Влияет ли размер набора данных на алгоритм машинного обучения?
Итак, представьте, что у вас есть доступ к достаточным данным (миллионам точек данных для обучения и тестирования) достаточного качества. Пожалуйста, игнорируйте дрейф концепции сейчас и предполагайте, что данные статичны и не меняются со временем. Имеет ли смысл использовать все эти данные с точки зрения качества модели?
мозг и Уэбб (http://www.csse.monash.edu.au / ~webb / Files / BrainWebb99.pdf) включили некоторые результаты экспериментов с различными размерами набора данных. Их проверенные алгоритмы сходятся к некоторой стабильной после тренировки с 16 000 или 32 000 точек данных. Однако, поскольку мы живем в мире больших данных, у нас есть доступ к наборам данных миллионов точек, поэтому документ несколько актуален, но очень устарел.
есть ли какие-либо более недавние исследования о влиянии размеров наборов данных на алгоритмы обучения (наивные Байес, деревья решений, SVM, нейронные сети и т. д.).
- когда алгоритм обучения сходится к определенная стабильная модель, для которой больше данных больше не повышает качество?
- может ли это произойти после 50,000 datapoints, или, может быть, после 200,000 или только после 1,000,000?
- есть правило?
- или, может быть, нет способа для алгоритма сходиться к стабильной модели, к определенному равновесию?
Почему я спрашиваю об этом? Представьте себе систему с ограниченным хранилищем и огромным количеством уникальных моделей (тысячи моделей с их собственный уникальный набор данных) и нет возможности увеличения памяти. Поэтому важно ограничить размер набора данных.
какие-то мысли или исследования по этому поводу?
1 ответов
Я сделал свою магистерскую диссертацию по этому вопросу, так что я знаю довольно много об этом.
в нескольких словах в первой части моей магистерской диссертации я взял некоторые действительно большие наборы данных (~5,000,000 образцов) и протестировал некоторые алгоритмы машинного обучения на них, изучая на разных % набора данных (кривые обучения). 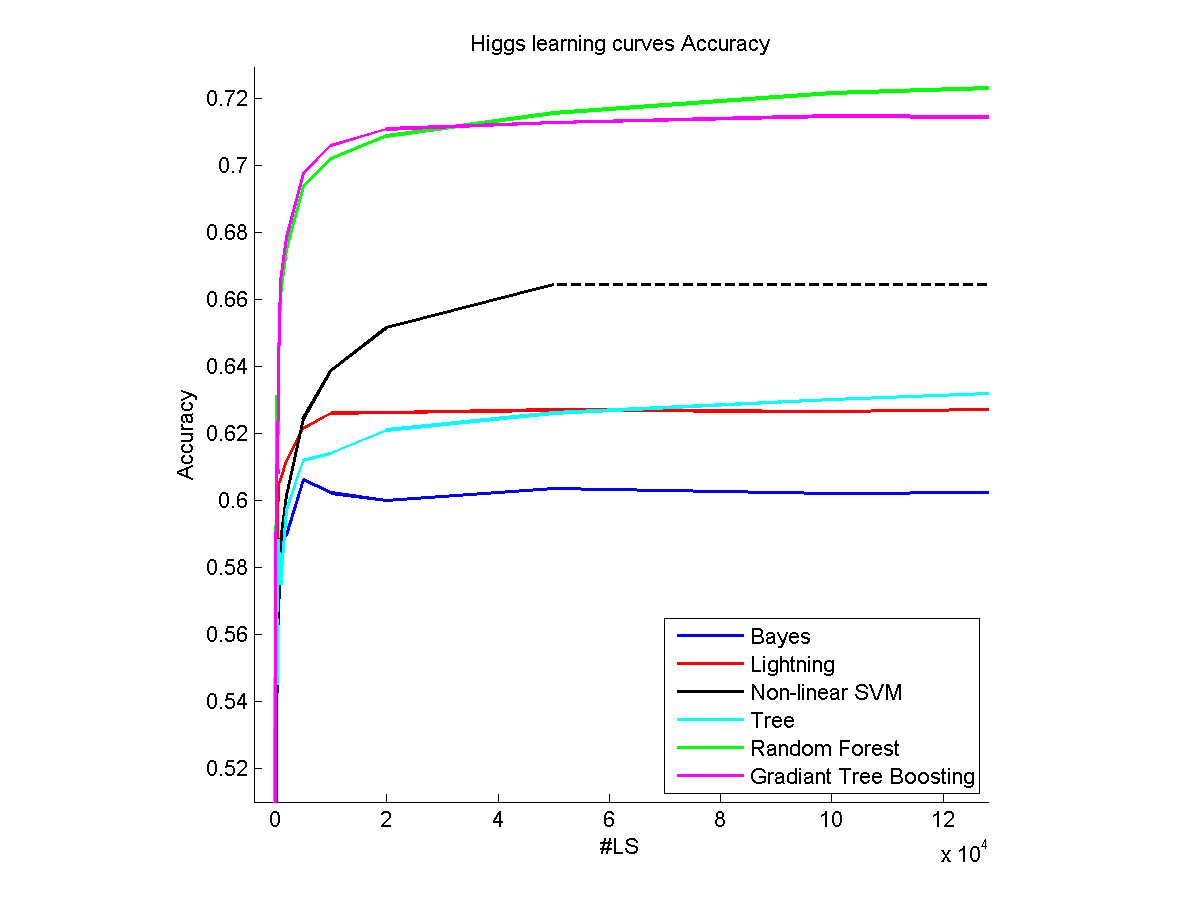
гипотеза, которую я сделал (я использовал scikit-learn в основном), не заключалась в оптимизации параметров, используя параметры по умолчанию для алгоритмов (Я должен был сделать эту гипотезу по практическим причинам, без оптимизации некоторые моделирования заняли уже более 24 часов на кластере).
первое, что следует отметить, это то, что, по сути, каждый метод приведет к плато для определенной части набора данных. Однако вы не можете сделать выводы об эффективном количестве проб, которые он берет для достижения плато, по следующим причинам:
- каждый набор данных отличается, для действительно простого наборы данных они могут дать вам почти все, что они могут предложить с 10 образцами, в то время как некоторые все еще есть что показать после 12000 образцов (см. набор данных Хиггса в моем примере выше).
- количество выборок в наборе данных произвольно, в моей диссертации я тестировал набор данных с неправильными выборками, которые были добавлены только для беспорядка с алгоритмами.
однако мы можем различать два разных типа алгоритмов, которые будут иметь разное поведение : параметрический (Линейный. ,..) и непараметрические (случайный лес ...) модельный. Если плато достигается с непараметрическим, это означает, что остальная часть набора данных "бесполезна". Как вы можете видеть, в то время как метод Lightning очень скоро достигнет плато на моей картине, это не означает, что у набора данных больше ничего не осталось, но это лучшее, что может сделать метод. Вот почему непараметрические методы работают лучше всего, когда модель сложная и могут действительно извлечь выгоду из большого количества обучающая выборка.
Что касается ваших вопросов:
см. выше.
Да, это все зависит от того, что находится внутри набора данных.
для меня единственное эмпирическое правило-идти с перекрестной проверкой. Если вы находитесь в ситуации, в которой вы думаете, что будете использовать 20 000 или 30 000 образцов, вы часто находитесь в случае, когда перекрестная проверка не является проблемой. В моей диссертации я вычислил точность моих методов на тестовом наборе, и когда я не заметил значительного улучшения, я определил количество образцов, необходимых для его получения. Как я уже сказал, Есть некоторые тенденции ,которые вы можете наблюдать (параметрические методы, как правило, насыщаются быстрее, чем непараметрические)
иногда, когда набор данных недостаточно велик, вы можете взять каждую точку данных и все еще иметь возможность для улучшения, если у вас был больший набор данных. В моей диссертации без оптимизации параметров, Cifar-10 dataset вел себя так, даже после 50,000 ни один из моих алгоритмов еще не сходился.
Я бы добавил, что оптимизация параметров алгоритмов оказывает большое влияние на скорость сходимости к плато, но для этого требуется другой шаг перекрестной проверки.
ваше последнее предложение в высокой степени связано с темой моей диссертации, но для меня это было больше связано с памятью и временем, доступным для выполнения задач ML. (Как будто вы покрываете меньше, чем весь набор данных у вас будет меньшее требование к памяти, и это будет быстрее). О том, что концепция "core-sets" может быть действительно интересной для вас.
Я надеюсь, что смогу вам помочь, мне пришлось остановиться, потому что я мог бы снова и снова об этом, но если вам нужны дополнительные разъяснения, я буду рад помочь.