В чем разница между обладанием и где?
должно быть, я гуглю неправильно, или у меня глупый момент во времени.
в чем разница между HAVING и WHERE на SQL SELECT заявление?
EDIT: я отметил ответ Стивена как правильный, поскольку он содержал ключевой бит информации по ссылке:
, когда
GROUP BYне используется,HAVINGведет себя какWHEREп.
ситуацию я видел WHERE не было GROUP BY и где моя катавасия началась. Конечно, пока вы не знаете этого, вы не можете указать это в вопросе.
большое спасибо за все ответы, которые были очень поучительно.
20 ответов
наличие: используется для проверки условий после агрегация происходит.
Где: используется для проверки условий до агрегация происходит.
этот код:
select City, CNT=Count(1)
From Address
Where State = 'MA'
Group By City
дает вам таблицу всех городов в МА и количеству адресов в каждом городе.
этот код:
select City, CNT=Count(1)
From Address
Where State = 'MA'
Group By City
Having Count(1)>5
дает вам таблицу городов в МА с более чем 5 адресами и количеством адресов в каждом городе.
разница между WHERE и HAVING предложение:
1. где пункт может использоваться с-Select, Insert и Update операторы, где as имея пункт можно использовать только с инструкцией Select.
2. здесь фильтрует строки перед агрегацией (группировкой), где as,С фильтры группы, после выполнения агрегаций.
3. агрегатные функции нельзя использовать в где пункт, если он не находится в подзапросе, содержащемся в имея пункт, тогда как агрегатные функции могут использоваться в предложении Having.
Фильтрация Групп:
where предложение используется для фильтрации строк перед агрегацией, где as HAVING предложение используется для фильтрации групп после агрегации
Select City, SUM(Salary) as TotalSalary
from tblEmployee
Where Gender = 'Male'
group by City
Having City = 'London'
в SQL Server у нас есть много агрегатных функций. примеры
Count()Sum()avg()Min()Max()
разница номер один для меня: если HAVING был удален из языка SQL, тогда жизнь продолжалась бы более или менее, как и раньше. Конечно, запросы меньшинства должны быть переписаны с использованием производной таблицы, CTE и т. д., Но они, возможно, будут легче понять и поддерживать в результате. Возможно, код оптимизатора поставщиков нужно будет переписать, чтобы учесть это, снова возможность для улучшения в отрасли.
Теперь рассмотрим на мгновение удаление WHERE от языка. На этот раз большинство существующих запросов необходимо будет переписать без очевидной альтернативной конструкции. Кодеры должны были бы получить творческое, например, внутреннее соединение с таблицей, содержащей ровно одну строку (например,DUAL в Oracle) с помощью ON предложение для имитации предыдущего WHERE предложения. Такие конструкции были бы надуманными; было бы очевидно, что в языке чего-то не хватает, и ситуация была бы хуже, чем результат.
TL; DR мы можем потерять WHERE.
из ответов здесь, кажется, что многие люди не понимают, что HAVING предложение может использоваться без GROUP BY предложения. В этом случае HAVING предложение применяется ко всему выражению таблицы и требует, чтобы в SELECT предложения. Обычно HAVING пункт будет включать инертные материалы.
это более полезно, чем кажется. Например, рассмотрим этот запрос, чтобы проверить, является ли name столбец уникален для всех значений в T:
SELECT 1 AS result
FROM T
HAVING COUNT( DISTINCT name ) = COUNT( name );
есть только два возможных результата: если HAVING предложение true тогда результат с одной строкой, содержащей значение 1, в противном случае результатом будет пустое множество.
предложение HAVING было добавлено в SQL, поскольку ключевое слово WHERE не может использоваться с агрегатными функциями.
зацените w3schools ссылке для получения дополнительной информации
синтаксис:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING aggregate_function(column_name) operator value
такой запрос:
SELECT column_name, COUNT( column_name ) AS column_name_tally
FROM table_name
WHERE column_name < 3
GROUP
BY column_name
HAVING COUNT( column_name ) >= 3;
...может быть переписан с использованием производной таблицы (и опуская HAVING) такой:
SELECT column_name, column_name_tally
FROM (
SELECT column_name, COUNT(column_name) AS column_name_tally
FROM table_name
WHERE column_name < 3
GROUP
BY column_name
) pointless_range_variable_required_here
WHERE column_name_tally >= 3;
разница между ними заключается в отношении к предложению GROUP BY:
WHERE предшествует GROUP BY; SQL оценивает предложение WHERE перед группированием записей.
наличие приходит после GROUP BY; SQL оценивает наличие после него групп записей.

ссылки
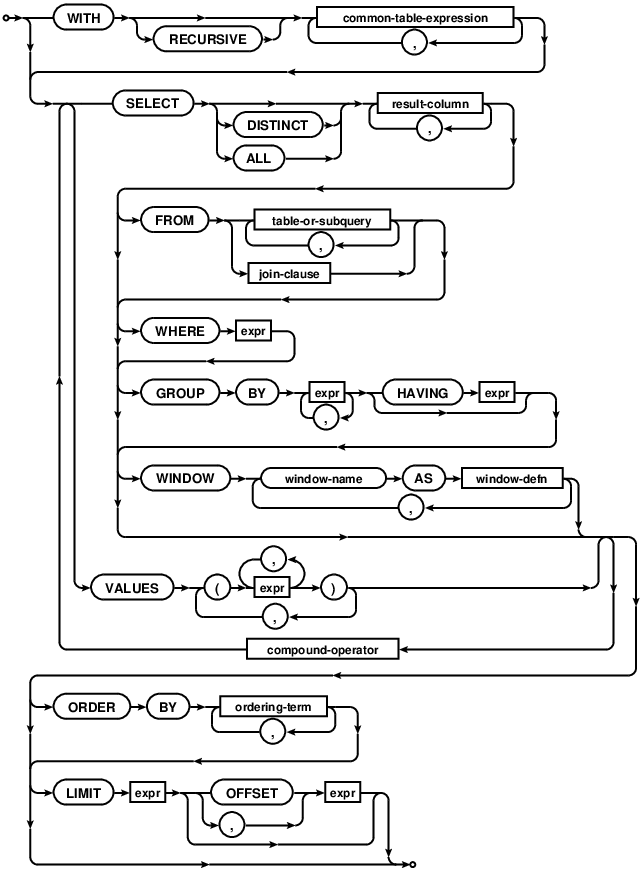{kind=link}
HAVING используется, когда вы используете агрегат, такой как GROUP BY.
SELECT edc_country, COUNT(*)
FROM Ed_Centers
GROUP BY edc_country
HAVING COUNT(*) > 1
ORDER BY edc_country;
WHERE применяется в качестве ограничения для набора, возвращаемого SQL; он использует встроенные наборы oeprations и индексы SQL и, следовательно, является самым быстрым способом фильтрации результирующих наборов. Всегда используйте, где это возможно.
наличие необходимо для некоторых агрегатных фильтров. Он фильтрует запрос после того, как sql извлек, собрал и отсортировал результаты. Поэтому он намного медленнее, чем где и следует избегать, за исключением тех ситуаций, которые требуют этого.
SQL Server позволит вам уйти с использованием, даже когда где было бы намного быстрее. Не делай этого.
предложение WHERE не работает для агрегатных функций
значит : вы не должны использовать как это
бонус: название таблицы
SELECT name
FROM bonus
GROUP BY name
WHERE sum(salary) > 200
здесь вместо использования предложения WHERE вы должны использовать HAVING..
без использования предложения GROUP BY, предложение HAVING просто работает как предложение WHERE
SELECT name
FROM bonus
GROUP BY name
HAVING sum(salary) > 200
, когда GROUP BY не используется,WHERE и HAVING положения, по существу, эквивалентны.
GROUP BY используется:
- на
WHEREпункт используется для фильтрации записей из результата. Этот фильтрация происходит до создания группировок. - на
HAVINGпункт используется для фильтрации значений из группы (т. е. проверить условия после выполнения агрегирования в группы).
ресурс здесь
разница b / w WHERE и HAVING статья:
основное различие между WHERE и HAVING предложения WHERE используется для операций подряд и HAVING используется для операций столбцов.
зачем нужны HAVING предложения?
как мы знаем, агрегатные функции могут выполняться только на столбцы, поэтому мы не можем использовать агрегатные функции в WHERE предложения. Поэтому мы используем агрегатные функции в HAVING предложения.
у меня была проблема, и я обнаружил еще одну разницу между WHERE и HAVING. Он не действует таким же образом на индексированные столбцы.
WHERE my_indexed_row = 123 покажет строки и автоматически выполнит "ORDER ASC" на других индексированных строках.
HAVING my_indexed_row = 123 показывает все от самой старой" вставленной " строки до новейшей, без заказа.
в агрегированном запросе (любой запрос, в котором используется агрегатная функция) предикаты в предложении where вычисляются до создания агрегированного промежуточного результирующего набора,
предикаты в предложении Having применяются к совокупному результирующему набору после его создания. Вот почему условия предикатов для агрегированных значений должны быть помещены в предложение Having, а не в предложение Where, и почему вы можете использовать псевдонимы, определенные в предложении Select в предложении Having, но не в предложение WHERE.
where предложение используется для сравнения значений в базовой таблице, тогда как предложение HAVING может использоваться для фильтрации результатов агрегатных функций в результирующем наборе запроса Нажмите здесь!
один из способов подумать об этом заключается в том, что предложение having является дополнительным фильтром к предложению where.
A здесь используется предложение filters записи из результата. Фильтр выполняется до создания каких-либо группировок. А С пункт используется для фильтрации значений из группы
на здесь вычисляется до группировки строк и, следовательно, вычисляется для каждой строки.
на С предложение вычисляется после группировки строк, и поэтому оценивается по группам.
Я использую HAVING для ограничения запроса на основе результатов агрегатной функции. Например, выберите * в группе blahblahblah чем-то, имеющим count(что-то)>0
с здесь.
стандарт SQL требует, чтобы должны ссылаться только на столбцы в Предложение GROUP BY или столбцы, используемые в агрегатные функции
в отличие от предложения WHERE, которое применяется к строкам базы данных
во время работы над проектом, это был мой вопрос. Как указано выше,С проверяет условие на уже найденном результате запроса. Но!--4-->здесь для проверки состояния во время выполнения запроса.
позвольте мне привести пример, чтобы проиллюстрировать это. Предположим, у вас есть такая таблица базы данных.
usertable{ int userid, date datefield, int dailyincome }
предположим, что следующие строки находятся в таблица:
1, 2011-05-20, 100
1, 2011-05-21, 50
1, 2011-05-30, 10
2, 2011-05-30, 10
2, 2011-05-20, 20
Теперь мы хотим получить userids и sum(dailyincome) чей sum(dailyincome)>100
Если мы пишем:
выберите userid, sum (dailyincome) из таблицы usertable, где sum (dailyincome)>100 группа по userid
Это будет ошибка. Правильный запрос будет:
выберите userid, sum (dailyincome) из группы usertable по userid, имеющей sum (dailyincome)>100
может быть просто, что предметом " где "является строка, тогда как предметом "наличия" является группа. Я прав?