Java: обнаружение управляющих символов, которые неверны для JSON
я изобретаю колесо и создаю свои собственные методы анализа JSON в Java.
Я собираюсь (очень приятно!) документации на json.org. Единственная часть я не уверен, где он говорит "или управляющих символов"
поскольку документация настолько ясна, а JSON настолько прост и прост в реализации, я думал, что буду идти вперед и требовать спецификации вместо того, чтобы быть свободным.
как бы я правильно удалить управляющие символы в Java? Возможно, существует диапазон unicode?
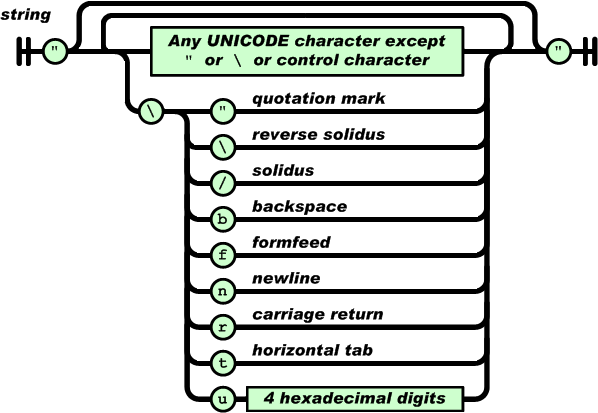
Edit: A (обычно?) отсутствует кусок головоломки
Я сообщили что есть другие управляющие символы вне определенного диапазона 1 2 что может быть хлопотно в <script> теги.
большинство в частности, символы U+2028 и U+2029, разделитель строк и абзацев, которые действуют как новые строки. Введение новой строки в середину строкового литерала, скорее всего, вызовет синтаксическую ошибку (unterminated string literal). 3
хотя я считаю, что это не представляет угрозы XSS, все же неплохо добавить дополнительные правила для использования в <script> теги.
- просто кодировать все"из набора ASCII" персонажей с
uнотации. Эти персонажи необычны для начала. Если хотите, вы можете добавить в белый список, но я рекомендую подход с белым списком. - в случае, если вы не осведомлены, не забудьте о
</script(без учета регистра), которые может вызвать инъекцию HTML-скрипта на вашу страницу с символами</script><script src=http://tinyurl.com/abcdef>. Ни один из этих символов по умолчанию не кодируется в JSON.
4 ответов
будет символ.isISOControl (...) делать? Кстати, UTF-16-это кодировка кодовых точек Unicode... Вы собираетесь работать на уровне байтов или на уровне символов/кодовых точек? Я рекомендую оставить отображение из UTF-16 в символьные потоки для основных API Java...
даже если это не очень конкретно, я бы предположил, что они относятся к " контроль " категория символов из спецификации Unicode.
в Java, вы можете проверить, если символ c является управляющим символом Юникода со следующим выражением:Character.getType(c) == Character.CONTROL.
Я считаю определение управляющего символа в Юникоде - это:
65 символов в диапазонах U+0000..U + 001F и U + 007F..U + 009F.
Это их определение управляющий код, но за этим следует предложение "также известный как управляющие символы.", так...
Я знаю, что вопрос был задан пару лет назад, но я все равно отвечаю, потому что принятый ответ неверен.
Character.isISOControl(int codePoint)
выполняет следующие проверки:
(codePoint >= 0x00 && codePoint <= 0x1F) || (codePoint >= 0x7F && codePoint <= 0x9F);
спецификация JSON определяет at https://tools.ietf.org/html/rfc7159:
строки
представление строк аналогично соглашениям, используемым в C семейство языков программирования. Ля строка начинается и заканчивается кавычки. Все символы Unicode могут быть помещены в кавычки, за исключением символов, которые должны быть экранированы: кавычки, обратный solidus, и контрольные символы (U+0000 до U+001F).
Character.isISOControl(int codePoint)
будет отмечать все символы, которые должны быть экранированы (U+0000-U+001F), хотя он также будет помечать символы, которые не нужно экранировать (U+007F-U+009F). Не требуется, чтобы избежать персонажи (U+007F-U+009F).