Как будут реализованы fabs(double) на x86? Это дорогостоящая операция?
языки программирования высокого уровня часто предоставляют функцию для определения абсолютного значения значения с плавающей запятой. Например, в стандартной библиотеке C есть .
как эта функция библиотеки фактически реализована для целей x86? Что на самом деле происходит "под капотом", когда я вызываю такую функцию высокого уровня?
это дорогостоящая операция (комбинация умножения и извлечения квадратного корня)? Или результат найден просто путем удаления отрицательного знака в памяти?
1 ответов
вообще, вычислять абсолютн-значение количества с плавающей запятой весьма дешевая и быстрая деятельность.
практически во всех случаях вы можете просто лечить fabs функция из стандартной библиотеки в виде черного ящика, разбрызгивая его в ваших алгоритмах, где это необходимо, без необходимости беспокоиться о том, как это повлияет на скорость выполнения.
если вы хотите понять почему это такая дешевая операция, то вы нужно немного знать о том, как представлены значения с плавающей запятой. Хотя стандарты языка C и c++ фактически не санкционируют его, большинство реализаций следуют IEEE-754 стандартные. В этом стандарте представление каждого значения с плавающей запятой содержит бит, известный как знаковый бит, а это знаменует, является ли значение положительным или отрицательным. Рассмотрим, например,double, который является 64-разрядным двойной точности с плавающей запятой значение:
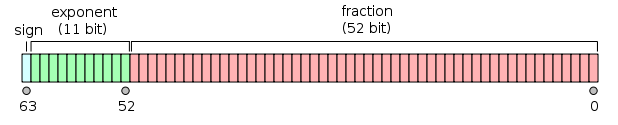
(Изображение предоставлено Codekaizen, через Википедию, лицензировано под CC-bySA.)
вы можете увидеть знак немного вон там, в дальнем левом углу, в светло-голубой. Это верно для всех точности значений с плавающей запятой в IEEE-754. Поэтому принятие абсолютного значения в основном сводится к переворачиванию байта в представлении значения в памяти. В частности, вам просто нужно замаскировать знак бит (побитовый-и), принуждение его к 0-таким образом, без знака.
предполагая, что ваша целевая архитектура имеет оборудование поддержка операций с плавающей запятой, это, как правило, одна инструкция с одним циклом-в основном, так быстро, как это возможно. Оптимизирующий компилятор встроит вызов fabs функция библиотеки, испуская эту единственную аппаратную инструкцию на своем месте.
если ваша целевая архитектура не есть аппаратная поддержка плавающей точки (что довольно редко в наши дни), тогда будет библиотека, которая эмулирует эту семантику в программном обеспечении, обеспечивая поддержку с плавающей запятой. Как правило, эмуляция с плавающей запятой происходит медленно, но найти абсолютное значение-одна из самых быстрых вещей, которые вы можете сделать, так как это буквально просто немного манипулировать. Вы оплатите накладные расходы на вызов функции fabs, но в худшем случае реализация этой функции будет просто включать чтение байтов из памяти, маскировку бита знака и сохранение результата обратно в память.
просмотр конкретно на x86, который реализует IEEE-754 в аппаратном обеспечении, есть два основных способа, которыми ваш компилятор C преобразует вызов в fabs в машинный код.
в 32-битных сборках, где наследие x87 FPU используется для операций с плавающей запятой, он будет излучать fabs - инструкции. (Да, то же имя, что и функция C.) Это обнажает бит знака, если присутствует, из значения с плавающей запятой в верхней части стека регистров x87. На процессорах AMD и Intel Pentium 4,fabs - это инструкция 1 цикла с задержкой 2 цикла. На AMD Ryzen и всех других процессорах Intel это инструкция 1 цикла с задержкой 1 цикла.
в 32-битных сборках, которые могут предполагать поддержку SSE, и на все 64-битные сборки (где SSE всегда поддерживается), компилятор выдаст ANDPS - инструкции* что делает именно то, что я описал выше: он побитовый-и значение с плавающей запятой с постоянной маской, маскируя бит знака. Обратите внимание, что SSE2 не имеет специальной инструкции для принятия абсолютного значения, как это делает x87, но ему даже не нужно, потому что многоцелевые побитовые инструкции отлично выполняют эту работу. Время выполнения (циклы, задержки и т. д. характеристики) варьируются немного шире от одной микроархитектуры процессора к другой, но, как правило, имеет пропускную способность 1-3 цикла, с подобной задержкой. Если хотите, можете посмотреть в таблицы инструкций Agner Fog для процессоров интересов.
если вы действительно заинтересованы в копаться в этом, вы можете увидеть ответ (hat tip to Peter Cordes), который исследует множество различных способов реализации функции абсолютного значения с использованием инструкций SSE, сравнивая их производительность и обсуждая, как вы могли бы заставить компилятор генерировать соответствующий код. Как вы можете видеть, поскольку вы просто манипулируете битами, существует множество возможных решений! На практике, однако, текущий урожай компиляторов делает именно то, что я описал для функции библиотеки C fabs, что имеет смысл, потому что это лучшее решение общего назначения.
__
* технически, это также может быть ANDPD, где D означает "двойной" (а S означает "один"), но ANDPD требуется поддержка SSE2. SSE поддерживает операции с плавающей запятой с одной точностью и был доступен вплоть до Pentium III. SSE2 требуется для операций с плавающей запятой двойной точности и был введен с Pentium 4. SSE2-это всегда поддерживается процессорами x86-64. Ли ANDPS или ANDPD используется решение, принятое оптимизатором компилятора; иногда вы увидите ANDPS используется для значения с плавающей запятой двойной точности, так как для этого просто требуется написать маску справа путь.
кроме того, на процессорах, поддерживающих инструкции AVX, вы обычно увидите префикс VEX на ANDPS/ANDPD инструкция, так что это становится VANDPS/VANDPD. Подробности о том, как это работает и какова его цель, можно найти в другом месте в интернете; достаточно сказать, что смешивание инструкций VEX и non-VEX может привести к штрафу за производительность, поэтому компиляторы пытаются избежать этого. Опять же, обе эти версии имеют одинаковый эффект и практически одинаковое выполнение скорости.
О, и потому что SSE-это SIMD набор инструкций, можно вычислить абсолютное значение несколько значения с плавающей запятой за один раз. Это, как вы можете себе представить, особенно эффективно. Компиляторы с возможностями автоматической векторизации будут генерировать такой код, где это возможно. Пример (маска может быть сгенерирована на лету, как показано здесь, или загружена как константа):cmpeqd xmm1, xmm1 ; generate the mask (all 1s) in a temporary register
psrld xmm1, 1 ; put 1s in but the left-most bit of each packed dword
andps xmm0, xmm1 ; mask off sign bit in each packed floating-point value