тест нормальности распределения в python
У меня есть некоторые данные, которые я выбрал из спутникового изображения радара и хотел выполнить некоторые статистические тесты. До этого я хотел провести тест на нормальность, чтобы убедиться, что мои данные распределены нормально. Мои данные, похоже, нормально распределены, но когда я выполняю тест Im, получая Pvalue 0, предполагая, что мои данные не распределены нормально.
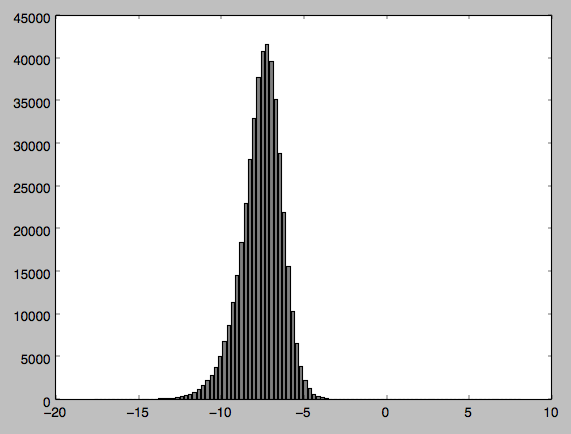
я прикрепил свой код вместе с выводом и гистограммой распределения (Im относительно новый для python так что извиняюсь, если мой код неуклюжий в любом случае). Может кто-нибудь сказать мне, если я делаю что-то неправильно - мне трудно поверить, с моей гистограммы, что мои данные не распределены нормально?
values = 'inputfile.h5'
f = h5py.File(values,'r')
dset = f['/DATA/DATA']
array = dset[...,0]
print('normality =', scipy.stats.normaltest(array))
max = np.amax(array)
min = np.amin(array)
histo = np.histogram(array, bins=100, range=(min, max))
freqs = histo[0]
rangebins = (max - min)
numberbins = (len(histo[1])-1)
interval = (rangebins/numberbins)
newbins = np.arange((min), (max), interval)
histogram = bar(newbins, freqs, width=0.2, color='gray')
plt.show()
Это печатает это: (41099.095955202931, 0.0). первый элемент-это значение хи-квадрат, а второй-pvalue.
Я сделал график данных, которые я приложил. Я подумал, что, возможно, как я имею дело с отрицательными значениями, это вызывает проблему, поэтому я нормализовал значения, но проблема сохраняется.
2 ответов
В общем случае, когда количество образцов меньше 50, вы должны быть осторожны с использованием тестов нормальности. Поскольку эти тесты нуждаются в достаточных доказательствах, чтобы отклонить нулевую гипотезу ,которая является "распределение данных нормально", и когда количество выборок невелико, они не могут найти эти доказательства.
имейте в виду, что когда вы не можете отклонить нулевую гипотезу, это не означает, что альтернативная гипотеза верна.
есть еще один возможность того, что: Некоторые реализации статистических тестов на нормальность сравнивают распределение ваших данных со стандартным нормальным распределением. Чтобы избежать этого, я предлагаю вам стандартизировать данные, а затем применить тест нормальности.
этот вопрос объясняет, почему вы получаете такое маленькое p-значение. По сути, тесты нормальности почти всегда отклоняют нуль на очень больших размерах выборки (в вашем, например, вы можете увидеть только некоторый перекос в левой части, что при вашем огромном размере выборки более чем достаточно).
что было бы гораздо более практичным в вашем случае, это построить нормальную кривую, соответствующую вашим данным. Затем вы можете увидеть, как на самом деле отличается нормальная кривая (например, вы можно увидеть, действительно ли хвост с левой стороны слишком длинный). Например:
from matplotlib import pyplot as plt
import matplotlib.mlab as mlab
n, bins, patches = plt.hist(array, 50, normed=1)
mu = np.mean(array)
sigma = np.std(array)
plt.plot(bins, mlab.normpdf(bins, mu, sigma))
(обратите внимание на normed=1 аргумент: это гарантирует, что гистограмма нормализуется, чтобы иметь общую площадь 1, что делает ее сопоставимой с плотностью, такой как нормальное распределение).