Выпуск в обучении скрытой марковской модели и использование для классификации
Мне трудно понять, как использовать Kevin Murphy's HMM toolbox Toolbox. Было бы очень полезно, если бы любой, кто имеет опыт работы с ним, мог прояснить некоторые концептуальные вопросы. Я как-то понял теорию, стоящую за HMM, но это сбивает с толку, Как ее реализовать и упомянуть все настройки параметров.
есть 2 класса, поэтому нам нужно 2 HMMs.
Допустим, векторами обучения являются: class1 O1={ 4 3 5 1 2} и class O_2={ 1 4 3 2 4}.
Теперь система должна классифицировать неизвестную последовательность O3={1 3 2 4 4} как class1 или class2.
- что будет в obsmat0 и obsmat1?
- Как указать / синтаксис для вероятности перехода transmat0 и transmat1?
- какими будут переменные данные в этом случае?
- будет ли количество состояний Q=5, поскольку используются пять уникальных чисел/символов?
- количество выходных символов=5 ?
- как я могу упомянуть вероятности перехода transmat0 и transmat1?
2 ответов
вместо того, чтобы отвечать на каждый отдельный вопрос, Позвольте мне проиллюстрировать, как использовать хмм toolbox С примером -- the пример погоды который обычно используется при введении скрытых моделей Маркова.
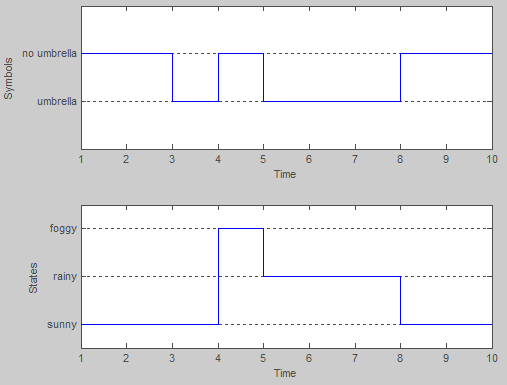
в основном состояниями модели являются три возможных типа погоды: солнечная, дождливая и туманная. В любой день, мы предполагаем, что погода может быть только одно из этих значений. Таким образом, множество состояний HMM:
S = {sunny, rainy, foggy}
однако в этом примере мы не можем наблюдать за погодой напрямую (по-видимому, мы заперты в подвале!). Вместо этого единственное доказательство, которое у нас есть, это то, носит ли человек, который проверяет вас каждый день, зонтик или нет. В терминологии Хм, это дискретные наблюдения:
x = {umbrella, no umbrella}
модель хмм характеризуется тремя вещами:
- предыдущие вероятности: вектор вероятностей нахождения в первом состоянии последовательности.
- в переходная задача: матрица, описывающая вероятности перехода из одного состояния погоды в другое.
- проблема выбросов: матрица, описывающая вероятности наблюдения за выходом (зонтичным или нет) при заданном состоянии (погоде).
Далее нам либо дают эти вероятности, либо мы должны изучить их из набора тренировок. Как только это будет сделано, мы можем сделать рассуждения, такие как вычисление вероятности последовательности наблюдений относительно модели HMM (или группы модели, и выбрать наиболее вероятный)...
1) известные параметры модели
вот пример кода, который показывает, как заполнить существующие вероятностей для построения модели:
Q = 3; %# number of states (sun,rain,fog)
O = 2; %# number of discrete observations (umbrella, no umbrella)
%# prior probabilities
prior = [1 0 0];
%# state transition matrix (1: sun, 2: rain, 3:fog)
A = [0.8 0.05 0.15; 0.2 0.6 0.2; 0.2 0.3 0.5];
%# observation emission matrix (1: umbrella, 2: no umbrella)
B = [0.1 0.9; 0.8 0.2; 0.3 0.7];
затем мы можем попробовать кучу последовательностей из этой модели:
num = 20; %# 20 sequences
T = 10; %# each of length 10 (days)
[seqs,states] = dhmm_sample(prior, A, B, num, T);
например, 5-й пример:
>> seqs(5,:) %# observation sequence
ans =
2 2 1 2 1 1 1 2 2 2
>> states(5,:) %# hidden states sequence
ans =
1 1 1 3 2 2 2 1 1 1
мы можем оценить лог-вероятность последовательности:
dhmm_logprob(seqs(5,:), prior, A, B)
dhmm_logprob_path(prior, A, B, states(5,:))
или вычислить путь Витерби (наиболее вероятный последовательность состояний):
vPath = viterbi_path(prior, A, multinomial_prob(seqs(5,:),B))
2) неизвестные параметры модели
обучение выполняется с использованием алгоритма EM, и лучше всего сделать с set наблюдения последовательности.
продолжая на том же примере, мы можем использовать сгенерированные данные выше, чтобы обучить новую модель и сравнить ее с оригиналом:
%# we start with a randomly initialized model
prior_hat = normalise(rand(Q,1));
A_hat = mk_stochastic(rand(Q,Q));
B_hat = mk_stochastic(rand(Q,O));
%# learn from data by performing many iterations of EM
[LL,prior_hat,A_hat,B_hat] = dhmm_em(seqs, prior_hat,A_hat,B_hat, 'max_iter',50);
%# plot learning curve
plot(LL), xlabel('iterations'), ylabel('log likelihood'), grid on
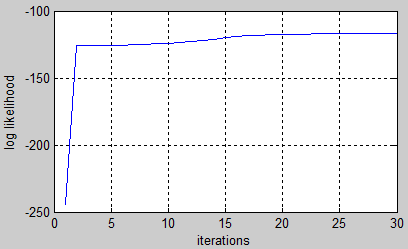
имейте в виду, что порядок Штатов не должен совпадать. Вот почему нам нужно переставить состояния, прежде чем сравнивать две модели. В этом примере обученная модель выглядит близко к исходной:
>> p = [2 3 1]; %# states permutation
>> prior, prior_hat(p)
prior =
1 0 0
ans =
0.97401
7.5499e-005
0.02591
>> A, A_hat(p,p)
A =
0.8 0.05 0.15
0.2 0.6 0.2
0.2 0.3 0.5
ans =
0.75967 0.05898 0.18135
0.037482 0.77118 0.19134
0.22003 0.53381 0.24616
>> B, B_hat(p,[1 2])
B =
0.1 0.9
0.8 0.2
0.3 0.7
ans =
0.11237 0.88763
0.72839 0.27161
0.25889 0.74111
есть больше вещей, которые вы можете сделать со скрытыми марковскими моделями, такими как классификация или распознавание образов. Вы бы иметь различные наборы рекомендация последовательностей, принадлежащих к разным классам. Вы начинаете с обучения модели для каждого набора. Затем дается новая последовательность наблюдения, можно классифицировать по ЕСН вероятность относительно каждой модели, и предсказать модель с наибольшей логарифмической вероятностью.
argmax[ log P(X|model_i) ] over all model_i
Я не использую упомянутый вами набор инструментов, но я использую HTK. Существует книга, которая очень четко описывает функцию HTK, доступная бесплатно
http://htk.eng.cam.ac.uk/docs/docs.shtml
вводные главы могут помочь вам понять.
У меня может быть быстрая попытка ответить #4 в вашем списке. . . Количество излучающих состояний связано с длиной и сложностью векторов объектов. Однако, это, конечно, не обязательно равна длине массива векторов объектов, так как каждое излучающее состояние может иметь вероятность перехода обратно в себя или даже обратно в предыдущее состояние в зависимости от архитектуры. Я также не уверен, что значение, которое вы даете, включает в себя не испускающие состояния в начале и конце хмм, но их также нужно учитывать. Выбор количества состояний часто сводится к пробам и ошибкам.
удачи!