Установить NOCOUNT на использование
вдохновленный этот вопрос где существуют различные представления о SET NOCOUNT...
следует ли использовать SET NOCOUNT ON для SQL Server? Если нет, то почему?
что это значит Edit 6, on 22 Jul 2011
Он подавляет сообщение" xx строк, затронутых " после любого DML. Это ResultSet и при отправке, клиент должен обработать его. Это крошечный, но измеримый (см. ответы ниже)
для триггеров и т. д., клиент получит несколько "затронутых строк xx", и это вызывает всевозможные ошибки для некоторых ORMs, MS Access, JPA и т. д. (см. изменения ниже)
Справочная информация:
общепринятая лучшая практика (я думал, пока этот вопрос) - использовать SET NOCOUNT ON в триггерах и хранимых процедурах в SQL Server. Мы используем его везде, и быстрый google показывает много MVPs SQL Server, соглашаясь тоже.
MSDN говорит, что это может сломать .net SQLDataAdapter.
Теперь это означает, что SQLDataAdapter ограничен совершенно простой обработкой CRUD, потому что он ожидает, что сообщение "n строк, затронутых", будет соответствовать. Итак, я не могу использовать:
- если существует, чтобы избежать дублирования (нет строк, затронутых сообщением)Примечание: используйте с осторожностью
- где не существует (меньше строк, чем ожидалось
- отфильтровать тривиальные обновления (например, данные фактически не меняются)
- сделать любой доступ к таблице до (например, ведение журнала)
- скрыть сложность или denormlisation
- etc
в вопросе marc_s (кто знает его материал SQL) говорит, что не используйте его. Это отличается от того, что я думаю (и я считаю себя несколько компетентным в SQL тоже).
возможно, я что-то упускаю (не стесняйтесь указывать на очевидное), но что вы там думаете?
Примечание: прошло много лет с тех пор, как я видел эту ошибку, потому что я не используйте SQLDataAdapter в настоящее время.
редактирование после комментариев и вопросов:
Edit: больше мыслей...
У нас есть несколько клиентов: один может использовать C# SQLDataAdaptor, другой может использовать nHibernate из Java. Они могут быть затронуты по-разному с SET NOCOUNT ON.
Если вы рассматриваете хранимые процессы как методы, то это плохая форма (анти-шаблон), чтобы предположить, что некоторая внутренняя обработка работает определенным образом для вашего собственного цели.
Edit 2: a триггер ломая nHibernate вопрос, где SET NOCOUNT ON невозможно установить
(и нет, это не дубликат этой)
Edit 3: Еще больше информации, благодаря моему коллеге MVP
- КБ 240882, проблема вызывает разъединения на SQL 2000 и ранее
- демо прироста производительности
Изменить 4: 13 Мая
ломает Linq 2 SQL тоже, когда не указано?
Редактировать 5: 14 Июн 2011
ломает JPA, сохраненный proc с переменными таблицы:поддерживает ли JPA 2.0 переменные таблицы SQL Server?
Edit 6: 15 Aug 2011
SSMS "редактировать строки" сетка данных требует установить NOCOUNT на:обновить триггер с помощью GROUP BY
Edit 7: 07 Mar 2013
более подробно из @RemusRusanu:
действительно ли установка NOCOUNT на самом деле делает такую большую разницу в производительности
12 ответов
хорошо, теперь я сделал свое исследование, вот сделка:
в протоколе TDS,SET NOCOUNT ON только экономит 9-байт на запрос в то время как текст "SET NOCOUNT ON" сам по себе является колоссальным 14 байтами. Раньше я думал, что 123 row(s) affected был возвращен с сервера в виде обычного текста в отдельном сетевом пакете, но это не так. На самом деле это небольшая структура под названием DONE_IN_PROC врезал в ответ. Это не отдельные сетевые пакеты, так что никаких обращений впустую.
Я думаю, что вы может придерживаться поведения подсчета по умолчанию почти всегда, не беспокоясь о производительности. Однако есть несколько случаев, когда вычисление количества строк заранее повлияет на производительность, например, курсор только вперед. В этом случае NOCOUNT может быть необходимостью. Кроме этого, нет абсолютно никакой необходимости следовать девизу "использовать NOCOUNT везде, где это возможно".
вот очень подробный анализ о незначительности SET NOCOUNT настройка: http://daleburnett.com/2014/01/everything-ever-wanted-know-set-nocount/
Мне потребовалось много копать, чтобы найти реальные контрольные цифры вокруг NOCOUNT, поэтому я решил поделиться быстрым резюме.
- Если хранимая процедура использует курсор для выполнения множества очень быстрых операций без возвращаемых результатов, отключение NOCOUNT может занять примерно в 10 раз больше времени, чем его включение. 1 это худший сценарий.
- Если хранимая процедура выполняет только одну быструю операцию без возврата результаты, установка NOCOUNT ON даст около 3% повышения производительности. 2 это будет соответствовать типичной процедуре вставки или обновления.
- Если хранимая процедура возвращает результаты (т. е. вы выбираете что-то), разница в производительности будет уменьшаться пропорционально размеру результирующего набора.
когда SET NOCOUNT включен, счетчик (указывающий количество строк, на которые влияет инструкция Transact-SQL) не возвращается. Когда SET NOCOUNT выключен, счетчик возвращается. Он используется с любой операцией SELECT, INSERT, UPDATE, DELETE.
настройка SET NOCOUNT устанавливается во время выполнения или выполнения, а не во время синтаксического анализа.
SET NOCOUNT ON улучшает хранимую процедуру (SP) спектакль.
синтаксис: SET NOCOUNT { ON / OFF }
пример SET NOCOUNT ON:
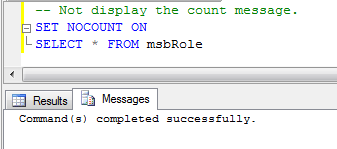
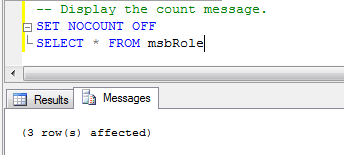
пример SET NOCOUNT OFF:
Я думаю, в какой-то степени это проблема DBA против разработчика.
как dev в основном, я бы сказал, Не используйте его, если вы абсолютно положительно не должны - потому что использование его может сломать ваш ADO.NET код (как задокументировано Microsoft).
и я думаю, как DBA, вы были бы больше на другой стороне-используйте его, когда это возможно, если вы действительно не должны предотвратить его использование.
кроме того, если ваши разработчики когда-либо использовали "RecordsAffected", возвращаемый ADO.NET s ExecuteNonQuery вызов метода, вы в беде, если все используют SET NOCOUNT ON так как в этом случае ExecuteNonQuery всегда будет возвращать 0.
также смотрите Питера Бромберга блоге и проверьте его положение.
Так что это действительно сводится к тому, кто будет устанавливать стандарты :-)
Марк
Если вы говорите, что у вас могут быть разные клиенты, есть проблемы с классическим ADO, если SET NOCOUNT не установлен.
один я испытываю регулярно: если хранимая процедура выполняет ряд операторов (и, таким образом, возвращается несколько сообщений "xxx строк, затронутых"), ADO, похоже, не обрабатывает это и выдает ошибку " невозможно изменить свойство ActiveConnection объекта набора записей, источником которого является объект Command."
Так Что Я обычно адвокат устанавливает его, если нет действительно хорошая причина не делать. возможно, вы нашли действительно очень хорошую причину, по которой мне нужно пойти и прочитать больше.
рискуя сделать вещи более сложными, я призываю немного другое правило для всех тех, кого я вижу выше:
- всегда ставим
NOCOUNT ONв верхней части proc, прежде чем делать какую-либо работу в proc, но и всегдаSET NOCOUNT OFFснова, прежде чем вернуться любой набор записей из хранимой тез.Докл.
поэтому "обычно держите nocount, за исключением случаев, когда вы фактически возвращаете resultset". Я не знаю, как это может сломать любой клиентский код, это означает, что клиентский код никогда не должен ничего знать о внутренних процессах proc, и это не особенно обременительно.
Что касается триггеров, разрушающих NHibernate, у меня был этот опыт из первых рук. В принципе, когда NH делает обновление, он ожидает определенное количество затронутых строк. Добавляя SET NOCOUNT в триггеры, вы получаете количество строк обратно к ожидаемому NH, тем самым устраняя проблему. Так что да, я бы определенно рекомендовал отключить его для триггеров, если вы используете NH.
Что касается использования в SPs, это вопрос личных предпочтений. Я всегда отключал счетчик строк, но потом ... опять же, нет никаких серьезных аргументов в любом случае.
на другой ноте, вы должны действительно рассмотреть вопрос о переходе от архитектуры на основе SP, тогда у вас даже не будет этого вопроса.
УСТАНОВИТЬ NOCOUNT НА; Вышеуказанный код остановит сообщение, сгенерированное SQL server engine для переднего окна результата после выполнения команды DML/DDL.
Почему мы это делаем? Поскольку SQL server engine требует некоторого ресурса для получения состояния и создания сообщения, он считается перегрузкой SQL server engine.Поэтому мы включили неучтенное сообщение.
Я не знаю, как протестировать SET NOCOUNT между клиентом и SQL, поэтому я тестировал аналогичное поведение для другой команды SET "SET TRANSACTION ISOLATION LEVEL READ UNCIMMITTED"
Я отправил команду из моего соединения, изменив поведение SQL по умолчанию (Read COMMITTED), и она была изменена для следующих команд. Когда я изменил уровень изоляции внутри хранимой процедуры, это не изменило поведение соединения для следующей команды.
текущая заключение
- Изменение параметров внутри хранимой процедуры не менять настройки по умолчанию подключение.
- изменение настроек путем отправки команд с помощью ADOCOnnection изменяет поведение по умолчанию.
Я думаю, что это относится к другой команде SET, такой как"SET NOCOUNT ON"
SET NOCOUNT ON;
эта строка кода используется в SQL не возвращает количество строк, затронутых при выполнении запроса. Если нам не требуется количество затронутых строк, мы можем использовать это, так как это поможет сохранить использование памяти и увеличить скорость выполнения запроса.
if (set no count== off)
{ затем он будет держать данные о том, сколько записей так уменьшите представление } еще { он не будет отслеживать изменения следовательно, улучшить perfomace } }
Я знаю, это довольно старый вопрос. но только для обновления.
лучший способ использовать "SET NOCOUNT ON" - поместить его в качестве первого оператора в SP и снова отключить его перед последним оператором SELECT.