Что и где стопка и куча?
книги по языку программирования объясняют, что типы значений создаются на стек, и ссылочные типы создаются на кучу, не объясняя, что это за две вещи. Я не читал четкого объяснения этому. Я понимаю, что стек есть. Но,
- где и что они (физически в памяти реального компьютера)?
- в какой степени они контролируются ОС или языком время выполнения?
- какова их область применения?
- что определяет размер каждого из них?
- что делает быстрее?
25 ответов
стек-это память, выделенная в качестве пустого места для потока выполнения. При вызове функции блок зарезервирован в верхней части стека для локальных переменных и некоторых данных бухгалтерского учета. Когда эта функция возвращается, блок становится неиспользуемым и может использоваться при следующем вызове функции. Стек всегда зарезервирован в порядке LIFO (последний в первом); последний зарезервированный блок всегда следующий блок, который нужно освободить. Это делает его действительно просто отслеживать стек; освобождение блока из стека-это не что иное, как настройка одного указателя.
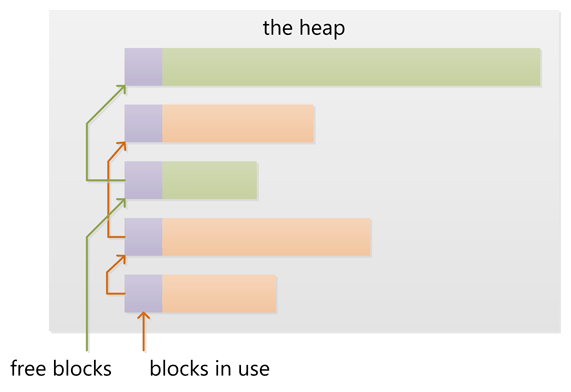
куча-это память, выделенная для динамического распределения. В отличие от стека, нет принудительного шаблона для выделения и освобождения блоков из кучи; вы можете выделить блок в любое время и освободить его в любое время. Это значительно усложняет отслеживание того, какие части кучи выделяются или освобождаются в любой момент времени; для настройки доступно множество пользовательских распределителей кучи производительность кучи для различных шаблонов использования.
каждый поток получает стек, в то время как обычно для приложения есть только одна куча (хотя не редкость иметь несколько куч для разных типов распределения).
отвечаем на вопросы:
в какой степени они контролируются ОС или языковой средой выполнения?
ОС выделяет стек для каждого потока системного уровня, когда создается поток. Обычно ОС вызывается языковой средой выполнения для выделения кучи для приложения.
какова их область применения?
стек присоединен к потоку, поэтому, когда поток выходит из стека, он восстанавливается. Куча обычно выделяется при запуске приложения средой выполнения и восстанавливается при выходе приложения (технически процесса).
что определяет размер каждый из них?
размер стека устанавливается при создании потока. Размер кучи устанавливается при запуске приложения, но может увеличиваться по мере необходимости (распределитель запрашивает больше памяти из операционной системы).
что делает быстрее?
стек быстрее, потому что шаблон доступа делает тривиальным выделение и освобождение памяти из него (указатель / целое число просто увеличивается или уменьшено), в то время как куча имеет гораздо более сложную бухгалтерию, связанную с распределением или освобождением. Кроме того, каждый байт в стеке, как правило, используется повторно очень часто, что означает, что он, как правило, сопоставляется с кэшем процессора, что делает его очень быстрым. Еще один удар по производительности для кучи заключается в том, что куча, будучи в основном глобальным ресурсом, обычно должна быть многопоточной, т. е. каждое выделение и освобождение должны быть - как правило-синхронизированы со "всеми" другими доступами к куче в программа.
наглядная демонстрация:

Источник изображения:vikashazrati.wordpress.com
стопка:
- хранится в ОЗУ компьютера так же, как куча.
- переменные, созданные в стеке, выйдут из области действия и будут автоматически освобождены.
- гораздо быстрее выделять по сравнению с переменными в куче.
- реализовано с фактической структурой данных стека.
- хранит локальные данные, обратные адреса, используемые для передачи параметров.
- может быть переполнение стека, когда слишком много используется стек (в основном из бесконечной или слишком глубокой рекурсии, очень больших распределений).
- данные, созданные в стеке, могут использоваться без указателей.
- вы бы использовали стек, если бы точно знали, сколько данных вам нужно выделить до времени компиляции, и он не слишком велик.
- обычно максимальный размер уже определен при запуске программы.
кучи:
- хранится в ОЗУ компьютера как и стопка.
- в C++ переменные в куче должны быть уничтожены вручную и никогда не выпадать из области видимости. Данные освобождаются с помощью
delete,delete[]илиfree. - медленнее выделять по сравнению с переменными в стеке.
- используется по требованию для выделения блока данных для использования программой.
- может иметь фрагментацию, когда есть много распределений и освобождений.
- в C++ или C, данные, созданные в куче будет указываться указателями и выделяться с помощью
newилиmallocсоответственно. - может иметь сбои выделения, если запрашивается выделение слишком большого буфера.
- вы бы использовали кучу, если вы точно не знаете, сколько данных вам понадобится во время выполнения или если вам нужно выделить много данных.
- ответственный за утечки памяти.
пример:
int foo()
{
char *pBuffer; //<--nothing allocated yet (excluding the pointer itself, which is allocated here on the stack).
bool b = true; // Allocated on the stack.
if(b)
{
//Create 500 bytes on the stack
char buffer[500];
//Create 500 bytes on the heap
pBuffer = new char[500];
}//<-- buffer is deallocated here, pBuffer is not
}//<--- oops there's a memory leak, I should have called delete[] pBuffer;
наиболее важным моментом является то, что куча и стек являются общими терминами для способов выделения памяти. Они могут быть реализованы различными способами, и термины применимы к основным понятиям.
-
в стопке элементов элементы сидят друг на друге в том порядке, в котором они были размещены там, и вы можете удалить только верхний (не опрокидывая все это).

простота стека заключается в том, что вы делаете не нужно поддерживать таблицу, содержащую запись каждого раздела выделенной памяти; единственная информация о состоянии, которая вам нужна, - это один указатель на конец стека. Чтобы выделить и отменить выделение, вы просто увеличиваете и уменьшаете этот единственный указатель. Примечание: стек иногда может быть реализован, чтобы начать в верхней части раздела памяти и расширяться вниз, а не расти вверх.
-
в куче нет особого порядка того, как размещаются элементы. Вы может достигать и удалять элементы в любом порядке, потому что нет четкого верхний пункт.

выделение кучи требует ведения полной записи о том, какая память выделена, а какая нет, а также некоторого обслуживания накладных расходов для уменьшения фрагментации, поиска смежных сегментов памяти, достаточно больших, чтобы соответствовать запрошенному размеру, и так далее. Память может быть освобождена в любое время, оставляя свободное пространство. Иногда распределитель памяти выполняет такие задачи обслуживания, как дефрагментация памяти путем перемещения выделенной памяти или сбор мусора-идентификация во время выполнения, когда память больше не находится в области и ее освобождение.
эти изображения должны выполнять довольно хорошую работу по описанию двух способов выделения и освобождения памяти в стеке и куче. Ням!
-
в какой степени они контролируются ОС или языковой средой выполнения?
Как уже упоминалось, куча и стек являются общими терминами и могут реализовываться многими способами. Компьютерные программы обычно имеют стек под названием стек вызовов который хранит информацию, относящуюся к текущей функции, такую как указатель на ту функцию, из которой она была вызвана, и любые локальные переменные. Поскольку функции вызывают другие функции, а затем возвращаются, стек растет и сжимается, чтобы удерживать информацию из функций дальше по стеку вызовов. Программа на самом деле не имеет контроля над временем выполнения; это определяется программированием язык, ОС и даже архитектура системы.
куча-это общий термин, используемый для любой памяти, которая распределяется динамически и случайным образом, т. е. вышел из строя. Память, как правило, выделяется ОС, с приложением, вызывающим функции API для этого выделения. Существует довольно много накладных расходов, необходимых для управления динамически распределенной памятью, которая обычно обрабатывается ОС.
-
какова их область применения?
стек вызовов такая концепция низкого уровня, что она не относится к "области" в смысле программирования. Если вы разберете некоторый код, вы увидите относительные ссылки стиля указателя на части стека, но что касается языка более высокого уровня, язык накладывает свои собственные правила области. Однако одним из важных аспектов стека является то, что как только функция возвращается, все локальное для этой функции немедленно освобождается из стека. Это работает так, как вы ожидаете, что это сработает, учитывая, как ваш языки программирования работают. В куче, это также трудно определить. Область-это все, что доступно ОС, но ваш язык программирования, вероятно, добавляет свои правила о том, что такое "область" в вашем приложении. Архитектура процессора и ОС используют виртуальную адресацию, которую процессор переводит на физические адреса, а также ошибки страниц и т. д. Они отслеживают, какие страницы принадлежат каким приложениям. Вам никогда не нужно беспокоиться об этом, потому что вы просто используете какой бы метод ни использовал ваш язык программирования для выделения и освобождения памяти, а также проверки ошибок (если выделение/освобождение по какой-либо причине не удается).
-
Что определяет размер каждого из них?
опять же, это зависит от языка, компилятора, операционной системы и архитектуры. Стек обычно предварительно выделяется, потому что по определению он должен быть непрерывной памятью (подробнее об этом в последнем абзаце). Компилятор языка или ОС определяют его размер. Вы не храните огромные куски данных в стеке, поэтому он будет достаточно большим, чтобы его никогда не использовать полностью, за исключением случаев нежелательной бесконечной рекурсии (следовательно, "переполнения стека") или других необычных программных решений.
куча-это общий термин для всего, что может быть выделен динамически. В зависимости от того, как вы смотрите на него, он постоянно меняет размер. В современных процессорах и операционных системах точный способ его работы очень абстрактен, поэтому вы обычно не нужно много беспокоиться о том, как это работает в глубине души, за исключением того, что (в языках, где это позволяет вам) вы не должны использовать память, которую вы еще не выделили, или память, которую вы освободили.
-
Что делает быстрее?
стек быстрее, потому что вся свободная память всегда непрерывен. Нет необходимости поддерживать список всех сегментов свободной памяти, только один указатель на текущую верхнюю часть стека. Компиляторы обычно хранят этот указатель в специальном, быстро!--53-->зарегистрироваться для этой цели. Более того, последующие операции над стеком обычно сосредоточены в очень близких областях памяти, что на очень низком уровне хорошо для оптимизации процессором на-умирают кэши.
(Я перенес этот ответ из другого вопроса, который был более или менее Боян это.)
ответ на ваш вопрос специфичен для реализации и может варьироваться в зависимости от компиляторов и процессорных архитектур. Однако вот упрощенное объяснение.
- и стек, и куча-это области памяти, выделенные из базовой операционной системы (часто виртуальная память, которая по требованию сопоставляется с физической памятью).
- в многопоточном среда каждый поток будет иметь свой собственный полностью независимый стек, но они будут делиться кучей. Параллельный доступ должен управляться в куче и невозможен в стеке.
кучу
- куча содержит связанный список использованных и свободных блоков. Новые распределения в куче (by
newилиmalloc) удовлетворяются путем создания подходящего блока из одного из свободных блоков. Это требует обновления списка блоков в куче. Этот мета-информации о блоках в куче также хранится в куче часто на небольшой площади перед каждым блоком. - по мере роста кучи новые блоки часто выделяются из более низких адресов в более высокие адреса. Таким образом, вы можете думать о куче как кучу блоков памяти, которые увеличиваются в размере по мере выделения памяти. Если куча слишком мала для выделения, размер часто может быть увеличен путем получения большего объема памяти из базового операционная система.
- выделение и освобождение многих небольших блоков может оставить кучу в состоянии, когда есть много небольших свободных блоков, перемежающихся между используемыми блоками. Запрос на выделение большого блока может завершиться неудачей, поскольку ни один из свободных блоков не является достаточно большим для удовлетворения запроса на выделение, даже если общий размер свободных блоков может быть достаточно большим. Это называется фрагментации кучи.
- когда используется блок, который находится рядом с свободный блок освобождается новый свободный блок может быть объединен с соседним свободным блоком, чтобы создать больший свободный блок, эффективно уменьшая фрагментацию кучи.
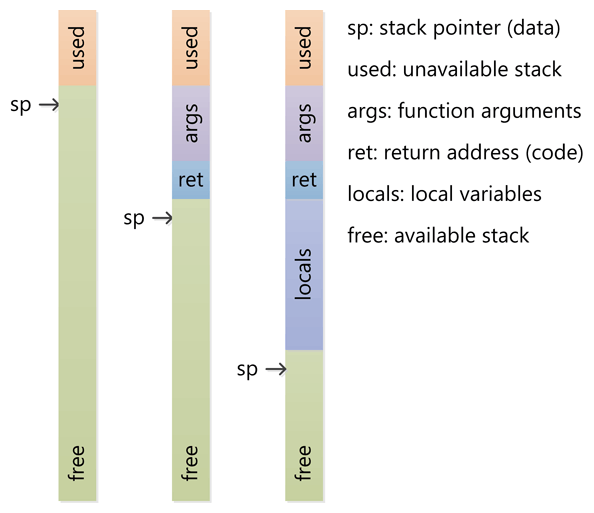
стек
- стек часто работает в тесном тандеме со специальным регистром на CPU с именем указатель стека. Первоначально указатель стека указывает на верхнюю часть стека (самый высокий адрес в стеке).
- в Процессор имеет специальные инструкции для толкал значения в стеке и выталкивание их обратно из стека. Каждый пуш сохраняет значение в текущее положение указателя стека и уменьшает указатель стека. А поп возвращает значение, на которое указывает указатель стека, а затем увеличивает указатель стека (не путать с тем, что добавлять значение на стеке уменьшается стек указатель и удаление значение увеличение его. Помните, что стек растет вниз). Сохраненные и извлеченные значения являются значениями регистров ЦП.
- когда функция вызывается CPU использует специальные инструкции, которые нажимают текущий инструкция указатель, т. е. адрес из кода, выполняющегося в стеке. Затем CPU переходит к функции, установив указатель на адрес функции. Позже, когда функция возвращается, старый указатель инструкции выскакивает из стека и выполнение возобновляется в коде сразу после вызова функции.
- при вводе функции указатель стека уменьшается, чтобы выделить больше места в стеке для локальных (автоматических) переменных. Если функция имеет одну локальную 32-разрядную переменную, в стеке выделяются четыре байта. Когда функция возвращается, указатель стека перемещается назад, чтобы освободить выделенную область.
- если a функция имеет параметры, они помещаются в стек перед вызовом функции. Затем код в функции может перемещаться по стеку из текущего указателя стека, чтобы найти эти значения.
- вызовы функций вложенности работают как шарм. Каждый новый вызов будет выделять параметры функции, обратный адрес и пространство для локальных переменных и эти записи активации!--19--> смогите быть штабелировано для вложенных вызовов и расслабиться в правильный путь, когда функции возвращаться.
- поскольку стек является ограниченным блоком памяти, вы можете вызвать переполнение стека вызывая слишком много вложенных функций и / или выделяя слишком много места для локальных переменных. Часто область памяти, используемая для стека, настроена таким образом, что запись ниже нижнего (самого низкого адреса) стека вызовет ловушку или исключение в ЦП. Это исключительное условие может быть поймано средой выполнения и преобразовано в какое-то переполнение стека исключение.
функция может быть выделена в куче, вместо стека?
нет, записи активации для функций (т. е. локальных или автоматических переменных) выделяются в стеке, который используется не только для хранения этих переменных, но и для отслеживания вложенных вызовов функций.
управляемой куче действительно до среды. C использует malloc и C++ использует new, но и многие другие языки имеют сбор мусора.
однако стек является более низкоуровневой функцией, тесно связанной с архитектурой процессора. Увеличение кучи, когда недостаточно места, не слишком сложно, так как она может быть реализована в вызове библиотеки, который обрабатывает кучу. Однако рост стека часто невозможен, поскольку переполнение стека обнаруживается только тогда, когда слишком поздно; и выключение потока выполнения является единственным жизнеспособным вариантом.
в следующем коде C#
public void Method1()
{
int i = 4;
int y = 2;
class1 cls1 = new class1();
}
вот как управляется память
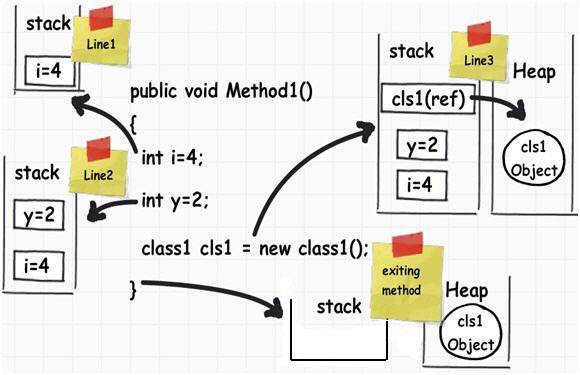
Local Variables это должно длиться только до тех пор, пока вызов функции идет в стеке. Куча используется для переменных, время жизни которых мы не знаем заранее, но мы ожидаем, что они продлятся некоторое время. В большинстве языков важно знать во время компиляции, насколько велика переменная, если мы хотим сохранить ее в стеке.
объекты (которые различаются в размер по мере их обновления) идут в кучу, потому что мы не знаем во время создания, как долго они будут длиться. Во многих языках куча-это мусор, собранный для поиска объектов (таких как объект cls1), которые больше не имеют ссылок.
в Java большинство объектов идут непосредственно в кучу. В таких языках, как C / C++, структуры и классы часто могут оставаться в стеке, когда вы не имеете дело с указателями.
больше информации можно найти здесь:
разница между распределением памяти стека и кучи " timmurphy.org
и здесь:
создание объектов в стеке и куче
эта статья является источником изображения выше:шесть важных концепций .NET: стек, куча, типы значений, ссылочные типы, бокс и распаковка-CodeProject
но учтите, что он может содержать некоторые неточности.
Стек При вызове функции аргументы этой функции плюс некоторые другие накладные расходы помещаются в стек. Некоторая информация (например, куда идти при возврате) также хранится там. Когда вы объявляете переменную внутри функции, эта переменная также выделяется на стеке.
освобождение стека довольно просто, потому что вы всегда освобождаете в обратном порядке, в котором вы выделяете. Stack stuff добавляется при вводе функций, соответствующих данным удаляется при выходе из них. Это означает, что вы склонны оставаться в небольшой области стека, если вы не вызываете множество функций, которые вызывают множество других функций (или создают рекурсивное решение).
Кучу Куча-это общее имя для того, куда вы помещаете данные, которые вы создаете на лету. Если вы не знаете, сколько космических кораблей собирается создать ваша программа, вы, скорее всего, будете использовать новый (или malloc или эквивалентный) оператор для создания каждого космического корабля. Этот распределение будет оставаться некоторое время, поэтому, вероятно, мы освободим вещи в другом порядке, чем мы их создали.
таким образом, куча намного сложнее, потому что в конечном итоге есть области памяти, которые не используются, чередуются с кусками, которые - память фрагментируется. Найти свободную память нужного размера-трудная задача. Вот почему следует избегать кучи (хотя это все еще часто используемый.)
реализация Реализация как стека, так и кучи обычно сводится к среде выполнения / ОС. Часто игры и другие приложения, которые имеют решающее значение для производительности, создают свои собственные решения для памяти, которые захватывают большой кусок памяти из кучи, а затем распределяют его внутри, чтобы не полагаться на ОС для памяти.
это практично только в том случае, если использование памяти сильно отличается от нормы - i.e для игр, где вы загружаете уровень в один огромный операция и может выбросить всю партию в другой огромной операции.
физическое расположение в памяти Это менее актуально, чем вы думаете из-за технологии, которая называется Виртуальный что заставляет вашу программу думать, что у вас есть доступ к определенному адресу, где физические данные находятся где-то еще (даже на жестком диске!). Адреса, которые вы получаете для стека, увеличиваются по мере углубления дерева вызовов. Адреса для кучи непредсказуемый (i.e implimentation specific) и откровенно не важно.
разъяснить ответ имеет неверную информацию (Томас исправлен его ответ после комментариев, круто :)). Другие ответы просто избегают объяснения того, что означает статическое распределение. Поэтому я объясню три основные формы распределения и как они обычно связаны с кучей, стеком и сегментом данных ниже. Я также покажу несколько примеров на C / C++ и Python, чтобы помочь людям понять.
"статические" (АКА статически выделенные) переменные не выделяются в стеке. Не предполагайте так-многие люди делают это только потому, что "статический" звучит очень похоже на "стек". На самом деле они не существуют ни в стеке, ни в куче. Являются частью того, что называется сегмент данных.
однако, как правило, лучше рассмотреть "область" и "продолжительность жизни "вместо " стека"и " кучи".
область относится к тому, какие части кода могут получить доступ к переменной. Обычно мы думаем о местные объем (может быть доступен только текущей функцией) против глобальный масштаб (можно получить доступ в любом месте), хотя область может стать намного сложнее.
Lifetime относится к тому, когда переменная выделяется и освобождается во время выполнения программы. Обычно мы думаем о статического распределения (переменная будет сохраняться в течение всей продолжительности программы, что делает ее полезной для хранения одной и той же информации в нескольких вызовах функций) против автоматическое распределение (переменная сохраняется только во время одного вызова функции, что делает ее полезной для хранения информации, которая используется только во время вашей функции и может быть отброшена после завершения) по сравнению с динамическое выделение (переменные, длительность которых определяется во время выполнения, а не время компиляции, как статическое или автоматическое).
хотя большинство компиляторов и интерпретаторов реализуют это поведение аналогично с точки зрения использования стеков, куч и т. д компилятор может иногда нарушать эти соглашения, если он хочет, пока поведение является правильным. Например, из-за оптимизации локальная переменная может существовать только в регистре или быть полностью удалена, даже если большинство локальных переменных существует в стеке. Как было указано в нескольких комментариях, вы можете реализовать компилятор, который даже не использует стек или кучу, а вместо этого некоторые другие механизмы хранения (редко, так как стеки и кучи отлично подходят для этого).
Я представьте простой аннотированный код C, чтобы проиллюстрировать все это. Лучший способ научиться-запустить программу под отладчиком и наблюдать за поведением. Если вы предпочитаете читать python, перейдите к концу ответа:)
// Statically allocated in the data segment when the program/DLL is first loaded
// Deallocated when the program/DLL exits
// scope - can be accessed from anywhere in the code
int someGlobalVariable;
// Statically allocated in the data segment when the program is first loaded
// Deallocated when the program/DLL exits
// scope - can be accessed from anywhere in this particular code file
static int someStaticVariable;
// "someArgument" is allocated on the stack each time MyFunction is called
// "someArgument" is deallocated when MyFunction returns
// scope - can be accessed only within MyFunction()
void MyFunction(int someArgument) {
// Statically allocated in the data segment when the program is first loaded
// Deallocated when the program/DLL exits
// scope - can be accessed only within MyFunction()
static int someLocalStaticVariable;
// Allocated on the stack each time MyFunction is called
// Deallocated when MyFunction returns
// scope - can be accessed only within MyFunction()
int someLocalVariable;
// A *pointer* is allocated on the stack each time MyFunction is called
// This pointer is deallocated when MyFunction returns
// scope - the pointer can be accessed only within MyFunction()
int* someDynamicVariable;
// This line causes space for an integer to be allocated in the heap
// when this line is executed. Note this is not at the beginning of
// the call to MyFunction(), like the automatic variables
// scope - only code within MyFunction() can access this space
// *through this particular variable*.
// However, if you pass the address somewhere else, that code
// can access it too
someDynamicVariable = new int;
// This line deallocates the space for the integer in the heap.
// If we did not write it, the memory would be "leaked".
// Note a fundamental difference between the stack and heap
// the heap must be managed. The stack is managed for us.
delete someDynamicVariable;
// In other cases, instead of deallocating this heap space you
// might store the address somewhere more permanent to use later.
// Some languages even take care of deallocation for you... but
// always it needs to be taken care of at runtime by some mechanism.
// When the function returns, someArgument, someLocalVariable
// and the pointer someDynamicVariable are deallocated.
// The space pointed to by someDynamicVariable was already
// deallocated prior to returning.
return;
}
// Note that someGlobalVariable, someStaticVariable and
// someLocalStaticVariable continue to exist, and are not
// deallocated until the program exits.
особенно ярким примером того, почему важно различать время жизни и область, является то, что переменная может иметь локальную область, но статическое время жизни - например, "someLocalStaticVariable" в примере кода выше. Такие переменные могут сделать наше общее но неформальные привычки именования очень сбивают с толку. Например, когда мы говорим "местные "мы обычно имеем в виду"локально ограниченная автоматически выделенная переменная "и когда мы говорим глобальный, мы обычно имеем в виду"глобально ограниченная статически выделенная переменная". К сожалению, когда дело доходит до таких вещей, как "область действия файла статически выделенные переменные " многие просто говорят... "да???".
некоторые из вариантов синтаксиса в C / C++ усугубите эту проблему - например, многие люди думают, что глобальные переменные не являются "статическими" из-за синтаксиса, показанного ниже.
int var1; // Has global scope and static allocation
static int var2; // Has file scope and static allocation
int main() {return 0;}
обратите внимание, что размещение ключевого слова "static" в объявлении выше предотвращает глобальную область var2. Тем не менее, глобальный var1 имеет статическое распределение. Это не интуитивно! По этой причине я стараюсь никогда не использовать слово "статический" при описании области, а вместо этого говорю что-то вроде "file" или "file limited" scope. Однако много людей используют фраза "static" или "static scope" для описания переменной, к которой можно получить доступ только из одного файла кода. В контексте lifetime "static"всегда означает, что переменная выделяется при запуске программы и освобождается при выходе программы.
некоторые люди считают эти понятия специфичными для C / C++. Это не так. Например, приведенный ниже пример Python иллюстрирует все три типа распределения (в интерпретируемых языках возможны некоторые тонкие различия, которые я не войдет сюда).
from datetime import datetime
class Animal:
_FavoriteFood = 'Undefined' # _FavoriteFood is statically allocated
def PetAnimal(self):
curTime = datetime.time(datetime.now()) # curTime is automatically allocatedion
print("Thank you for petting me. But it's " + str(curTime) + ", you should feed me. My favorite food is " + self._FavoriteFood)
class Cat(Animal):
_FavoriteFood = 'tuna' # Note since we override, Cat class has its own statically allocated _FavoriteFood variable, different from Animal's
class Dog(Animal):
_FavoriteFood = 'steak' # Likewise, the Dog class gets its own static variable. Important to note - this one static variable is shared among all instances of Dog, hence it is not dynamic!
if __name__ == "__main__":
whiskers = Cat() # Dynamically allocated
fido = Dog() # Dynamically allocated
rinTinTin = Dog() # Dynamically allocated
whiskers.PetAnimal()
fido.PetAnimal()
rinTinTin.PetAnimal()
Dog._FavoriteFood = 'milkbones'
whiskers.PetAnimal()
fido.PetAnimal()
rinTinTin.PetAnimal()
# Output is:
# Thank you for petting me. But it's 13:05:02.255000, you should feed me. My favorite food is tuna
# Thank you for petting me. But it's 13:05:02.255000, you should feed me. My favorite food is steak
# Thank you for petting me. But it's 13:05:02.255000, you should feed me. My favorite food is steak
# Thank you for petting me. But it's 13:05:02.255000, you should feed me. My favorite food is tuna
# Thank you for petting me. But it's 13:05:02.255000, you should feed me. My favorite food is milkbones
# Thank you for petting me. But it's 13:05:02.256000, you should feed me. My favorite food is milkbones
другие ответили на широкие штрихи довольно хорошо, поэтому я добавлю несколько деталей.
стек и куча не должны быть единственными. Распространенная ситуация, в которой у вас есть более одного стека, если у вас есть более одного потока в процессе. В этом случае каждый поток имеет свой собственный стек. Вы также можете иметь более одной кучи, например, некоторые конфигурации DLL могут привести к выделению разных библиотек DLL из разных куч, поэтому обычно это плохая идея освободите память, выделенную другой библиотекой.
В C вы можете получить преимущество распределения переменной длины с помощью alloca, который выделяет в стеке, в отличие от alloc, который выделяет в куче. Эта память не выдержит вашего оператора return, но она полезна для скретч-буфера.
создание огромного временного буфера в Windows, который вы не используете, не является бесплатным. Это потому, что компилятор будет генерировать цикл зондирования стека, который вызывается каждый раз, когда ваша функция вводится, чтобы убедиться, что стек существует (потому что Windows использует одну страницу защиты в конце стека, чтобы определить, когда ему нужно увеличить стек. Если вы получаете доступ к памяти более одной страницы из конца стека, вы потерпите крах). Пример:
void myfunction()
{
char big[10000000];
// Do something that only uses for first 1K of big 99% of the time.
}
другие непосредственно ответили на ваш вопрос, но при попытке понять стек и кучу, я думаю, что полезно рассмотреть макет памяти традиционного процесса UNIX (без потоков и mmap()на основе распределителей). The Управление Памятью Глоссарий веб-страница имеет диаграмму этого макета памяти.
стек и куча традиционно расположены на противоположных концах виртуального адресного пространства процесса. Стек растет автоматически при доступе, до размера, установленного ядром (который можно настроить с помощью setrlimit(RLIMIT_STACK, ...)). Куча растет, когда распределитель памяти вызывает brk() или sbrk() системный вызов, отображение большего количества страниц физической памяти в виртуальное адресное пространство процесса.
в системах без виртуальной памяти, таких как некоторые встроенные системы, часто применяется один и тот же базовый макет, за исключением стека и кучи фиксированного размера. Однако, в других врезанных системах (как те основанные на микроконтроллерах пик микрочипа), программный стек-это отдельный блок памяти, который не адресуется инструкциями по перемещению данных и может быть изменен или прочитан только косвенно через инструкции потока программы (вызов, возврат и т. д.). Другие архитектуры, такие как процессоры Intel Itanium, имеют множественных. В этом смысле стек является элементом архитектуры CPU.
стек-это часть памяти, которой можно управлять с помощью нескольких ключевых инструкций языка сборки, таких как " pop "(удалить и вернуть значение из стека) и "push" (нажать значение в стек), но также вызовите (вызовите подпрограмму - это толкает адрес, чтобы вернуться в стек) и return (возврат из подпрограммы - это выскакивает адрес из стека и переходит к нему). Это область памяти под регистром указателя стека, которую можно установить по мере необходимости. Стек также используется для передачи аргументов подпрограммам, а также для сохранения значений в регистрах перед вызовом подпрограмм.
куча-это часть памяти, которая предоставляется приложению операционной системой, обычно через syscall, например malloc. В современных ОС эта память представляет собой набор страниц, к которым имеет доступ только вызывающий процесс.
размер стека определяется во время выполнения и обычно не увеличивается после запуска программы. В программе C стек должен быть достаточно большим, чтобы содержать каждую переменную, объявленную в каждой функции. Куча будет расти динамически по мере необходимости, но ОС в конечном итоге делает вызов (она часто будет увеличивать кучу больше, чем значение, запрошенное malloc, так что по крайней мере некоторым будущим malloc не нужно будет возвращаться к ядру, чтобы получить больше памяти. Это поведение часто настраивается)
поскольку вы выделили стек перед запуском программы, вам никогда не нужно malloc, прежде чем вы сможете использовать стопка, так что это небольшое преимущество. На практике очень сложно предсказать, что будет быстрым, а что медленным в современных операционных системах с подсистемами виртуальной памяти, потому что как реализуются страницы и где они хранятся-это деталь реализации.
Я думаю, что многие другие люди дали вам в основном правильные ответы на этот вопрос.
одна деталь, которая была упущена, однако, заключается в том, что" куча "на самом деле, вероятно, должна называться"свободным магазином". Причина этого различия заключается в том, что исходное свободное хранилище было реализовано со структурой данных, известной как "биномиальная куча"."По этой причине выделение из ранних реализаций malloc () / free () было выделением из кучи. Тем не менее, в этот современный день, большинство бесплатно хранилища реализованы с очень сложными структурами данных, которые не являются биномиальными кучами.
что такое стек?
стопка-это куча объектов, обычно аккуратно расположенных.

стеки в вычислительных архитектурах-это области памяти,где данные добавляются или удаляются последним в первом выходе.
В многопоточное приложение, каждый поток будет иметь свой собственный стек.
что такое куча?
куча-это беспорядочная коллекция вещей, сложенных беспорядочно.

в вычислительных архитектурах куча-это область динамически выделяемой памяти, которая автоматически управляется операционной системой или библиотекой диспетчера памяти.
Память в куче выделяется, освобождается и изменяется регулярно во время выполнения программы, и это может привести к проблеме, называемой фрагментация.
Фрагментация происходит, когда объекты памяти выделяются с небольшими промежутками между ними, которые слишком малы для хранения дополнительных объектов памяти.
Чистый результат-это процент пространства кучи, который не используется для дальнейшего распределения памяти.
вместе
в многопоточное приложение, каждый поток будет иметь свой собственный стек. Но, все различные потоки будут поделись кучей.
Поскольку разные потоки разделяют кучу в многопоточном приложении, это также означает, что должна быть некоторая координация между потоками, чтобы они не пытались получить доступ к одной и той же части(частям) памяти в куче одновременно.
что быстрее-стек или куча? И почему?
стек намного быстрее, чем куча.
Это потому что память выделяется в стеке.
Выделение памяти в стеке так же просто, как перемещение указателя стека вверх.
для людей, новичок в программировании, это, вероятно, хорошая идея использовать стек, так как это проще.
Поскольку стек небольшой, вы захотите использовать его, когда точно знаете, сколько памяти вам понадобится для ваших данных, или если вы знаете, что размер ваших данных очень мал.
Лучше использовать куча, когда вы знаете, что вам понадобится много памяти для ваших данных, или вы просто не уверены, сколько памяти вам понадобится (например, с динамическим массивом).
Модель Памяти Java

стек-это область памяти, в которой хранятся локальные переменные (включая параметры метода). Когда дело доходит до переменных объекта, это просто ссылки (указатели) на фактические объекты в куче.
Каждый раз, когда объект экземпляр, кусок памяти кучи выделяется для хранения данных (состояние) этого объекта. Поскольку объекты могут содержать другие объекты, некоторые из этих данных могут содержать ссылки на эти вложенные объекты.
вы можете сделать некоторые интересные вещи со стеком. Например, у вас есть такие функции, как alloca (предполагая, что вы можете пройти мимо обильных предупреждений относительно его использования), который является формой malloc, которая специально использует стек, а не кучу, для памяти.
тем не менее, ошибки памяти на основе стека являются одними из худших, которые я испытал. Если вы используете память кучи и переступаете границы выделенного блока, у вас есть неплохой шанс запустить сегмент ошибка. (Не 100%: ваш блок может быть случайно смежным с другим, который вы ранее выделили.) Но поскольку переменные, созданные в стеке, всегда смежны друг с другом, запись за пределы может изменить значение другой переменной. Я узнал, что всякий раз, когда я чувствую, что моя программа перестала подчиняться законам логики, это возможно переполнение буфера.
просто стек-это место, где создаются локальные переменные. Кроме того, каждый раз, когда вы вызываете подпрограмму, счетчик программы (указатель на следующую машинную инструкцию) и любые важные регистры, а иногда параметры выталкиваются в стек. Затем все локальные переменные внутри функции помещаются в стек (и используется). Когда подпрограмма заканчивается, все эти вещи возвращаются из стека. Данные ПК и регистра получают и возвращают туда, где они были, так как они выскочили, поэтому ваша программа может идти своим чередом.
куча-это область памяти, из которой сделаны динамические выделения памяти (явные вызовы "new" или "allocate"). Это специальная структура данных, которая может отслеживать блоков памяти различных размеров и их присвоение.
в "классических" системах ОЗУ было выложено так, что указатель стека начинался внизу памяти, указатель кучи начинался вверху, и они росли навстречу друг другу. Если они перекрываются, вы вышли из рама. Однако это не работает с современными многопоточными ОС. Каждый поток должен иметь свой собственный стек, и они могут быть созданы динамично.
Из WikiAnwser.
стек
когда функция или метод вызывает другую функцию, которая вызывает другую функцию и т. д., выполнение всех этих функций остается приостановленным до тех пор, пока последняя функция не вернет свое значение.
эта цепочка приостановленных вызовов функций является стеком, потому что элементы в стеке (вызовы функций) зависят друг от друга.
стек важен для рассмотрения в обработке исключений и потоке исполнения.
кучу
куча-это просто память, используемая программами для хранения переменных. Элемент кучи (переменные) не имеют зависимостей друг от друга и всегда могут быть доступны случайным образом в любое время.
стек
- быстрый доступ
- не нужно явно выделять переменные
- пространство эффективно управляется процессором, память не будет фрагментирована
- локальные переменные только
- ограничение на размер стека (зависит от ОС)
- переменные не могут быть изменены
кучу
- переменные могут быть доступны во всем мире
- нет ограничения на размер памяти
- (относительно) медленный доступ
- нет гарантированного эффективного использования пространства, память может стать фрагментированной с течением времени, поскольку выделяются блоки памяти, а затем освобождаются
- вы должны управлять памятью (вы отвечаете за выделение и освобождение переменных)
- переменные могут быть изменены с помощью realloc ()
в 1980-х годах UNIX распространялся, как кролики, с большими компаниями, катящими свои собственные. У Exxon был один, как и десятки брендов, потерянных для истории. Как была выложена память, оставалось на усмотрение многих исполнителей.
типичная программа c валялся в памяти возможность увеличения путем изменения значения brk (). Как правило, куча была чуть ниже этого значения brk и увеличение brk увеличило количество доступной кучи.
один стек был как правило, область ниже кучи, которая была трактом памяти не содержащий ничего ценного до вершины следующего фиксированного блока памяти. Этот следующий блок часто был кодом, который мог быть перезаписан данными стека в одном из знаменитых писак своей эпохи.
один типичный блок памяти был BSS (блок нулевых значений) который случайно не был обнулен в предложении одного производителя. Другим были данные, содержащие инициализированные значения, включая строки и числа. Третьим был код, содержащий ЭЛТ (C runtime), main, функции и библиотеки.
появление виртуальной памяти в UNIX изменяет многие ограничения. Нет объективной причины, по которой эти блоки должны быть смежными, или фиксированный в размере,или заказанный определенным образом. Конечно, раньше UNIX был Multics, который не страдал от этих ограничений. Вот схема, показывающая один из макетов памяти той эпохи.

- введение
физическая память-это диапазон физических адресов ячеек памяти, в которых приложение или система хранит свои данные, код и т. д. Во время выполнения. Управление памятью означает управление этими физическими адресами путем замены данных из физической памяти на запоминающее устройство, а затем обратно в физическую память при необходимости. ОС реализует службы управления памятью с использованием виртуальной памяти. Как приложение C# разработчик вам не нужно писать какие-либо службы управления памятью. Среда CLR использует базовые службы управления памятью ОС для предоставления модели памяти для языка C# или любого другого языка высокого уровня, предназначенного для среды CLR.
на рис. 4-1 показана физическая память, абстрагированная и управляемая ОС с использованием концепции виртуальной памяти. Виртуальная память-это абстрактное представление физической памяти, управляемой ОС. Виртуальная память-это просто ряд виртуальных адресов, и эти виртуальные адреса адреса при необходимости преобразуются ЦП в физический адрес.
рис. 4-1. абстракция памяти CLR
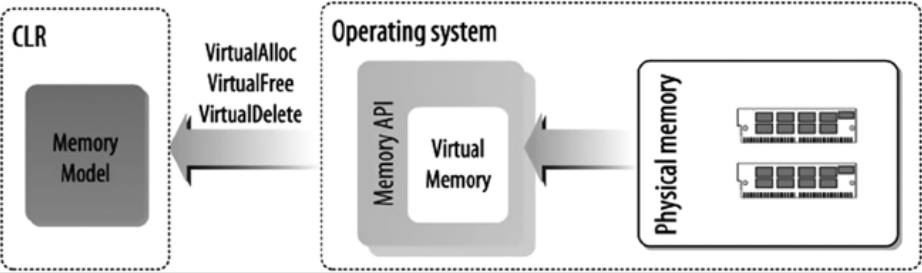
среда CLR предоставляет абстрактный уровень управления памятью для виртуальной среды выполнения с помощью служб оперативной памяти. Абстрактные понятия, используемые средой CLR, - это AppDomain, thread, stack, heapmemorymapped file и т. д. Понятие домена приложения (AppDomain) дает вашему приложению изолированная среда выполнения.
- взаимодействие памяти между CLR и OS
глядя на трассировку стека при отладке следующего приложения c#,используя WinDbg, вы увидите, как среда CLR использует базовые службы управления памятью ОС (например, метод HeapFree из KERNEL32.dll, метод RtlpFreeHeap из ntdll.dll файлы) для реализации собственной модели памяти:
using System;
namespace CH_04
{
class Program
{
static void Main(string[] args)
{
Book book = new Book();
Console.ReadLine();
}
}
public class Book
{
public void Print() { Console.WriteLine(ToString()); }
}
}
скомпилированная сборка программа загружается в WinDbg для начала отладки. Вы используете следующее команды для инициализации сеанса отладки:
0: 000> sxe ld clrjit
0: 000> g
0:000> .loadby sos clr
0:000> .груз C:\Windows\Microsoft.NET\Framework\v4.0.30319\sos.dll
затем, вы установите точку останова в методе Main класса Program , с помощью !команда bpmd:
0:000>!bpmd CH_04.исполняемый CH_04.Программа.Главная
чтобы продолжить выполнение и прерваться в точке останова, выполните g команда:
0: 000> g
когда выполнение прерывается в точке останова, вы используете !команда eestack для просмотра сведений трассировки стека всех потоков, запущенных для текущего процесса. В следующих выходных данных показана трассировка стека для всех потоков, запущенных для приложения CH_04.exe:
0:000> !eestack
поток 0
текущий кадр: (MethodDesc 00233800 +0 CH_04.Программа.основная система.String []))
Childebp RetAddr Caller, Callee
0022ed24 5faf21db clr!CallDescrWorker+0x33
/след удалены/
0022f218 77712d68 ntdll!RtlFreeHeap+0x142, вызов ntdll!RtlpFreeHeap
0022f238 на kernel32 771df1ac!HeapFree+0x14, вызов ntdll!RtlFreeHeap
0022f24c 5fb4c036 clr!EEHeapFree+0x36, вызывая KERNEL32!HeapFree
0022f260 5fb4c09d clr!EEHeapFreeInProcessHeap+0x24, вызов clr!EEHeapFree
0022f274 5fb4c06d clr!оператор delete[]+0x30, называя clr!EEHeapFreeInProcessHeap/след удалены/
0022f4d0 7771316f ntdll!RtlpFreeHeap+0xb7a, вызов ntdll!_SEH_epilog4
0022f4d4 77712d68 ntdll!RtlFreeHeap+0x142, вызов ntdll!RtlpFreeHeap
0022f4f4 на kernel32 771df1ac!HeapFree+0x14, вызов ntdll!RtlFreeHeap
/след удалены/
эта трассировка стека указывает, что среда CLR использует службы управления памятью ОС для реализации собственной модели памяти. Любая операция памяти in.NET проходит через слой памяти CLR на уровень управления памятью ОС.
рисунок 4-2 иллюстрирует типичную модель памяти приложения c#, используемую средой CLR в во время выполнения.
рис. 4-2. Типичная модель памяти приложения C#
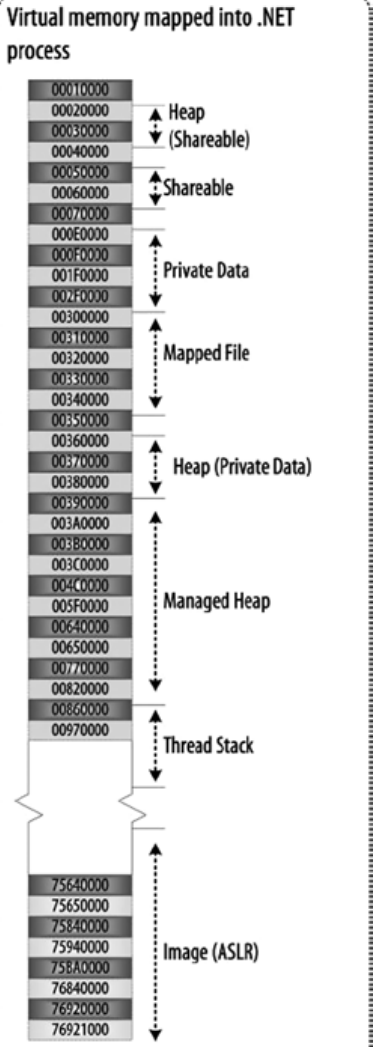
модель памяти CLR тесно связана со службами управления памятью ОС. Чтобы понять модель памяти среды CLR, важно понять базовую модель памяти ОС. также важно знать, как адресное пространство физической памяти абстрагируется в адресное пространство виртуальной памяти, как виртуальное адресное пространство используется пользователем приложение и системное приложение, как работает сопоставление виртуальных и физических адресов, как работает файл, сопоставленный с памятью, и так далее. Это фоновое знание улучшит ваше понимание концепций модели памяти CLR, включая AppDomain, stack и heap.
для получения дополнительной информации обратитесь к этой книге:
C# Deconstructed: узнайте, как C# работает в .NET Framework
эта книга + ClrViaC# + Windows Internals несколько отличные ресурсы для известных .net framework в глубине и связи с ОС.
В Виде
стек используется для статического выделения памяти и памяти для динамического выделения памяти, как хранится в памяти компьютера.
Подробно
Стек
стек-это структура данных" LIFO " (последняя, первая), которая управляется и оптимизируется процессором довольно близко. Каждый раз, когда функция объявляет новую переменную, она "выталкивается" в стек. Затем каждый раз, когда функция выходит, все переменные, помещенные в стек этой функцией, освобождаются (то есть удаляются). Как только переменная стека освобождается, эта область памяти становится доступной для других переменных стека.
преимущество использования стека для хранения переменных заключается в том, что память управляется для вас. Вам не нужно выделять память вручную или освобождать ее, когда она вам больше не нужна. Более того, поскольку CPU так эффективно организует память стека, чтение и запись переменных стека очень быстрый.
больше можно найти здесь.
Кучу
куча-это область памяти вашего компьютера, которая не управляется автоматически для вас и не так жестко управляется процессором. Это более свободно плавающая область памяти (и больше). Чтобы выделить память в куче, необходимо использовать malloc () или calloc (), которые являются встроенными функциями C. После того, как вы выделили память в куче, вы ответственны за использование free () для освобождения этой памяти, когда она вам больше не нужна.
Если вы не сделаете этого, ваша программа будет иметь то, что известно как утечка памяти. То есть память в куче все равно будет отложена (и не будет доступна другим процессам). Как мы увидим в разделе отладки, существует инструмент под названием отчет это может помочь вам обнаружить утечки памяти.
В отличие от стека, куча не имеет ограничений по размеру переменный размер (помимо очевидных физических ограничений вашего компьютера). Память кучи немного медленнее для чтения и записи, потому что для доступа к памяти в куче необходимо использовать указатели. Вскоре мы поговорим о указателях.
в отличие от стека, переменные, созданные в куче, доступны любой функции в любом месте вашей программы. Переменные кучи по своей сути являются глобальными.
больше можно найти здесь.
переменные, выделенные в стеке, хранятся непосредственно в памяти, и доступ к этой памяти очень быстрый, и его выделение рассматривается при компиляции программы. Когда функция или метод вызывает другую функцию, которая вызывает другую функцию и т. д., выполнение всех этих функций остается приостановленным до тех пор, пока последняя функция не вернет свое значение. Стек всегда зарезервирован в порядке LIFO, самый последний зарезервированный блок - это всегда следующий блок, который нужно освободить. Это упрощает отслеживание стека, освобождение блока от стека - это не что иное, как настройка одного указателя.
переменные, выделенные в куче, имеют свою память, выделенную во время выполнения, и доступ к этой памяти немного медленнее, но размер кучи ограничен только размером виртуальной памяти. Элементы кучи не имеют зависимостей друг от друга и всегда могут быть доступны случайным образом в любое время. Вы можете выделите блок в любое время и освободите его в любое время. Это значительно усложняет отслеживание того, какие части кучи выделяются или освобождаются в любой момент времени.

вы можете использовать стек, если точно знаете, сколько данных вам нужно выделить до времени компиляции, и он не слишком велик. Вы можете использовать кучу, если не знаете точно, сколько данных вам понадобится во время выполнения или если вам нужно выделить много данных.
In многопоточная ситуация каждый поток будет иметь свой собственный полностью независимый стек,но они будут делиться кучей. Стек зависит от потока, а куча-от приложения. Стек важно учитывать при обработке исключений и выполнении потоков.
каждый поток получает стек, в то время как обычно для приложения есть только одна куча (хотя не редкость иметь несколько куч для разных типов распределение.)

во время выполнения, если приложению требуется больше кучи, он может выделить память из свободной памяти, а если стеку нужна память, он может выделить память из свободной памяти, выделенной для приложения.
даже, более подробно дано здесь и здесь.
теперь перейдем к ответы на ваш вопрос.
в какой степени они контролируются ОС или языковой средой выполнения?
ОС выделяет стек для каждого потока системного уровня при создании потока. Обычно ОС вызывается языковой средой выполнения для выделения кучи для приложения.
больше можно найти здесь.
какова их область применения?
уже приводил в верхний.
" вы можете использовать стек, если точно знаете, сколько данных вам нужно выделить до времени компиляции, и он не слишком велик. Вы можете использовать кучу, если не знаете точно, сколько данных вам понадобится во время выполнения или если вам нужно выделить много данных."
больше можно найти в здесь.
что определяет размер каждого из них?
размер стека установить по OS при создании потока. Размер кучи устанавливается при запуске приложения, но он может расти по мере необходимости (распределитель запрашивает больше памяти из операционной системы).
что делает быстрее?
распределение стека намного быстрее, так как все, что он действительно делает, это переместить указатель стека. Используя пулы памяти, вы можете получить сопоставимую производительность из распределения кучи, но это происходит с небольшим добавлением сложность и собственные головные боли.
кроме того, стек и куча это не только учет производительности; это также говорит вам много о ожидаемой существования объектов.
детали можно найти от здесь.
OK, просто и коротко говоря, они означают заказал и не заказывал...!
стек: в стеке элементы, вещи получить на вершине друг друга, означает, что будет быстрее и эффективнее обрабатываться!...
таким образом, всегда есть индекс, чтобы указать конкретный элемент, также обработка будет быстрее, есть связь между элементами!...
кучу: никакого порядка, обработка будет медленнее, и значения перепутались вместе без определенного порядка или индекса... они случайны и между ними нет никакой связи... таким образом, время выполнения и использования может быть различным...
Я также создаю картинку ниже, чтобы показать, как они могут выглядеть так:

пару центов: думаю, неплохо будет нарисовать память графически и попроще:

Стрелки-показать, где растут стек и куча, размер стека процесса имеют предел, определенный в ОС, ограничения размера стека потока по параметрам в API создания потока обычно. Куча обычно ограничивает процесс максимальным размером виртуальной памяти, например, для 32 бит 2-4 ГБ.
Так просто: куча процессов является общей для процесса и всех потоков внутри, используя для выделения памяти в общем случае что-то вроде malloc ().
стек-это быстрая память для хранения в общем случае указателей возврата функции и переменных, обрабатываемых как параметры в вызове функции, локальные переменные функции.
поскольку некоторые ответы пошли придираться, я собираюсь внести свой вклад.
Удивительно, но никто не упомянул, что несколько (т. е. не связанных с количеством запущенных потоков на уровне ОС) стеков вызовов можно найти не только на экзотических языках (PostScript) или платформах (Intel Itanium), но и в волокнами, зеленые нити и некоторые реализации coroutines.
волокна, зеленые нити и корутины во многом похожи, что приводит к большой путанице. Разница между волокнами и зелеными нитями заключается в том, что первые используют кооперативную многозадачность, а вторые могут иметь кооперативную или упреждающую (или даже обе). Различие между волокнами и корутинами смотрите в разделе здесь.
В любом случае, цель обоих волокон, зеленых нитей и coroutines имеет несколько функций, выполняющихся одновременно, но не параллельно (см. это так вопрос для различения) в пределах одного потока уровня ОС, передавая управление взад и вперед друг от друга организованным образом.
при использовании волокон, зеленые нитки или сопрограммы, вы обычно имеют отдельный стек для каждой функции. (Технически, не только стек, но и весь контекст выполнения для каждой функции. Наиболее важно отметить, что регистры CPU.) Для каждого потока есть столько стеков, сколько одновременно запущенных функций, и поток переключается между выполнением каждой функции в соответствии с логикой вашей программы. Когда функция выполняется до конца, ее стек уничтожается. Итак,количество и продолжительность жизни стеков динамичны и не определяются количеством потоков уровня ОС!
обратите внимание, что я сказал"обычно иметь отдельный стек за функцией". Есть оба stackful и stackless реализации couroutines. Наиболее заметными stackful реализациями C++ являются импульс.Корутина!--9--> и Microsoft PPL ' s async/await. (Однако c++'ы возобновляемые функции (a.к. a. "async и await"), которые были предложены в C++17, вероятно использование stackless сопрограммы.)
предложение волокон в стандартную библиотеку C++ готовится. Кроме того, есть некоторые третья сторона библиотеки. Зеленые нити чрезвычайно популярны в таких языках, как Python и Ruby.

У меня есть чем поделиться с вами, хотя основные моменты уже написал.
стек
- очень быстрый доступ.
- хранится в ОЗУ.
- вызовы функций загружаются здесь вместе с локальными переменными и параметрами функции.
- пространство освобождается автоматически, когда программа выходит из области.
- хранящиеся в последовательном память.
кучу
- медленный доступ сравнительно к стеку.
- хранится в ОЗУ.
- динамически созданные переменные хранятся здесь, что позже требует освобождения выделенной памяти после использования.
- хранится там, где выделение памяти выполняется, доступ к указателю всегда.
интересное замечание:
- если вызовы функций были сохранены в куче, это бы стало в 2 грязный очков:
- из-за последовательного хранения в стеке, выполнения быстрее. Хранение в куче привело бы к огромному потреблению времени, в результате чего вся программа выполнялась бы медленнее.
- если бы функции хранились в куче (беспорядочное хранилище, указываемое указателем), не было бы возможности вернуться к адресу вызывающего абонента (который стек дает из-за последовательного хранения в памяти).
отзывы сад.
многие ответы верны как концепции, но мы должны отметить, что стек необходим аппаратным средствам (т. е. микропроцессору), чтобы разрешить вызов подпрограмм (вызов на языке ассемблера..). (ОП ребята назовут это методы)
в стеке вы сохраняете обратные адреса и вызываете → push / ret → pop управляется непосредственно в аппаратном обеспечении.
вы можете использовать стек для передачи параметров.. даже если это медленнее, чем использование регистров (сказал бы гуру микропроцессора или хорошая книга 1980-х годов...)
- без стека нет микропроцессор может работать. (мы не можем представить программу, даже на языке ассемблера, без подпрограмм / функций)
- без кучи он может. (Программа языка ассемблера может работать без, так как куча-это концепция ОС, как malloc, то есть вызов OS/Lib.
использование стека быстрее, так как:
- это оборудование, и даже push / pop очень эффективный.
- malloc требует входа в режим ядра, использования блокировки / семафора (или других примитивов синхронизации), выполняющих некоторый код, и управления некоторыми структурами, необходимыми для отслеживания распределения.