Эффективное декодирование двоичных и текстовых структур (пакетов)
фон
есть известный инструмент под названием помощью Wireshark. Я использую его целую вечность. Это здорово,но проблема в производительности. Общий сценарий использования включает в себя несколько шагов подготовки данных для извлечения подмножества данных для последующего анализа. Без этого шага требуется несколько минут для фильтрации (с большими трассировками Wireshark почти непригоден).
сама идея-создать лучше решение, быстрое, параллельное и эффективное, для использования в качестве агрегатора/хранилища данных.
требования
фактическое требование использовать всю силу обеспеченную современным оборудованием. Я должен сказать, что есть место для разных типов оптимизации, и я надеюсь, что хорошо поработал над верхними слоями, но технология-это главный вопрос прямо сейчас. В соответствии с текущей конструкцией существует несколько разновидностей пакетных декодеров (диссекторы):
- интерактивные дешифраторы: логика декодирования может быть легко изменена во время выполнения. Такой подход может быть весьма полезен для разработчиков протоколов - скорость декодирования не так важна, но гибкость и быстрые результаты важнее
- встраиваемый дешифраторы: может использоваться как библиотека.Этот тип должен иметь хорошую производительность и быть достаточно гибким, чтобы использовать все доступные процессоры и ядра
- декодеры как услуги: можно получить доступ через чистый API. Этот тип должен обеспечивать наилучшую производительность и эффективность породы
результаты
мое текущее решение-декодеры на основе JVM. Фактическая идея заключается в повторном использовании кода, устранении переноса и т. д., Но все же имеет хорошую эффективность.
- интерактивные дешифраторы: выполнено на В Groovy
- встраиваемый дешифраторы: реализовано на Java
- декодеры как услуги: Tomcat + оптимизация + встраиваемые декодеры, завернутые в сервлет (binary in, XML out)
проблем
- Groovy обеспечивает путь к большой силе и всему, но удача выразительность в этом конкретном случае
- протокол декодирования в древовидную структуру является мертвым конец - слишком много ресурсов просто тратится впустую
- потребление памяти несколько трудно контролировать. Я сделал несколько оптимизаций, но все еще не доволен результатами профилирования
- Tomcat с различными колокольчиками и свистками все еще вводит в много накладных расходов (в основном обработка соединения)
правильно ли я использую JVM везде? Вы видите какой-либо другой хороший и элегантный способ достижения первоначальной цели: получить простой в написании масштабируемый и эффективный протокол декодеры?
протокол, формат результатов и т. д. не являются фиксированными.
3 ответов
Я нашел несколько возможных улучшений:
интерактивные дешифраторы
выразительность Groovy может быть значительно улучшена путем расширения синтаксиса Groovy с использованием AST преобразования. Таким образом, можно было бы упростить разработку декодеров, все еще обеспечивая хорошую производительность. AST (означает абстрактное синтаксическое дерево) - это метод времени компиляции.
когда компилятор Groovy компилирует скрипты и классы Groovy, в некоторых точка в процессе, исходный код в конечном итоге будет представлен в память в виде конкретного синтаксического дерева, затем преобразуется в абстрактное синтаксическое дерево. Цель преобразований AST-позволить разработчики подключаются к процессу компиляции, чтобы иметь возможность изменять AST, прежде чем он превратится в байт-код, который будет выполняться JVM.
Я не хочу изобретать колесо, вводя еще один язык для определения / описания структуры протокола (это достаточно иметь ASN.1). Идея состоит в том, чтобы упростить разработку декодеров, чтобы обеспечить быструю технику прототипирования. В принципе, должен быть введен какой-то DSL.
встраиваемый дешифраторы
Java может ввести некоторые дополнительные накладные расходы. Существует несколько библиотек для решения этой выпуск:
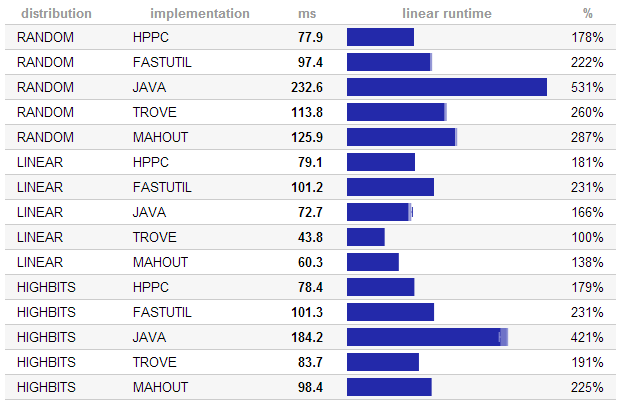
честно говоря, я не вижу другого варианта, кроме Java для этого слоя.
декодеры как услуги
на этом уровне Java не требуется. Наконец, у меня есть хороший вариант, но цена довольно высока. Гван выглядит очень хорошо.
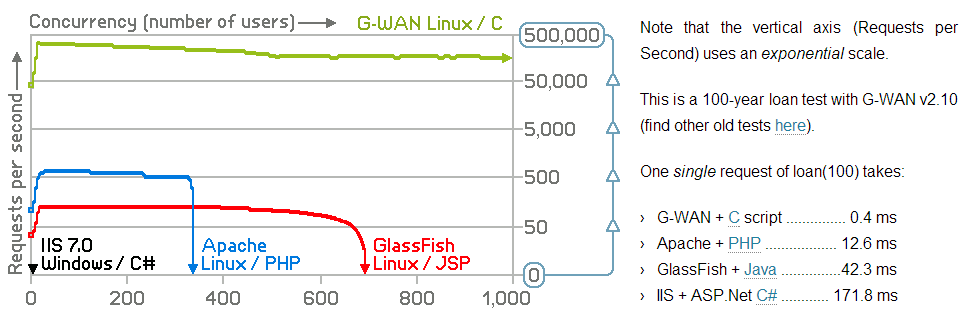
потребуется дополнительный перенос, но это определенно того стоит.
эта проблема, похоже, разделяет ту же характеристику многих высокопроизводительных проблем реализации ввода-вывода, которая заключается в том, что количество копий памяти доминирует над производительностью. Шаблоны интерфейса scatter-gather для асинхронного ввода-вывода следуют этому принципу. С scatter-gather блоки памяти работают на месте. До тех пор, пока декодеры протокола принимают потоки блоков в качестве входных, а не байтовых потоков, вы устраните много накладных расходов на производительность движущейся памяти вокруг, чтобы сохранить абстракцию потока байтов. Поток байтов-очень хорошая абстракция для экономии инженерного времени, но не очень хорошая для высокопроизводительного ввода-вывода
в связанной с этим проблеме я бы остерегался JVM только из-за базового типа String. Я не могу сказать, что я знаком с String реализован в JVM, но я полагаю, что нет способа сделать строку из списка блоков без копирования памяти. С другой стороны, родная струна, которая могла бы ... что interoperated с JVM String compatibly может быть способом разделения разницы.
Другим аспектом этой проблемы, который представляется актуальным, является проблема формальных языков. В духе не копировать блоки памяти, вы также не хотите сканировать один и тот же блок памяти снова и снова. Поскольку вы хотите внести изменения во время выполнения, это означает, что вы, вероятно, не хотите использовать предварительно скомпилированную машину состояний, а скорее рекурсивный анализатор спуска, который может отправлять соответствующий переводчик протокола на каждом уровне спуска. Существуют некоторые осложнения, когда внешний слой не указывает тип внутреннего слоя. Эти осложнения еще хуже, когда вы даже не получаете длину внутреннего содержания, так как тогда вы полагаетесь на внутреннее содержание, чтобы быть хорошо сформированным, чтобы предотвратить побег. Тем не менее, стоит обратить внимание на то, сколько раз будет сканироваться один блок.
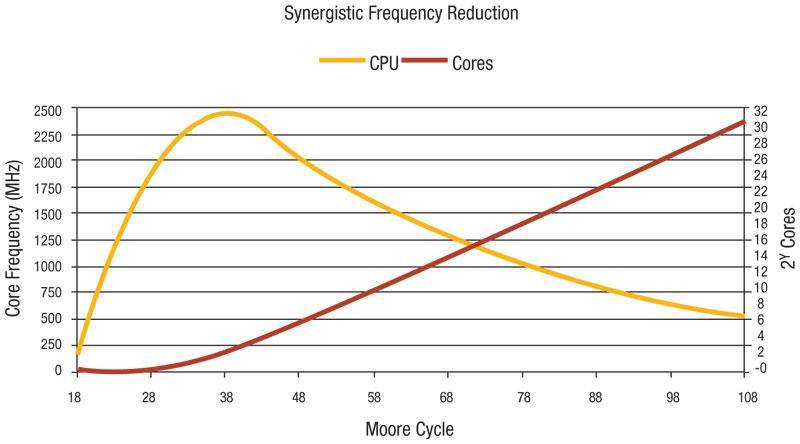
сетевой трафик растет (некоторые аналитики), поэтому будет необходимо обрабатывать все больше и больше данных в секунду.
единственный способ достичь этого-использовать больше ресурсов процессора, но частота процессора стабильна. Растет только количество ядер. Похоже, единственный способ - использовать доступные ядра более эффективно и масштабировать их лучше.