В чем разница между марковскими цепями и скрытой Марковской моделью?
в чем разница между моделями марковских цепей и скрытой марковской модели? Я читал в Википедии, но не мог понять разницы.
5 ответов
объяснить на примере, я буду использовать пример из обработки естественного языка. Представьте, что вы хотите знать вероятность этого предложения:
Я люблю кофе
в марковской модели вы можете оценить ее вероятность путем вычисления:
P(WORD = I) x P(WORD = enjoy | PREVIOUS_WORD = I) x P(word = coffee| PREVIOUS_WORD = enjoy)
мы не наблюдать любой теги частей речи в этом предложении, но мы предположим они есть. Таким образом, мы вычисляем, какова вероятность последовательности тегов частей речи. В нашем случае фактическая последовательность:
PRP-VBP-NN
(где PRP= "личное местоимение", VBP= "глагол, не являющийся 3-м лицом единственного числа", NN= "существительное, единственное или масса". См.https://cs.nyu.edu/grishman/jet/guide/PennPOS.html для полной нотации Penn POS пометка)
но подождите! Это последовательность, к которой мы можем применить Марковскую модель. Но мы называем это скрытым, поскольку последовательность частей речи никогда не наблюдается непосредственно. Конечно, на практике мы будем вычислять много таких последовательностей, и мы хотели бы найти скрытую последовательность, которая лучше всего объясняет наше наблюдение (например, мы с большей вероятностью увидим такие слова, как "the", "this", сгенерированные из тега determiner (DET))
лучшее объяснение, с которым я когда-либо сталкивался, находится в документ от 1989 Р. Лоуренс Рабинера: http://www.cs.ubc.ca/~murphyk/Байеса/Рабинера.формат PDF
модель Маркова-это государственную машину с государственным изменениям вероятностей. В скрытой марковской модели, вы не знаете вероятностей, но вы знаете результаты.
например, когда вы переворачиваете монету, вы можете получить вероятности, но, если вы не могли видеть сальто, и кто-то перемещает один из пяти пальцев с каждым сальто монеты, вы можете взять движения пальцев и использовать скрытую модель Маркова, чтобы получить лучшее предположение о монетных сальто.
поскольку Мэтт использовал теги частей речи в качестве примера HMM, я мог бы добавить еще один пример: распознавание речи. Почти все большие словарные системы непрерывного распознавания речи (LVCSR) основаны на HMMs.
"Мэтта ": Я люблю кофев марковской модели, вы можете оценить его вероятность, вычисляя:
P(WORD = I) x P(WORD = enjoy | PREVIOUS_WORD = I) x P(word = coffee| PREVIOUS_WORD = enjoy)
В Скрытой марковской модели,
допустим, 30 разных людей читают предложение "Я люблю обниматься" и мы должны признать это. Каждый произнесет это предложение по-своему. Поэтому мы не знаем, имел ли человек в виду" обниматься "или"тискаться". Мы будем иметь только вероятностное распределение фактического слова.
короче говоря, скрытая Марковская модель-это статистическая Марковская модель, в которой моделируемая система считается Марковским процессом с ненаблюдаемыми (скрытыми) состояниями.
скрытые модели Маркова-это двойной встроенный стохастический процесс с двумя уровнями.
верхний уровень-это Марковский процесс, и состояния ненаблюдаемы.
фактически, наблюдение является вероятностной функцией состояний Маркова верхнего уровня.
различные состояния Маркова будут иметь разные вероятностные функции наблюдения.
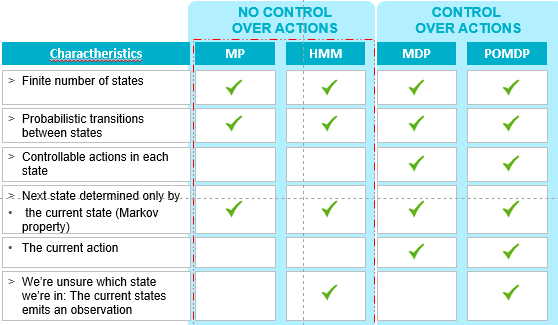
Марковский процесс (MP) - стохастический процесс с (1) конечным числом состояний (2) вероятностными переходами между этими состояниями (3) следующее состояние определяется только текущим состоянием (свойство Маркова)
скрытый Марковский процесс (хмм) также является стохастическим процессом (1) конечное число состояний (2) вероятностные переходы между этими состояниями (3) следующее состояние определяется только текущим состоянием (свойство Маркова) и (4) мы не уверены, в каком состоянии мы находимся: текущее состояние испускает наблюдение.
пример - (хмм) фондовый рынок:
На фондовом рынке люди торгуют ценностью фирмы. Предположим, что реальная стоимость акции составляет $100 (это ненаблюдается, а на самом деле вы никогда не знаете). То, что вы действительно видите, - это значение, с которым он торгуется: предположим, в этом случае $90 (это заметно).
для людей, заинтересованных в Маркове: интересная часть, когда вы начинаете принимать меры по этим моделям (в предыдущем примере, чтобы получить деньги). Это Марковские процессы принятия решений (Пру) и частично наблюдаемых процессов принятия решений Маркова (POMDPs). Чтобы оценить общую классификацию этих моделей, я суммировал на следующем рисунке основные характеристики каждой марковской модели.