Выбор eps и minpts для DBSCAN (R)?
Я искал ответ на этот вопрос довольно долгое время, поэтому я надеюсь, что кто-то может мне помочь. Я использую dbscan из библиотеки fpc в R. например, я смотрю на набор данных USArrests и использую dbscan на нем следующим образом:
library(fpc)
ds <- dbscan(USArrests,eps=20)
выбор eps был просто методом проб и ошибок в этом случае. Однако мне интересно, есть ли функция или код, доступный для автоматизации выбора лучших eps/minpts. Я знаю, что некоторые книги рекомендуют создавать сюжет kth сортировал расстояние до ближайшего соседа. То есть ось x представляет "точки, отсортированные по расстоянию до ближайшего соседа kth", а ось y представляет "расстояние до ближайшего соседа kth".
этот тип графика полезен для выбора подходящего значения для eps и minpts. Надеюсь, я предоставил достаточно информации, чтобы кто-то мог мне помочь. Я хотел опубликовать фотографию того, что я имел в виду, однако я все еще новичок, поэтому не могу опубликовать изображение просто еще.
4 ответов
нет общего способа выбора minPts. Это зависит от того, что вы желаете найти. Низкий minPts означает, что он будет строить больше кластеров из шума, поэтому не выбирайте его слишком маленьким.
для epsilon существуют различные аспекты. Это снова сводится к выбору того, что работает на этой набор данных, и этой minPts и этой функции расстояния и этой нормализация. Вы можете попробовать сделать гистограмму расстояния knn и выберите" колено " там, но может быть не видно одного или нескольких.
OPTICS является преемником DBSCAN, который не нуждается в параметре epsilon (за исключением соображений производительности с поддержкой индекса, см. Википедию). Это намного приятнее, но я считаю, что это боль для реализации в R, потому что ему нужны расширенные структуры данных (в идеале, дерево индексов данных для ускорения и обновить куча для очереди приоритетов), а R - это матрица оперативный.
наивно можно представить, что оптика одновременно выполняет все значения Epsilon и помещает результаты в кластерную иерархию.
первое, что вам нужно проверить, однако - в значительной степени независимо от любого алгоритма кластеризации, который вы собираетесь использовать, - это убедиться, что у вас есть полезная функция расстояния и соответствующая нормализация данных. Если ваше расстояние ухудшается,нет алгоритм кластеризации будет работать.
одним из распространенных и популярных способов управления параметром epsilon DBSCAN является вычисление графика K-расстояния вашего набора данных. В принципе, вы вычисляете k-ближайших соседей (k-NN) для каждой точки данных, чтобы понять, каково распределение плотности ваших данных для разных k. KNN удобен, потому что это непараметрический метод. Как только вы выбираете minPTS (который сильно зависит от ваших данных), вы фиксируете k к этому значению. Затем вы используете в качестве Эпсилона K-расстояние, соответствующее площади K-расстояние участка (для вашего фиксированного k) с низким уклоном.
MinPts
As Anony-Мусс пояснил, 'низкий minPts означает, что он будет строить больше кластеров из шума, поэтому не выбирайте его слишком маленьким.'.
minPts лучше всего установить экспертом домена, который хорошо понимает данные. К сожалению, во многих случаях мы не знаем знаний о домене, особенно после нормализации данных. Один эвристический подход-использование ln (n), где n - общее количество очков, которое должно быть кластеризованный.
Эпсилон
есть несколько способов определить это:
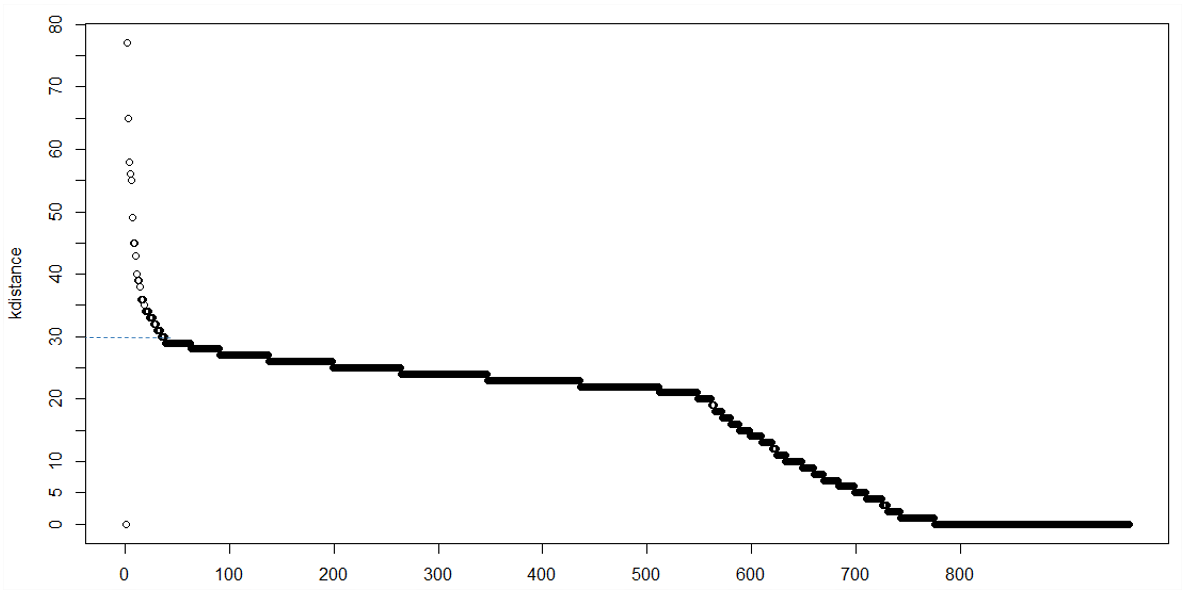
1) k-расстояние участок
в кластеризации с minPts = k мы ожидаем, что основные пинты и K-расстояние пограничных точек находятся в определенном диапазоне, в то время как шумовые точки могут иметь гораздо большее K-расстояние, поэтому мы можем наблюдать a колено точка на графике K-расстояния. Однако иногда может не быть очевидного колена, или может быть несколько колен, что делает ее трудно решить
2) расширения DBSCAN, такие как оптика
оптика производит иерархические кластеры, мы можем извлечь значительные плоские кластеры из иерархических кластеров путем визуального контроля, реализация оптики доступна в модуле Python pyclustering. Один из первоначальных авторов DBSCAN и оптики также предложил автоматический путь извлечь плоские кластеры, где никакое человеческое вмешательство необходимо, для Больше информации вы может читать этой статье.
3) анализ чувствительности
в основном мы хотим выбрать радиус, который способен группировать более по-настоящему регулярные точки (точки, похожие на другие точки), в то же время обнаруживая больше шума (точки выброса). Мы можем нарисовать процент регулярных точек (точки принадлежат кластеру) VS. Эпсилон анализ, где мы устанавливаем различные значения epsilon как ось x, и их соответствующие процент регулярных точек в качестве оси y, и, надеюсь, мы сможем определить сегмент, где процент регулярных точек более чувствителен к значению epsilon, и мы выбираем верхнюю границу значения epsilon в качестве нашего оптимального параметра.
см. эту веб-страницу, раздел 5: http://www.sthda.com/english/wiki/dbscan-density-based-clustering-for-discovering-clusters-in-large-datasets-with-noise-unsupervised-machine-learning
Он дает подробные инструкции о том, как найти Эпсилон. MinPts ... не столько.