ANTLR: вызов правила из другой грамматики
можно ли вызвать правило из другой грамматики?
цель состоит в том, чтобы иметь два языка в одном файле, второй язык, начинающийся с (begin ...) где. .. это на втором языке. грамматика должна вызывать другую грамматику для анализа этого второго языка.
например:
grammar A;
start_rule
: '(' 'begin' B.program ')' //or something like that
;
grammar B;
program
: something* EOF
;
something
: ...
;
1 ответов
ваш вопрос может быть интерпретирован (по крайней мере) двумя способами:
- отдельные правила из большой грамматики в отдельные грамматики;
- разберите отдельный язык внутри вашего "основного" языка (грамматика острова).
я предполагаю, что это первый, в этом случае вы можете импортировать грамматик.
демо для варианта 1:
файл: L. g
lexer grammar L;
Digit
: '0'..'9'
;
файл: Sub.g
parser grammar Sub;
number
: Digit+
;
grammar Root;
import Sub;
parse
: number EOF {System.out.println("Parsed: " + $number.text);}
;
file: Main.java
import org.antlr.runtime.*;
public class Main {
public static void main(String[] args) throws Exception {
L lexer = new L(new ANTLRStringStream("42"));
CommonTokenStream tokens = new CommonTokenStream(lexer);
RootParser parser = new RootParser(tokens);
parser.parse();
}
}
запустить демо:
bart@hades:~/Programming/ANTLR/Demos/Composite$ java -cp antlr-3.3.jar org.antlr.Tool L.g
bart@hades:~/Programming/ANTLR/Demos/Composite$ java -cp antlr-3.3.jar org.antlr.Tool Root.g
bart@hades:~/Programming/ANTLR/Demos/Composite$ javac -cp antlr-3.3.jar *.java
bart@hades:~/Programming/ANTLR/Demos/Composite$ java -cp .:antlr-3.3.jar Main
которая будет печатать:
Parsed: 42
в консоли.
Подробнее см.:http://www.antlr.org/wiki/display/ANTLR3/Composite + грамматики
демо-варианта 2:
хорошим примером языка внутри языка является регулярное выражение. У вас есть "нормальный" язык регулярных выражений с его мета-символами, но есть еще один один в нем: язык, который описывает набор символов (или класс символов).
вместо учета мета-символов набора символов (диапазон - отрицание ^, etc.) внутри вашей regex-грамматики вы можете просто рассматривать набор символов как один токен, состоящий из [ и затем все до и в том числе ] (возможно \] в нем!) внутри регулярного выражения-грамматика. Когда вы наткнетесь на CharSet токен в одном из ваших анализаторов правила, вы вызываете CharSet-parser.
файл: регулярное выражение.g
grammar Regex;
options {
output=AST;
}
tokens {
REGEX;
ATOM;
CHARSET;
INT;
GROUP;
CONTENTS;
}
@members {
public static CommonTree ast(String source) throws RecognitionException {
RegexLexer lexer = new RegexLexer(new ANTLRStringStream(source));
RegexParser parser = new RegexParser(new CommonTokenStream(lexer));
return (CommonTree)parser.parse().getTree();
}
}
parse
: atom+ EOF -> ^(REGEX atom+)
;
atom
: group quantifier? -> ^(ATOM group quantifier?)
| EscapeSeq quantifier? -> ^(ATOM EscapeSeq quantifier?)
| Other quantifier? -> ^(ATOM Other quantifier?)
| CharSet quantifier? -> ^(CHARSET {CharSetParser.ast($CharSet.text)} quantifier?)
;
group
: '(' atom+ ')' -> ^(GROUP atom+)
;
quantifier
: '+'
| '*'
;
CharSet
: '[' (('\' .) | ~('\' | ']'))+ ']'
;
EscapeSeq
: '\' .
;
Other
: ~('\' | '(' | ')' | '[' | ']' | '+' | '*')
;
file: CharSet.g
grammar CharSet;
options {
output=AST;
}
tokens {
NORMAL_CHAR_SET;
NEGATED_CHAR_SET;
RANGE;
}
@members {
public static CommonTree ast(String source) throws RecognitionException {
CharSetLexer lexer = new CharSetLexer(new ANTLRStringStream(source));
CharSetParser parser = new CharSetParser(new CommonTokenStream(lexer));
return (CommonTree)parser.parse().getTree();
}
}
parse
: OSqBr ( normal -> ^(NORMAL_CHAR_SET normal)
| negated -> ^(NEGATED_CHAR_SET negated)
)
CSqBr
;
normal
: (EscapeSeq | Hyphen | Other) atom* Hyphen?
;
negated
: Caret normal -> normal
;
atom
: EscapeSeq
| Caret
| Other
| range
;
range
: from=Other Hyphen to=Other -> ^(RANGE $from $to)
;
OSqBr
: '['
;
CSqBr
: ']'
;
EscapeSeq
: '\' .
;
Caret
: '^'
;
Hyphen
: '-'
;
Other
: ~('-' | '\' | '[' | ']')
;
file: Main.java
import org.antlr.runtime.*;
import org.antlr.runtime.tree.*;
import org.antlr.stringtemplate.*;
public class Main {
public static void main(String[] args) throws Exception {
CommonTree tree = RegexParser.ast("((xyz)*[^\da-f])foo");
DOTTreeGenerator gen = new DOTTreeGenerator();
StringTemplate st = gen.toDOT(tree);
System.out.println(st);
}
}
и если вы запустите основной класс, вы увидите точка выхода для регулярного выражения ((xyz)*[^\da-f])foo что следующее дерево:
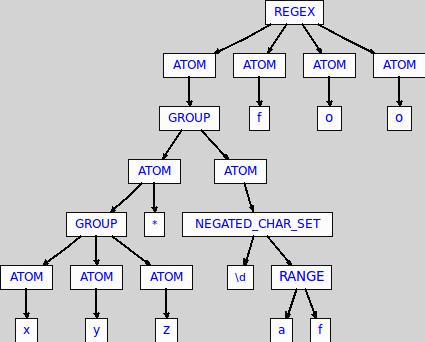
магия находится внутри Regex.g грамматика в atom правило, в котором я вставил узел дерева в правило перезаписи, вызвав static ast метод CharSetParser класс:
CharSet ... -> ^(... {CharSetParser.ast($CharSet.text)} ...)
обратите внимание, что внутри таких правил переписывания должны быть не быть двоеточие! Итак, это было бы неправильно:{CharSetParser.ast($CharSet.text);}.
редактировать
и вот как создать tree walkers для обеих грамматик:
файл: RegexWalker.g
tree grammar RegexWalker;
options {
tokenVocab=Regex;
ASTLabelType=CommonTree;
}
walk
: ^(REGEX atom+) {System.out.println("REGEX: " + $start.toStringTree());}
;
atom
: ^(ATOM group quantifier?)
| ^(ATOM EscapeSeq quantifier?)
| ^(ATOM Other quantifier?)
| ^(CHARSET t=. quantifier?) {CharSetWalker.walk($t);}
;
group
: ^(GROUP atom+)
;
quantifier
: '+'
| '*'
;
файл: CharSetWalker.g
tree grammar CharSetWalker;
options {
tokenVocab=CharSet;
ASTLabelType=CommonTree;
}
@members {
public static void walk(CommonTree tree) {
try {
CommonTreeNodeStream nodes = new CommonTreeNodeStream(tree);
CharSetWalker walker = new CharSetWalker(nodes);
walker.walk();
} catch(Exception e) {
e.printStackTrace();
}
}
}
walk
: ^(NORMAL_CHAR_SET normal) {System.out.println("NORMAL_CHAR_SET: " + $start.toStringTree());}
| ^(NEGATED_CHAR_SET normal) {System.out.println("NEGATED_CHAR_SET: " + $start.toStringTree());}
;
normal
: (EscapeSeq | Hyphen | Other) atom* Hyphen?
;
atom
: EscapeSeq
| Caret
| Other
| range
;
range
: ^(RANGE Other Other)
;
Main.java
import org.antlr.runtime.*;
import org.antlr.runtime.tree.*;
import org.antlr.stringtemplate.*;
public class Main {
public static void main(String[] args) throws Exception {
CommonTree tree = RegexParser.ast("((xyz)*[^\da-f])foo");
CommonTreeNodeStream nodes = new CommonTreeNodeStream(tree);
RegexWalker walker = new RegexWalker(nodes);
walker.walk();
}
}
для запуска демо, do:
java -cp antlr-3.3.jar org.antlr.Tool CharSet.g
java -cp antlr-3.3.jar org.antlr.Tool Regex.g
java -cp antlr-3.3.jar org.antlr.Tool CharSetWalker.g
java -cp antlr-3.3.jar org.antlr.Tool RegexWalker.g
javac -cp antlr-3.3.jar *.java
java -cp .:antlr-3.3.jar Main
которая будет печатать:
NEGATED_CHAR_SET: (NEGATED_CHAR_SET \d (RANGE a f))
REGEX: (REGEX (ATOM (GROUP (ATOM (GROUP (ATOM x) (ATOM y) (ATOM z)) *) (CHARSET (NEGATED_CHAR_SET \d (RANGE a f))))) (ATOM f) (ATOM o) (ATOM o))