В чем разница между SortedList и SortedDictionary?
есть ли какая-либо реальная практическая разница между a SortedList<TKey,TValue> и SortedDictionary<TKey,TValue>? Есть ли какие-либо обстоятельства, при которых вы бы специально использовали один, а не другой?
7 ответов
да - их характеристики значительно отличаются. Наверное, лучше было бы назвать их SortedList и SortedTree поскольку это более точно отражает реализацию.
посмотрите документы MSDN для каждого из них (SortedList, SortedDictionary) для деталей представления для различных деятельностей в различных положениях. Вот хорошее резюме (от SortedDictionary docs):
на
SortedDictionary<TKey, TValue>generic класс двоичное дерево поиска с O (log n) извлечение, где n - количество элементов в словаре. В этом он похож наSortedList<TKey, TValue>generic класс. Два класса имеют сходные объектные модели, и оба имеют O (log n) поиск. Где два класса отличаются в использовании памяти и скорости вставка и удаление:
SortedList<TKey, TValue>использует меньше память чемSortedDictionary<TKey, TValue>.
SortedDictionary<TKey, TValue>есть более быстрые ввод и удаление операции для несортированных данных, O (log n) в отличие от O (n) дляSortedList<TKey, TValue>.если список заполняется сразу из отсортированных данных,
SortedList<TKey, TValue>быстрее, чемSortedDictionary<TKey, TValue>.
(SortedList фактически сохраняет отсортированный массив, а не дерево. Он по-прежнему использует двоичный поиск для поиска элементов.)
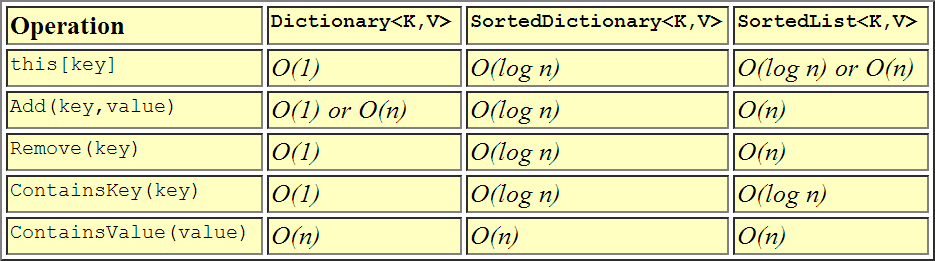
вот табличное представление, если это помогает...
С производительность перспективы:
+------------------+---------+----------+--------+----------+----------+---------+
| Collection | Indexed | Keyed | Value | Addition | Removal | Memory |
| | lookup | lookup | lookup | | | |
+------------------+---------+----------+--------+----------+----------+---------+
| SortedList | O(1) | O(log n) | O(n) | O(n)* | O(n) | Lesser |
| SortedDictionary | n/a | O(log n) | O(n) | O(log n) | O(log n) | Greater |
+------------------+---------+----------+--------+----------+----------+---------+
* Insertion is O(1) for data that are already in sort order, so that each
element is added to the end of the list (assuming no resize is required).
С реализация перспективы:
+------------+---------------+----------+------------+------------+------------------+
| Underlying | Lookup | Ordering | Contiguous | Data | Exposes Key & |
| structure | strategy | | storage | access | Value collection |
+------------+---------------+----------+------------+------------+------------------+
| 2 arrays | Binary search | Sorted | Yes | Key, Index | Yes |
| BST | Binary search | Sorted | No | Key | Yes |
+------------+---------------+----------+------------+------------+------------------+
до примерно перефразируйте, если вам требуется сырая производительность SortedDictionary может быть лучшим выбором. Если Вам требуются меньшие затраты памяти и индексированный поиск SortedList лучше подходит. см. этот вопрос для получения дополнительной информации о том, когда использовать.
вы можете прочитать больше здесь, здесь, здесь, здесь и здесь.
я взломал открытый отражатель, чтобы взглянуть на это, поскольку, кажется, есть немного путаницы о SortedList. Это на самом деле не бинарное дерево поиска, это сортированный (по ключу) массив пар ключ-значение. Существует также TKey[] keys переменная, которая сортируется синхронно с парами ключ-значение и используется для двоичного поиска.
вот некоторый источник (нацеленный на .NET 4.5) для резервного копирования моих утверждений.
частная члены
// Fields
private const int _defaultCapacity = 4;
private int _size;
[NonSerialized]
private object _syncRoot;
private IComparer<TKey> comparer;
private static TKey[] emptyKeys;
private static TValue[] emptyValues;
private KeyList<TKey, TValue> keyList;
private TKey[] keys;
private const int MaxArrayLength = 0x7fefffff;
private ValueList<TKey, TValue> valueList;
private TValue[] values;
private int version;
парам.ctor (IDictionary, IComparer)
public SortedList(IDictionary<TKey, TValue> dictionary, IComparer<TKey> comparer) : this((dictionary != null) ? dictionary.Count : 0, comparer)
{
if (dictionary == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.dictionary);
}
dictionary.Keys.CopyTo(this.keys, 0);
dictionary.Values.CopyTo(this.values, 0);
Array.Sort<TKey, TValue>(this.keys, this.values, comparer);
this._size = dictionary.Count;
}
парам.Add (TKey, TValue) : void
public void Add(TKey key, TValue value)
{
if (key == null)
{
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);
}
int num = Array.BinarySearch<TKey>(this.keys, 0, this._size, key, this.comparer);
if (num >= 0)
{
ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);
}
this.Insert(~num, key, value);
}
парам.RemoveAt (int) : void
public void RemoveAt(int index)
{
if ((index < 0) || (index >= this._size))
{
ThrowHelper.ThrowArgumentOutOfRangeException(ExceptionArgument.index, ExceptionResource.ArgumentOutOfRange_Index);
}
this._size--;
if (index < this._size)
{
Array.Copy(this.keys, index + 1, this.keys, index, this._size - index);
Array.Copy(this.values, index + 1, this.values, index, this._size - index);
}
this.keys[this._size] = default(TKey);
this.values[this._size] = default(TValue);
this.version++;
}
Проверьте страница MSDN для SortedList:
из раздела Примечания:
на
SortedList<(Of <(TKey, TValue>)>)generic class-это двоичное дерево поиска сO(log n)поиск, гдеn- количество элементов в словаре. В этом он похож наSortedDictionary<(Of <(TKey, TValue>)>)универсальный класс. Два класса имеют похожие объектные модели, и оба имеютO(log n)поиск. Где два класса отличаются в использовании памяти и скорости вставки и удаление:
SortedList<(Of <(TKey, TValue>)>)использует меньше памяти, чемSortedDictionary<(Of <(TKey, TValue>)>).
SortedDictionary<(Of <(TKey, TValue>)>)имеет более быстрые операции вставки и удаления для несортированных данных,O(log n)в противоположностьO(n)наSortedList<(Of <(TKey, TValue>)>).если список заполняется все сразу из отсортированных данных,
SortedList<(Of <(TKey, TValue>)>)быстрееSortedDictionary<(Of <(TKey, TValue>)>).
достаточно сказано уже на эту тему, Однако, чтобы все было просто, вот мой взгляд.
отсортированный словарь следует использовать, когда -
- требуются дополнительные операции вставки и удаления.
- данные в un-ordered.
- доступ к ключу достаточно, и доступ к индексу не требуется.
- память не является узким местом.
на другой стороне,Отсортированный Список следует использовать когда ... --1-->
- требуется больше поисков и меньше операций вставки и удаления.
- данные уже отсортированы (если не все, то большинство).
- требуется доступ к индексу.
- память накладные расходы.
надеюсь, что это помогает!!
доступ к индексу (упомянутый здесь) - это практическая разница. Если вам нужно получить доступ к преемнику или предшественнику, вам нужен SortedList. SortedDictionary не может этого сделать, поэтому вы довольно ограничены тем, как вы можете использовать сортировку (first / foreach).