Установка идеального размера пула потоков [дубликат]
этот вопрос уже есть ответ здесь:
в чем разница между-
newSingleThreadExecutor vs newFixedThreadPool(20)
С точки зрения операционной системы и программирования точки зрения.
всякий раз, когда я запускаю программа с использованием newSingleThreadExecutor моя программа работает очень хорошо и от конца до конца латентность (95-й процентиль) приходит вокруг 5ms.
но как только я начну запускать свою программу с помощью-
newFixedThreadPool(20)
моя производительность программы ухудшается, и я начинаю видеть конец в конец задержки как 37ms.
Итак, теперь я пытаюсь понять с точки зрения архитектуры, что означает количество потоков здесь? И как решить, какое оптимальное количество потоков я должен выбрать?
и если я использую больше потоков, то что произойдет?
если кто-нибудь может объяснить мне эти простые вещи на языке обывателя, то это будет очень полезно для меня. Спасибо за помощь.
my machine config spec-я запускаю свою программу с Linux-машины -
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 45
model name : Intel(R) Xeon(R) CPU E5-2670 0 @ 2.60GHz
stepping : 7
cpu MHz : 2599.999
cache size : 20480 KB
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology tsc_reliable nonstop_tsc aperfmperf pni pclmulqdq ssse3 cx16 sse4_1 sse4_2 popcnt aes hypervisor lahf_lm arat pln pts
bogomips : 5199.99
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 45
model name : Intel(R) Xeon(R) CPU E5-2670 0 @ 2.60GHz
stepping : 7
cpu MHz : 2599.999
cache size : 20480 KB
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology tsc_reliable nonstop_tsc aperfmperf pni pclmulqdq ssse3 cx16 sse4_1 sse4_2 popcnt aes hypervisor lahf_lm arat pln pts
bogomips : 5199.99
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
power management:
3 ответов
Ok. В идеале предполагая, что ваши потоки не имеют блокировки, так что они не блокируют друг друга (независимо друг от друга), и вы можете предположить, что рабочая нагрузка (обработка) одинакова, тогда получается, что размер пула Runtime.getRuntime().availableProcessors() или availableProcessors() + 1 дает наилучшие результаты.
но, скажем, если потоки мешают друг другу или I/O inlvolved, то закон Амадаля объясняет довольно хорошо. Из Вики,
закон Амдала гласит, что если P-доля программа, которую можно сделать параллельной (т. е. извлечь выгоду из распараллеливания), и (1 - P) - это пропорция, которая не может быть распараллелена (остается последовательной), тогда максимальное ускорение, которое может быть достигнуто с помощью n процессоров, -
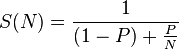
в вашем случае, основываясь на количестве доступных ядер, и какую работу они точно выполняют (чистое вычисление? I / O? держать замки? заблокирован для какого-то ресурса? так далее..), вам нужно придумать решение, основанное на выше параметры.
например: несколько месяцев назад я занимался сбором данных с цифровых веб-сайтов. Моя машина была 4-core и у меня был размер бассейна 4. Но ведь операция была чисто I/O и моя чистая скорость была приличной, я понял, что у меня лучшая производительность с размером пула 7. И это потому, что потоки боролись не за вычислительную мощность, А за I / O. поэтому я мог использовать тот факт, что больше потоков могут конкурировать за ядро положительно.
PS: Я предлагаю, проходя через производительность главы из книги - параллелизм Java на практике Брайана Гетца. В нем подробно рассматриваются такие вопросы.
Итак, теперь я пытаюсь понять с точки зрения архитектуры, что означает количество потоков здесь?
каждый поток имеет свою собственную память стека, счетчик программ (например, указатель на то, какая инструкция выполняется дальше) и другие локальные ресурсы. Замена их вредит задержке для одной задачи. Преимущество заключается в том, что пока один поток простаивает (обычно при ожидании ввода-вывода), другой поток может выполнить работу. Также, если доступно несколько процессоров, они могут выполняться параллельно, если между задачами нет конфликта ресурсов и/или блокировки.
и как решить, какое оптимальное количество потоков я должен выбрать?
компромисс между ценой свопа и возможностью избежать простоя зависит от небольших деталей того, как выглядит ваша задача (сколько ввода/вывода и когда, с каким количеством работы между вводом/выводом, используя сколько памяти для завершения). Экспериментирование-это всегда ключ.
и если я использую больше потоков, то что произойдет?
обычно сначала будет линейный рост пропускной способности, затем относительная плоская часть, затем падение (которое может быть довольно крутым). Каждая система различна.
смотреть на закон Амдала прекрасно, особенно если вы точно знаете, насколько велики P и N. Поскольку этого никогда не произойдет, вы можете контролировать производительность (что вы должны делать в любом случае) и увеличивать/уменьшать размер пула потоков, чтобы оптимизировать любые показатели производительности, важные для вас.