Как кодируется информация exif?
с приветом,
Я собираюсь получить информацию exif из некоторых изображений с помощью android. Я знаю, что есть некоторые стандартные Java lib, которые я мог бы использовать с устройством. Я уверен, что в конечном итоге я буду использовать его.
но пока кто-нибудь может объяснить мне, как эта информация закодирована внутри JPG? Где / как вы обычно получаете информацию из документа. Когда я открываю документ с текстовым редактором, он весь двоичный.
любопытно, как это работает и как я могу потенциально прочитать данные, о которых идет речь.
5 ответов
если вы ищете строку "Exif", вы найдете начало данных Exif-это довольно сложно, и я бы рекомендовал использовать библиотеку - (например, моя компания DotImage если вы использовали .NET).
Вот описание высокого уровня, хотя:
сам Exif находится внутри AppMarker - три байта Перед будет E1 (AppMarker 1) и размер данных маркера в endianness файла. Через два байта после Exif вы увидите байт маркера (например,49 49 означает II что означает Intel, little endian -- это означает, что числа 2 байта имеют низкий байт первым в файле).
остальные данные широко используют смещения, смещение происходит от местоположения первого байта endian (49 В приведенном выше случае)
8 байт из этого смещения-это 2-байтовое число, которое является числом тегов exif. Если вы в II порядок байтов, обратный байтам, чтобы прочитать длину.
2 bytes: Tag ID
2 bytes: Tag Type
4 bytes: Length
4 bytes: data if the data is 4 bytes or less, or an offset to the data
после N 12 байтовых записей у вас будут данные, на которые указывает каждое смещение, используемое в вышеуказанных N записях. Вам нужно посмотреть идентификаторы и типы, чтобы увидеть, что они означают и как они представлены.
я немного опаздываю на вечеринку, но написав библиотека Java для обработки Exif (среди других типов метаданных) я думал, что я вмешаюсь.
в EXIF
Exif построен на TIFF, формат файла с тегами. Поэтому сначала мы должны изучить TIFF:
- документ TIFF содержит несколько каталоги известный как IFDs (каталоги файлов изображений)
- каждый IFD содержит ноль или более теги
- IFDs может ссылаться на ноль или более других IFDs
- каждый тег имеет числовой идентификатор и содержит ноль или более значений определенного типа данных
подумайте о структуре как о дереве с примитивными значениями на листьях. TIFF сам описывает свою структуру, но ничего не диктует о том, какие значения на самом деле mean.
действительно, Вы можете хранить любые данные в TIFF, это не связано с изображениями.
файл TIFF имеет общий заголовок:
-
2 байт для упорядочения байтов, либо
MMилиIIв ASCII. Это говорит вам, какой порядок сначала рассмотреть все будущие байты в -- LSB или MSB. -
2 байт маркер TIFF, для Exif это
0x002A - 4 байт указатель на первый IFD
IFDs имеют одинаково простой структура:
- 2 байт для количества тегов, чтобы следовать
- n байт для самих тегов (где N = 12 * tagCount)
- 4 байт для дополнительного указателя на следующий IFD (используйте нулевое значение, если IFD не связан)
Теги имеют простое представление в 12 байт:
- 2 байт для тега ID
- 2 байты для типа данных (int8u, int16s, float и т. д.)
- 4 байт для количества значений данных указанного типа
- 4 байт для самого значения, если оно подходит, в противном случае для указателя на другое место, где могут быть найдены данные-это может быть указатель на начало другого IFD
типы данных предопределены. Например: 1 представляет 8-разрядные целые числа без знака, а 12 представляет 64-разрядные числа с плавающей точкой.
так что со всем, что вы можете идти вперед и следовать файл данных. Некоторые наблюдения:
- вы не можете прочитать данные по порядку, так как это бесплатно связать повсюду. Вы должны либо иметь случайный доступ, либо синтезировать его путем буферизации.
- все, что вы знаете на данный момент, это тег с ID
0x1234имеет 4 целых числа:{1,2,3,4}
чтобы декодировать TIFF в Exif, вам нужно применить словарь это определяет, что представляет каждый IFD и что представляет каждый идентификатор тега в этих IFDs.
в формате JPEG
большинство пользователей моей библиотеки обрабатывают файлы JPEG. Jpeg имеют совершенно другую структуру, состоящую из последовательности сегментов. Каждый сегмент имеет идентификатор и блок байтов. Exif находится в APP1 (числовое значение 0xe1) сегмент файла JPEG. После этого вы должны пропустить несколько ведущих байтов (Exif) перед тем, как MM или II это обозначает начало данных Exif в формате TIFF.
сводя все это вместе с примером
вот двоичный дамп одной из моих библиотек примеры изображений:
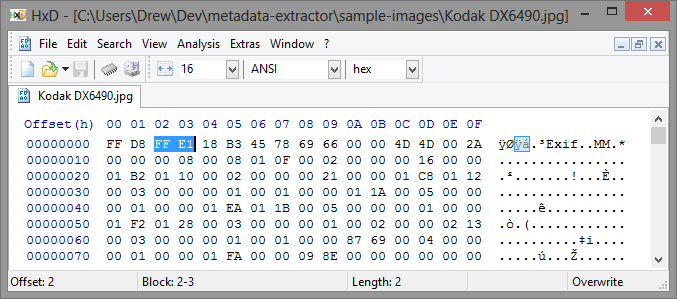
по порядку:
в формате JPEG начинается
-
FF D8- это JPEG "магическое число". -
FFотмечает начало сегмента JPEG. -
E1указывает тип сегмента JPEG (этоAPP1, где Exif живет). -
18 B3(6,323 decimal) дает длину сегмента (включая байты размера), поэтому мы знаем, что все данные Exif для этого файла JPG будут находиться в пределах следующих 6,321 байт. Обратите внимание, что в JPG многобайтовые значения кодируются с упорядочением Motorolla, хотя вложенные данные Exif могут использовать упорядочение Intel. -
45 78 69 66 00 00или в ASCIIExifявляется преамбулой Exif.APP1не является исключительно reseved для Exif, так что это различает.
TIFF / Exif запускается
-
4D 4DилиMMуказывает, что у нас есть порядок байтов Motorolla в этом блоке Exif -
00 2Aнаш стандартный маркер TIFF, как обсуждалось выше -
00 00 00 08- смещение (8 байт) к первому IFD относительно заголовка TIFF (MMв данном случае). Это указывает непосредственно на следующий байт в последовательности в этом случае, хотя он не имеет к.
IFD запускается
-
00 08Открывает наш первый IFD и говорит, что у нас будет 8 тегов
Тег Начинается
-
01 0Fявляется идентификатором для первого тега в первом IFD, в этом случае производитель камеры -
00 02- это тип значения (2 означает, что это строка ASCII) -
00 00 00 16- число деталей, поэтому мы будем иметь 22-байт строка -
00 00 01 B2(434 decimal) - указатель на расположение этой строки относительно заголовка TIFF (MM). Вы не можете увидеть его на этом скриншоте, но он указывает на45 41 53 54 4D 41 4E 20 4B 4F 44 41 4B 20 43 4F 4D 50 41 4E 59 00что этоEASTMAN KODAK COMPANYв ASCII
RAW
необработанные файлы камеры (CR2/NEF / ORW...) обычно используют TIFF, однако они в основном используют разные теги для Exif. Вторая пара байтов в этих файлах будет отличаться от 00 2A также, указывая тип TIFF словарь, который должен быть применен.
Википедия имеет несколько указателей на то, как и где именно данные EXIF хранятся в файле. Конечно, всегда есть стандартный сам читать.
Это одна из хороших библиотек для Java и EXIF:http://www.drewnoakes.com/code/exif/
довольно утомительно анализировать данные EXIF, но вы можете найти много библиотек для их анализа. Мой любимый для Java,
http://www.java2s.com/Open-Source/Java-Document/Web-Server/Jigsaw/org/w3c/tools/jpeg/Exif.java.htm