Как извлечь данные таблицы из PDF как CSV из командной строки?
Я хочу, чтобы извлечь все строки из здесь игнорируя заголовки столбцов, а также все заголовки страниц, т. е. Supported Devices.
pdftotext -layout DAC06E7D1302B790429AF6E84696FCFAB20B.pdf -
| sed '$d'
| sed -r 's/ +/,/g; s/ //g'
> output.csv
полученный файл должен быть в формате таблицы CSV (поля значений, разделенные запятыми).
другими словами, Я хочу улучшить приведенную выше команду, чтобы выход не тормозил вообще. Есть идеи?
4 ответов
Я также предложу вам другое решение.
в этом случае pdftotext метод работает с разумными усилиями, могут быть случаи, когда не каждая страница имеет ту же ширину столбца (как показывает ваш довольно доброкачественный PDF).
здесь не очень известное, но довольно крутое бесплатное и открытое программное обеспечение Tabula-Extractor является лучшим выбором.
Я сам использую прямую проверку GitHub:
$ cd $HOME ; mkdir svn-stuff ; cd svn-stuff
$ git clone https://github.com/tabulapdf/tabula-extractor.git git.tabula-extractor
I написал себе довольно простой скрипт-обертку вот так:
$ cat ~/bin/tabulaextr
#!/bin/bash
cd ${HOME}/svn-stuff/git.tabula-extractor/bin
./tabula $@
С ~/bin/ в моем $PATH, Я просто запустить
$ tabulaextr --pages all \
$(pwd)/DAC06E7D1302B790429AF6E84696FCFAB20B.pdf \
| tee my.csv
чтобы извлечь все таблицы со всех страниц и преобразовать их в один CSV-файл.
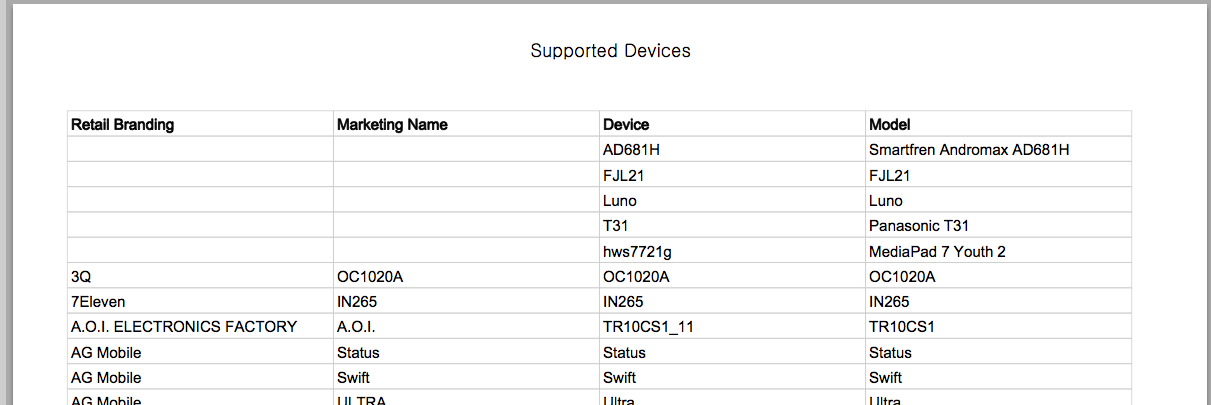
первые десять (из общего числа 8727) строк CVS выглядят так:
$ head DAC06E7D1302B790429AF6E84696FCFAB20B.csv
Retail Branding,Marketing Name,Device,Model
"","",AD681H,Smartfren Andromax AD681H
"","",FJL21,FJL21
"","",Luno,Luno
"","",T31,Panasonic T31
"","",hws7721g,MediaPad 7 Youth 2
3Q,OC1020A,OC1020A,OC1020A
7Eleven,IN265,IN265,IN265
A.O.I. ELECTRONICS FACTORY,A.O.I.,TR10CS1_11,TR10CS1
AG Mobile,Status,Status,Status
которые в оригинальном PDF выглядят следующим образом:
он даже получил эти строки на последней странице, 293, справа:
nabi,"nabi Big Tab HD\xe2\x84\xa2 20""",DMTAB-NV20A,DMTAB-NV20A
nabi,"nabi Big Tab HD\xe2\x84\xa2 24""",DMTAB-NV24A,DMTAB-NV24A
которые выглядят на странице PDF следующим образом:

TabulaPDF и Tabula-Extractor действительно, действительно здорово для таких заданий!
обновление
вот ASCiinema скринкаст (который вы также можете скачать и повторно играть локально в вашем терминале Linux / MacOSX / Unix с помощью asciinema инструмент командной строки), в главной роли tabula-extractor:
то, что вы хотите, довольно легко, но у тебя другая проблема (я не уверен, что вы знаете об этом...).
во-первых, вы должны добавить -nopgbrk на ("нет pagebreaks, пожалуйста!") в вашей команде. Потому что эти надоедливые ^L символы, которые в противном случае появляются в выходных данных не должны быть отфильтрованы позже.
добавлять отфильтрует все строки, которые вы не хотите, включая пустые строки или строки с только пробелы:
pdftotext -layout -nopgbrk \
DAC06E7D1302B790429AF6E84696FCFAB20B.pdf - \
| grep -vE '(Supported Devices|^$|Marketing Name)' \
| gsed '$d' \
| gsed -r 's# +#,#g' \
| gsed '# ##g' \
> output2.csv
однако ваша другая проблема заключается в следующем:
- некоторые поля таблицы остаются пустыми.
- пустые поля появляются с
-layoutопция в виде ряда пробелов, иногда даже двух в одной строке. - однако текстовые столбцы не расположены одинаково от страницы к странице.
- поэтому вы не будете знать из строки в строку, сколько пробелов вам нужно рассматривать как "пустое поле CSV" (где вам понадобится дополнительный
,разделитель). - как следствие, ваш текущий код покажет только одно, два или три (вместо четырех) поля для некоторых строк, и эти поля окажутся в неправильных столбцах!
существует обходной путь для этого:
- добавить
-x ... -y ... -W ... -H ...параметрыpdftotextчтобы обрезать столбец PDF. - затем добавьте столбцы с комбинацией утилит, таких как
pasteиcolumn.
следующая команда извлекает первые столбцы:
pdftotext -layout -x 38 -y 77 -W 176 -H 500 \
DAC06E7D1302B790429AF6E84696FCFAB20B.pdf - > 1st-columns.txt
это для второго, третьего и четвертого столбцов:
pdftotext -layout -x 214 -y 77 -W 176 -H 500 \
DAC06E7D1302B790429AF6E84696FCFAB20B.pdf - > 2nd-columns.txt
pdftotext -layout -x 390 -y 77 -W 176 -H 500 \
DAC06E7D1302B790429AF6E84696FCFAB20B.pdf - > 3rd-columns.txt
pdftotext -layout -x 567 -y 77 -W 176 -H 500 \
DAC06E7D1302B790429AF6E84696FCFAB20B.pdf - > 4th-columns.txt
кстати, я немного обманул: чтобы получить представление о том, какие значения использовать для -x, -y, -W и -H я сначала запустил эту команду, чтобы найти точные координаты слов заголовка столбца:
pdftotext -f 1 -l 1 -layout -bbox \
DAC06E7D1302B790429AF6E84696FCFAB20B.pdf - | head -n 10
это всегда хорошо, если вы умеете читать и пользоваться pdftotext -h. :-)
в любом случае, как добавить четыре текстовых файла в виде столбцов бок о бок, с соответствующим разделителем CVS между ними, вы должны узнать сами. Или задать новый вопрос :-)
As Мартин R прокомментировал, tabula-java новая версия tabula-extractor и активный. 1.0.0 был выпущен 21 июля 2017 года.
Скачать файл jar и с последней java:
java -jar ./tabula-1.0.0-jar-with-dependencies.jar \
--pages=all \
./DAC06E7D1302B790429AF6E84696FCFAB20B.pdf
> support_devices.csv
Это можно легко сделать с помощью IntelliGet (http://akribiatech.com/intelliget) скрипт как показано ниже
userVariables = brand, name, device, model;
{ start = Not(Or(Or(IsSubstring("Supported Devices",Line(0)),
IsSubstring("Retail Branding",Line(0))),
IsEqual(Length(Trim(Line(0))),0)));
brand = Trim(Substring(Line(0),10,44));
name = Trim(Substring(Line(0),45,79));
device = Trim(Substring(Line(0),80,114));
model = Trim(Substring(Line(0),115,200));
output = Concat(brand, ",", name, ",", device, ",", model);
}