Сверточная нейронная сеть (CNN) для аудио
Я следил за учебниками по DeepLearning.net чтобы узнать, как реализовать сверточную нейронную сеть, которая извлекает функции из изображений. Учебник хорошо объяснены, легко понять и следовать.
Я хочу расширить тот же CNN, чтобы извлечь мультимодальные функции из видео (изображения + аудио) одновременно.
Я понимаю, что видеовход-это не что иное, как последовательность изображений (интенсивность пикселей), отображаемых в течение определенного периода времени (например. 30 фпс) связанный с аудио. Однако я действительно не понимаю, что такое звук, как он работает или как он разбивается, чтобы быть поданным в сеть.
Я прочитал несколько статей по этому вопросу (извлечение/представление мультимодальных функций), но никто не объяснил, как звук вводится в сеть.
более того, из моих исследований я понимаю, что мультимодальное представление-это то, как наш мозг действительно работает, поскольку мы не намеренно отфильтровываем наши чувства для достижения понимание. Все это происходит одновременно без нашего ведома через (совместное представление). Простой пример: если мы слышим рев льва, мы мгновенно создаем мысленный образ льва, чувствуем опасность и наоборот. Множество нейронных паттернов запускаются в нашем мозгу, чтобы достичь всестороннего понимания того, как лев выглядит, звучит, чувствует, пахнет и т. д.
вышеупомянутая моя конечная цель, но на данный момент я ломаю свой задача ради простоты.
Я был бы очень признателен, если бы кто-нибудь мог пролить свет на то, как звук препарируется, а затем представлен в сверточной нейронной сети. Я также был бы признателен за ваши мысли в отношении мультимодальной синхронизации, совместных представлений и правильного способа обучения CNN мультимодальным данным.
EDIT: Я выяснил, что звук может быть представлен в виде спектрограмм. Это как общий формат для аудио и представлен в виде графика с двумя геометрическими размерами, где горизонтальная линия представляет время, а вертикальная представляет частоту.
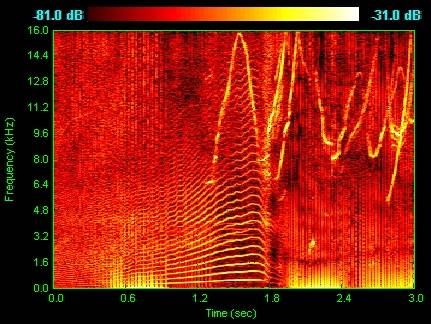
можно ли использовать ту же технику с изображениями на этих спектрограмм? Другими словами, могу ли я просто использовать эти спектрограммы в качестве входных изображений для моей сверточной нейронной сети?
2 ответов
мы использовали глубокие сверточные сети на спектрограммах для задачи идентификации разговорного языка. У нас была точность около 95% в наборе данных, предоставленном в этот конкурс TopCoder. Подробности здесь.
простые сверточные сети не учитывают временные характеристики, например в работе выход сверточной сети подавался в нейронную сеть с временной задержкой. Но наши эксперименты показывают, что даже без дополнительные элементы сверточных сетей могут хорошо работать, по крайней мере, на некоторых задачах, когда входы имеют одинаковые размеры.
существует множество методов извлечения векторов функций из аудиоданных для обучения классификаторов. Наиболее часто используемый называется MFCC (mel-frequency cepstrum), который вы можете рассматривать как "улучшенную" спектрограмму, сохраняя более релевантную информацию для различения классов. Другим широко используемым методом является PLP (Perceptual Linear Predictive), который также дает хорошие результаты. Это еще много менее известных.
в последнее время глубокие сети были использованы для извлекайте векторы объектов сами по себе, таким образом, более похожим образом, как мы делаем в распознавании изображений. Это активная область исследований. Не так давно мы также использовали экстракторы функций для обучения классификаторов изображений (SIFT, HOG и т. д.), но они были заменены методами глубокого обучения, которые имеют необработанные изображения в качестве входных данных и извлекают векторы функций сами по себе (действительно, это то, что глубокое обучение на самом деле).
также очень важно заметить, что звуковые данные являются последовательными. После обучение классификатора вам нужно обучить последовательную модель как HMM или CRF, которая выбирает наиболее вероятные последовательности речевых единиц, используя в качестве входных данных вероятности, заданные вашим классификатором.
хорошей отправной точкой для изучения распознавания речи является Юрский и Мартинс:обработка речи и языка. Он очень хорошо объясняет все эти понятия.
[редактировать: добавление потенциально полезной информации]
есть много речи наборы инструментов распознавания с модулями для извлечения векторов функций MFCC из аудиофайлов, но использование than для этой цели не всегда просто. В настоящее время я использую CMU Sphinx4. Он имеет класс FeatureFileDumper, который может использоваться автономно для генерации векторов MFCC из аудиофайлов.