Tesseract OCR не распознает символ разделения" ÷"
Я использую Tesseract в iOS 8 для приложения на основе OCR, но он неправильно преобразует символ деления " ÷ "на изображении в знак плюс"+".
например, это изображение
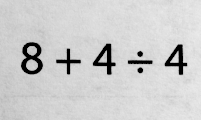
всегда преобразуется в текстовую строку "8+4+4". Должно быть "8+4÷4".
Я пробовал использовать разные обученные файлы языка данных "eng+equ", "ita", добавляя " ÷ " в белый список, устанавливая переменную ocr_engine в куб, Преобразуя изображение в оттенки серого или черный & белый, увеличивающий изображение в 2 и 4 раза.
все, что я пробовал, всегда возвращает знак плюс " + "вместо символа деления"÷".
Я попытался использовать только обученный файл данных "equ", и это правильно возвращает символ деления, но все остальные символы являются мусором.
Я изучал это (Google, Stackoverflow) в течение нескольких дней и не могу понять это.
Как заставить Тессеракт включить и распознать разделение символ"÷"?
обновление:
лучшее, что я смог сделать, это установить предустановку AVCaptureSession в high
AVCaptureSession *session = [[AVCaptureSession alloc] init];
session.sessionPreset = AVCaptureSessionPresetHigh;
захваченное изображение над размерами после этого 676 × 405 пикселов. Использование категории Tesseract OCR UIImage (изображение называется "источник") для бинаризации изображения:
// Binarize the source image to improve contrast (using the UIImage category provided by TesseractOCR)
UIImage *blackAndWhiteImage = [source blackAndWhite];
[self.tesseract setImage:blackAndWhiteImage];
это обычно преобразует символ деления в текст " - 1 -", но я видел "-: - " и другие цифры и символы верхнего регистра между минусом знаки.
Я могу проверить это в возвращенном тексте. Но тогда невозможно знать, рассматривать ли возвращаемый текст "8-1-2" как истинное вычитание или "возможно" деление.
5 ответов
поезд или двигатель остроумие различных шрифтов.
здесь является инструментом для обучения двигателя. Посмотрите на этой и
или вы можете использовать JTessBoxEditor
убедитесь, что ваш "белый список" включает"÷" знак.
в swift это сделает это:tesseract.setVariableValue("0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ:;,.!-()#&÷", forKey: "tessedit_char_whitelist")
в objective-C, вот код:
[tesseract setVariableValue:@"0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ:;,.!-()#&÷" forKey:@"tessedit_char_whitelist"];
вы можете настроить набор символов на основе ваших потребностей.
кажется, что символ не был включен в существующие данные. Вам нужно железнодорожный для этого символа, а затем используйте результирующие traineddata в сочетании с существующими.
вы можете использовать инструмент, например jTessBoxEditor, чтобы помочь вам в процессе обучения.
вы также можете попытаться захватить эту двусмысленность с помощью файла unicharambigs. Читать дальше https://github.com/tesseract-ocr/tesseract/blob/master/doc/unicharambigs.5.asc.
1 + 1 ÷ 0
Tesseract прочитал бы его как " необязательно (конечный 0 в приведенной выше конфигурации) замените последовательность 1 символа '+' на последовательность 1 символа '÷'".
в Swift, изменение engineMode для меня
let tesseract = G8Tesseract(language: "eng")!
tesseract.engineMode = .tesseractCubeCombined