Выпуклая оболочка ggplot с использованием данных.таблицы в р
Я нашел хороший пример построения выпуклых форм корпуса с помощью ggplot с ddply здесь: рисование контуров вокруг нескольких групп geom_point с помощью ggplot
Я думал, что попробую что-то подобное--создать что-то вроде диаграммы Эшби--практиковаться с данными.пакет таблицы:
test<-function()
{
library(data.table)
library(ggplot2)
set.seed(1)
здесь я определяю простую таблицу:
dt<-data.table(xdata=runif(15),ydata=runif(15),level=rep(c("a","b","c"),each=5),key="level")
и затем я определяю положение корпуса по уровню:
hulls<-dt[,as.integer(chull(.SD)),by=level]
setnames(hulls,"V1","hcol")
Итак, моя мысль состояла в том, чтобы объединить корпуса с dt, чтобы я мог в конечном итоге манипулировать корпусами, чтобы получить надлежащую форму для ggplot (показано ниже Для справки):
ashby<-ggplot(dt,aes(x=xdata,y=ydata,color=level))+
geom_point()+
geom_line()+
geom_polygon(data=hulls,aes(fill=level))
}
но кажется, что любым способом я пытаюсь объединить корпуса и dt, я получаю ошибку. Например, merge (hulls,dt) создает ошибку, как показано в сноску 1.
кажется, это должно быть просто, и я уверен, что я просто упускаю что-то очевидное. Любое направление на аналогичный пост или мысли о том, как подготовить корпус для ggplot очень признателен. Или если вы думаете, что лучше придерживаться подхода ddply, пожалуйста, дайте мне знать.
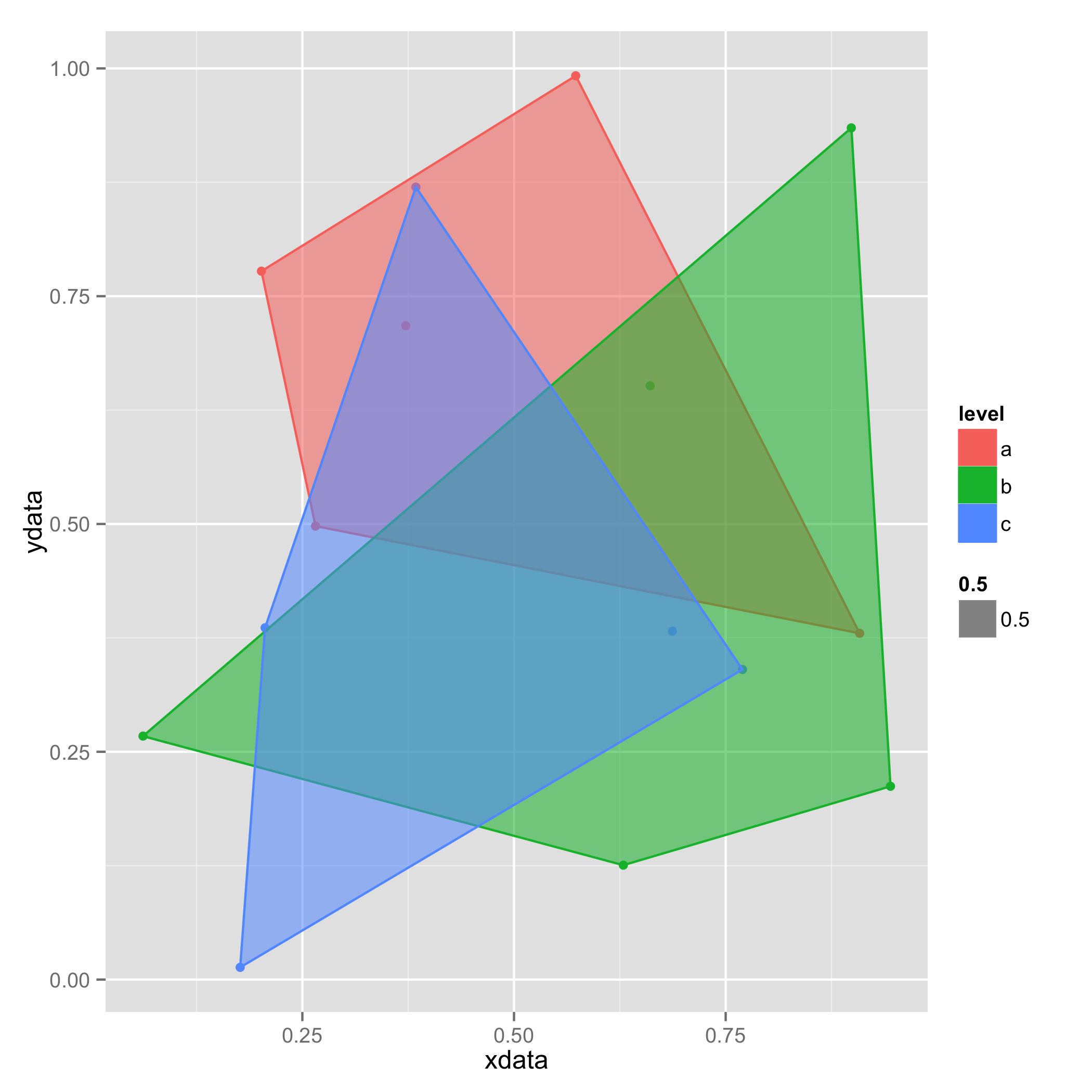
пример нежелательного выхода:
test<-function(){
library(data.table)
library(ggplot2)
dt<-data.table(xdata=runif(15),ydata=runif(15),level=rep(c("a","b","c"),each=5),key="level")
set.seed(1)
hulls<-dt[,as.integer(chull(.SD)),by=level]
setnames(hulls,"V1","hcol")
setkey(dt, 'level') #setting the key seems unneeded
setkey(hulls, 'level')
hulls<-hulls[dt, allow.cartesian = TRUE]
ggplot(dt,aes(x=xdata,y=ydata,color=level))+
geom_point()+
geom_polygon(data=hulls,aes(fill=level))
}
приводит к беспорядку пересекающихся полигонов:
сноска 1:
ошибка в vecseq (f__, len__, if (allow.декартово) NULL else как.integer (max (nrow (x),: результаты объединения в 60 строк; более 15 = max (nrow (x), nrow(i)). Проверять дублировать Ключевые значения в i, каждое из которые присоединяются к одной и той же группе в x снова и снова. Если это нормально, попробуйте включить
jи роняяby(by-without-by) так что j работает для каждая группа, чтобы избежать большого выделения. Если вы уверены, что хотите продолжайте, повторите с allow.cartesian=TRUE. В противном случае, пожалуйста, найдите это сообщение об ошибке в FAQ, Wiki, Stack Overflow и datatable-справка за Советом.
1 ответов
вот что вы хотите сделать. Генерация случайных данных:
library(ggplot2)
library(data.table)
# You have to set the seed _before_ you generate random data, not after
set.seed(1)
dt <- data.table(xdata=runif(15), ydata=runif(15), level=rep(c("a","b","c"), each=5),
key="level")
вот где происходит волшебство:
hulls <- dt[, .SD[chull(xdata, ydata)], by = level]
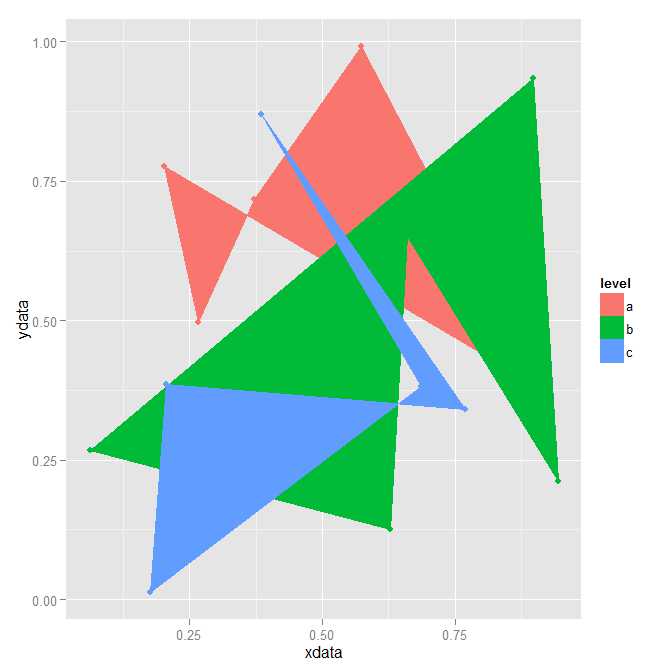
черчение результат:
ggplot(dt,aes(x=xdata,y=ydata,color=level)) +
geom_point() +
geom_polygon(data = hulls,aes(fill=level,alpha = 0.5))
производит
это работает, потому что chull возвращает вектор индексов, которые необходимо выбрать из данных, чтобы сформировать выпуклую оболочку. Затем мы подмножеством каждого отдельного фрейма данных с .SD[...] и data.table соединяет их вместе с помощью level.