В чем разница между генеративным и дискриминативным алгоритмами?
пожалуйста, помогите мне понять разницу между генеративных и дискриминационных алгоритм, имея в виду, что я всего лишь новичок.
10 ответов
предположим, у вас есть входные данные x, и вы хотите классифицировать данные в метки y. Генеративная модель изучает joint распределение вероятностей p(x,y) и дискриминативная модель узнает условный распределение вероятностей p(y|x) - которые вы должны прочитать как "вероятность y заданного x".
вот очень простой пример. Предположим, у вас есть следующие данные в форме (x, y):
(1,0), (1,0), (2,0), (2, 1)
p(x,y) и
y=0 y=1
-----------
x=1 | 1/2 0
x=2 | 1/4 1/4
p(y|x) is
y=0 y=1
-----------
x=1 | 1 0
x=2 | 1/2 1/2
если вы уделите несколько минут, чтобы посмотреть на эти две матрицы, вы поймете разницу между двумя распределениями вероятностей.
распределение p(y|x) является естественным распределением для классификации данного примера x в классе y, поэтому алгоритмы, которые моделируют это напрямую, называются дискриминационными алгоритмами. Генеративные алгоритмы model p(x,y), который может быть преобразован в p(y|x) применяя правило Байеса, а затем используется для классификации. Однако распределение p(x,y) можно также использовать для других целей. Например, вы можете использовать p(x,y) to создать скорее (x,y) пар.
из приведенного выше описания вы можете подумать, что генеративные модели более полезны и, следовательно, лучше, но это не так просто. этой статье это очень популярная ссылка на предмет дискриминационных и генеративных классификаторов,но она довольно тяжелая. Общая суть заключается в том, что дискриминационные модели обычно превосходят генеративные модели в задачах классификации.
A генеративных алгоритм моделирует, как данные были сгенерированы для классификации сигнала. Он задает вопрос: основываясь на предположениях моего поколения, какая категория, скорее всего, будет генерировать этот сигнал?
A дискриминационный алгоритм не заботится о том, как были сгенерированы данные, он просто классифицирует данный сигнал.
представьте, что ваша задача-классифицировать слова на язык.
вы можете сделать это либо:
- обучение каждого языка, а затем классифицировать его, используя знания, которые вы только что получили
или
- определение различий в лингвистических моделях без изучения языков, а затем классификация речи.
первое-это генеративных подход и второй the дискриминационных подход.
проверьте эту ссылку для получения более подробной информации: http://www.cedar.buffalo.edu/~srihari/CSE574/Discriminative-Generative.pdf.
на практике модели используются следующим образом.
на дискриминационной модели, предсказать ярлык y из примера обучения x, вы должны оценить:
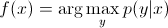
который просто выбирает, что является наиболее вероятным классом y учитывая x. Как будто мы пытались ... --11-->моделируйте границу решения между классами. Такое поведение очень ясно в нейронных сетях, где вычисленные веса можно рассматривать как кривую сложной формы, изолирующую элементы класса в пространстве.
теперь, используя правило Байеса, давайте заменим 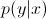 в уравнение
в уравнение 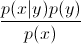 . Так как вы просто заинтересованы в arg max, вы можете стереть знаменатель, который будет одинаковым для каждого
. Так как вы просто заинтересованы в arg max, вы можете стереть знаменатель, который будет одинаковым для каждого y. Итак, вы остаетесь с
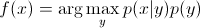
которое уравнение вы используете в генеративной модели.
а в первый случай у вас был условное распределение вероятностей p(y|x), который моделировал границу между классами, во втором вы имели совместное распределение вероятностей p( x, y), так как p(x, y) = p(x | y) p(y), который явно моделирует фактическое распределение каждого класса.
С совместной функцией распределения вероятности, учитывая y, вы можете вычислить ("создать") его соответствующий x. По этой причине они так называемые" генеративные " модели.
вот самая важная часть из конспекты CS299 (by Andrew Ng), связанного с темой, которая действительно помогает мне понять разницу между дискриминационных и генеративных алгоритмы обучения.
предположим, что у нас есть два класса животных: слон(y = 1) и собака(y = 0). И x характеристика животных.
учитывая обучающий набор, алгоритм, такой как логистическая регрессия или алгоритм персептрона (в основном) пытается найти прямую линию-то есть граница решения-то, что разделяет слонов и собак. Затем, чтобы классифицировать новое животное, как слон или собака, проверяет, с какой стороны граница решения падает, и делает свое предсказание соответственно. Мы называем это дискриминационный алгоритм обучения.
вот другой подход. Во-первых, глядя на слонов, мы можем построить модель того, как выглядят слоны. Затем, глядя на собак, мы можем построить отдельная модель того, как выглядят собаки. Наконец, классифицировать новое животное, мы можем сопоставить новое животное с моделью слона и сопоставить его с модель собаки, чтобы увидеть, является ли новое животное больше похоже на слонов или больше похожи на собак, которых мы видели на тренировках. Мы называем это генеративный алгоритм обучения.
Как правило, в сообществе машинного обучения существует практика не изучать то, что вы не хотите. Например, рассмотрим задачу классификации, где целью является присвоение y меток заданному X входу. Если мы используем генеративную модель
p(x,y)=p(y|x).p(x)
мы должны моделировать p (x), что не имеет значения для рассматриваемой задачи. Практические ограничения, такие как разреженность данных, заставят нас моделировать p(x) С некоторыми слабыми предположениями о независимости. Поэтому мы интуитивно используем дискриминационные модели классификации.
дополнительный информативный момент, который хорошо сочетается с ответом StompChicken выше.
на принципиальная разница между дискриминационной модели и генеративной модели - это:
дискриминационной модели узнать (жесткий или мягкий) границы между классами
генеративной модели модель распределение of отдельные классы
Edit:
генеративная модель-это одна который может генерировать данные. Он моделирует как функции, так и класс (т. е. полные данные).
если мы модель P(x,y): Я могу использовать это распределение вероятности для генерации точек данных-и, следовательно, всех алгоритмов моделирования P(x,y) генеративных.
например. генеративных моделей
-
модели упрощенного алгоритма Байеса
P(c)иP(d|c)- гдеcкласс аd- вектор объектов.и
P(c,d) = P(c) * P(d|c)следовательно, наивный Байес в некоторых моделях форма,
P(c,d) Байесовской Сети
Марковских Сетей
дискриминационная модель-это та, которая может использоваться только для различать / классифицировать точки данных.
Вам нужно только моделировать P(y|x) в таких случаях (т. е. вероятность класс, заданный вектор объектов).
например. дискриминационных моделей:
логистическая регрессия
Нейронные Сети
условные случайные поля
в общем, генеративные модели должны моделировать гораздо больше, чем дискриминационные модели, и поэтому иногда не так эффективны. На самом деле, большинство (не уверен, если все) неконтролируемые алгоритмы обучения например, кластеризацию и т. д. можно назвать генеративной, поскольку они моделируют P(d) (и нет классов: P)
PS: часть ответа взята из источник

мои два цента: Дискриминационные подходы подчеркивают различия Генеративные подходы делают акцент не на различиях, они пытаются построить модель, которая является представителем класса. Между ними есть перекрытие. В идеале следует использовать оба подхода: один будет полезен для поиска сходств, а другой-для поиска сходств.
генеративная модель алгоритма будет полностью учиться на данных обучения и будет прогнозировать ответ.
задача дискриминативного алгоритма - просто классифицировать или различать 2 результата.