемента, в то время как векторы всегда содержат элементы только одного типа, следовательно, легче сравнивать то, что действительно равно. Здесь элементы преобразуются в символ строки, поскольку это был самый негибкий тип элемента, который присутствовал.
first <- c(1:3, letters[1:6], "foo", "bar")
second <- c(2:4, letters[5:8], "bar", "asd")
both <- first[first %in% second] # in both, same as call: intersect(first, second)
onlyfirst <- first[!first %in% second] # only in 'first', same as: setdiff(first, second)
onlysecond <- second[!second %in% first] # only in 'second', same as: setdiff(second, first)
length(both)
length(onlyfirst)
length(onlysecond)
#> both
#[1] "2" "3" "e" "f" "bar"
#> onlyfirst
#[1] "1" "a" "b" "c" "d" "foo"
#> onlysecond
#[1] "4" "g" "h" "asd"
#> length(both)
#[1] 5
#> length(onlyfirst)
#[1] 6
#> length(onlysecond)
#[1] 4
# If you don't have the 'gplots' package, type: install.packages("gplots")
require("gplots")
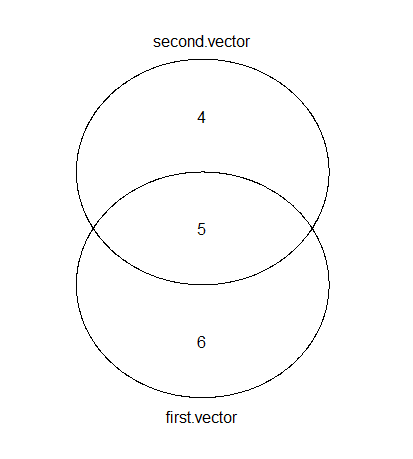
venn(list(first.vector = first, second.vector = second))
Как уже упоминалось, есть несколько вариантов построения диаграмм Venn в R. Вот результат с использованием gplots.
С sqldf: медленнее, но очень подходит для кадров данных со смешанными типами:
t1 <- as.data.frame(1:10)
t2 <- as.data.frame(5:15)
sqldf1 <- sqldf('SELECT * FROM t1 EXCEPT SELECT * FROM t2') # subset from t1 not in t2
sqldf2 <- sqldf('SELECT * FROM t2 EXCEPT SELECT * FROM t1') # subset from t2 not in t1
sqldf3 <- sqldf('SELECT * FROM t1 UNION SELECT * FROM t2') # UNION t1 and t2
sqldf1 X1_10
1
2
3
4
sqldf2 X5_15
11
12
13
14
15
sqldf3 X1_10
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
используя те же данные примера, что и один из ответов выше.
A = c("Dog", "Cat", "Mouse")
B = c("Tiger","Lion","Cat")
match(A,B)
[1] NA 3 NA
на match функция возвращает вектор с местоположением в B всех значений в A. Итак,cat второй элемент A, является третьим элементом в B. Других совпадений нет.
чтобы получить соответствующие значения в A и B, вы можете сделать:
m <- match(A,B)
A[!is.na(m)]
"Cat"
B[m[!is.na(m)]]
"Cat"
чтобы получить несоответствующие значения в A и B:
A[is.na(m)]
"Dog" "Mouse"
B[which(is.na(m))]
"Tiger" "Cat"
Далее, вы можете использовать length() чтобы получить общее количество совпадающих и несовпадающих значений.